Sie können die folgende Formel verwenden, um eine Median-IF-Funktion in Google Tabellen auszuführen:
=MEDIAN(IF(GROUP_RANGE=VALUE, MEDIAN_RANGE))
Diese Formel findet den Mittelwert aller Zellen in einem bestimmten Bereich, die …
Sie können die folgende Formel verwenden, um eine Median-IF-Funktion in Google Tabellen auszuführen:
=MEDIAN(IF(GROUP_RANGE=VALUE, MEDIAN_RANGE))
Diese Formel findet den Mittelwert aller Zellen in einem bestimmten Bereich, die …
Die prozentuale Änderung der Werte zwischen einer Periode und einer anderen Periode wird wie folgt berechnet:
Prozentuale Änderung = (Wert 2 – Wert 1 ) / Wert 1 * 100
Angenommen, ein Unternehmen macht in …
Ein kumulativer Prozentsatz stellt den Gesamtprozentsatz der Werte in einem Datensatz bis zu einem bestimmten Punkt dar.
Das folgende Schritt-für-Schritt-Beispiel zeigt, wie Sie kumulierte Prozentsätze in Google Tabellen berechnen.
Eine Regressionslinie (auch Trendlinie oder Linie der besten Anpassung) ist eine Linie, die am besten zum Trend in einem bestimmten Datensatz „passt“.
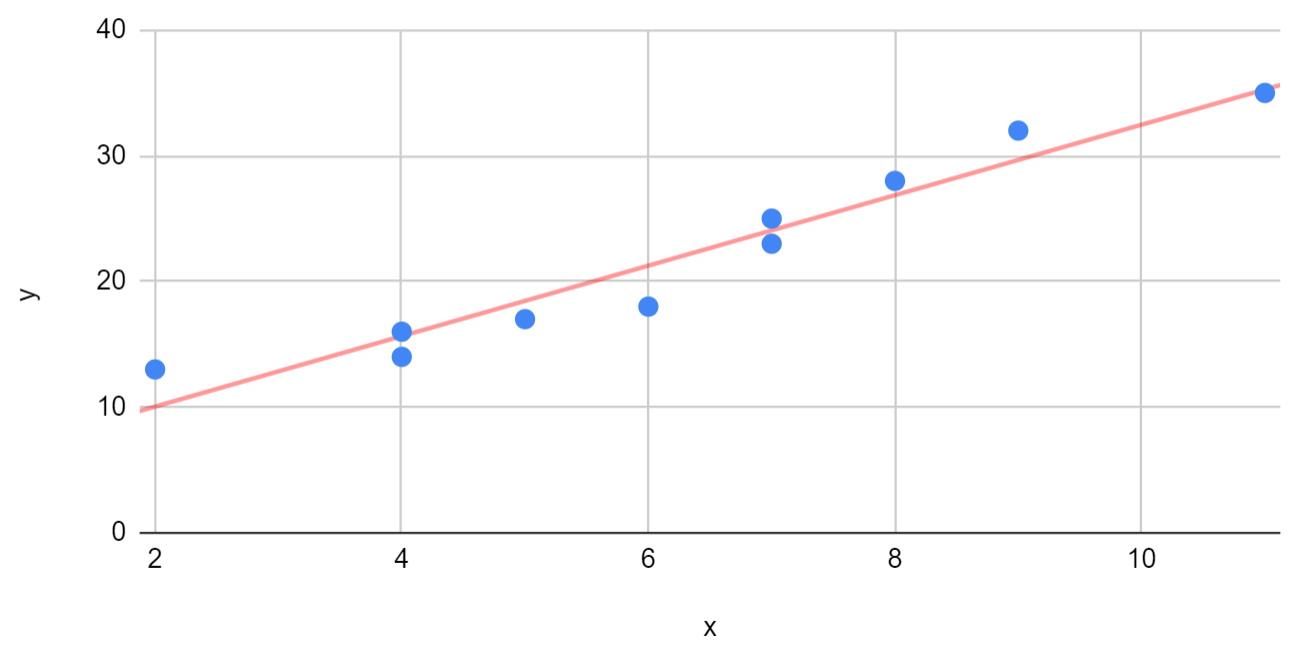
Dieses Tutorial bietet ein Schritt-für-Schritt-Beispiel zum Erstellen einer …
Ein Ausreißer ist eine Beobachtung, die ungewöhnlich weit von anderen Werten in einem Datensatz entfernt liegt.
Wir definieren eine Beobachtung häufig als Ausreißer, wenn sie um das 1,5-fache des …
In der Zeitreihenanalyse ist ein gleitender Durchschnitt einfach der Durchschnittswert einer bestimmten Anzahl früherer Perioden.
Ein exponentieller gleitender Durchschnitt ist eine Art gleitender Durchschnitt, der jüngsten Beobachtungen mehr Gewicht verleiht …
Häufig möchten Sie die Werte einiger Datensätze in Google Tabellen basierend auf einer Kategorie oder Gruppe summieren.
Nehmen wir zum Beispiel an, wir haben den folgenden Datensatz und wir möchten …
Das Akronym CAGR steht für Compound Annual Growth Rate, also die durchschnittliche annualisierte Umsatzwachstumsrate bzw. jährliche Wachstumsrate während eines bestimmten Zeitraums.
Die Formel zur Berechnung der CAGR lautet wie folgt …
In einer Häufigkeitsverteilung bezieht sich die Klassenbreite auf die Differenz zwischen den oberen und unteren Grenzen einer beliebigen Klasse oder Kategorie.
Die folgende Häufigkeitsverteilung hat beispielsweise eine Klassenbreite von 4 …
Der Antilog einer Zahl ist der Kehrwert des Logarithmus einer Zahl.
Wenn man also den Logarithmus einer Zahl berechnet, kann man den Antilogarithmus verwenden, um die ursprüngliche Zahl zurückzubekommen.
Angenommen …
Logistische Regression ist eine statistische Methode, die wir zur Anpassung eines Regressionsmodells verwenden, wenn die Antwortvariable binär ist. Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz passt …
Das Cronbachsche Alpha ist eine Möglichkeit, die interne Konsistenz eines Fragebogens oder einer Umfrage zu messen.
Das Cronbachsche Alpha liegt zwischen 0 und 1, wobei höhere Werte darauf hindeuten, dass …
R ist ausgezeichnet bei der Durchführung einer elementweisen Multiplikation zwischen zwei Objekten.
Die folgenden Beispiele zeigen, wie man eine elementweise Multiplikation zwischen verschiedenen Objekten in R durchführt.
Der Begriff univariate Analyse bezieht sich auf die Analyse einer Variablen. Sie können sich daran erinnern, dass das Präfix „uni“ „eins“ bedeutet.
Es gibt drei gängige Möglichkeiten, eine univariate Analyse …
In der linearen Algebra ist die Einheitsmatrix (oder Identitätsmatrix) eine quadratische Matrix mit Einsen auf der Hauptdiagonalen und Nullen überall sonst.
Sie können die Einheitsmatrix in R erstellen, indem Sie …
Sie können die folgende Syntax in R verwenden, um die Anzahl der Vorkommen bestimmter Werte in Spalten eines Dataframes zu zählen:
#Anzahl der Vorkommen jedes Wertes in einer Spalte zählen …Mit der Funktion nrow() können Sie die Anzahl der Zeilen in einem Dataframe in R zählen:
#Anzahl gesamt der Zeilen im Dataframe
nrow(df)
#Anzahl gesamt der Zeilen ohne NA-Werte …Sie können die folgende Syntax verwenden, um eine Matrixmultiplikation in R durchzuführen:
#Element-für-Element-Multiplikation durchführen
A * B
#Matrixmultiplikation durchführen
A %*% B
Die folgenden Beispiele zeigen, wie Sie diese Syntax in der …
In Excel bieten Pivot-Tabellen eine einfache Möglichkeit, Daten zu gruppieren und zusammenzufassen.
Wenn wir beispielsweise den folgenden Datensatz in Excel haben, können wir eine Pivot-Tabelle verwenden, um den Gesamtumsatz schnell …
Eine Punktsch#tzer stellt eine Zahl dar, die wir aus Stichprobendaten berechnen, um einen Populationsparameter zu schätzen. Dies dient als unsere bestmögliche Schätzung des wahren Populationsparameters.
Die folgende Tabelle zeigt …
In der Statistik sind Dezile Zahlen, die einen Datensatz in zehn gleich häufige Gruppen aufteilen.
Das erste Dezil ist der Punkt, an dem 10% aller Datenwerte darunter liegen. Das zweite …
Sie können die Funktionen min() und max() in R verwenden, um die minimalen und Maximume in einem Vektor schnell zu berechnen.
#Minimunm finden
min(x)
#Maximum finden
max(x)
Die …
In der Statistik sind Quantile Werte, die ein geordnetes Dataset in gleiche Gruppen unterteilen.
Die Funktion quantiile() in R kann verwendet werden, um Beispielquantile eines Datensatzes zu berechnen.
Diese Funktion …
In der Statistik sind Quantile Werte, die ein geordnetes Dataset in gleiche Gruppen unterteilen.
Um die nach einer bestimmten Variablen gruppierten Quantile in R zu berechnen, können wir die folgenden …
Mit den folgenden Funktionen können Sie Kombinationen und Permutationen in R berechnen:
#Berechnen Sie die Gesamtkombinationen der Größe r aus n Gesamtobjekten
choose(n, r)
#Berechnen Sie die Gesamtpermutationen der …Der Minkowski-Abstand zwischen zwei Vektoren A und B wird wie folgt berechnet:
(Σ|a i – b i | p ) 1/p
wobei i das i-te Element in jedem Vektor ist und …
Sie können die Funktion diff() in R verwenden, um verzögerte Differenzen zwischen aufeinanderfolgenden Elementen in Vektoren zu berechnen.
diff(x)
Die folgenden Beispiele zeigen die praktische Anwendung dieser Funktion.
Mit der Funktion dist() in R kann eine Distanzmatrix berechnet werden, die die Abstände zwischen den Zeilen einer Matrix oder eines Dataframes anzeigt.
Diese Funktion verwendet die folgende grundlegende Syntax …
Der Iris-Datensatz ist ein in R integrierter Datensatz, der Messungen zu 4 verschiedenen Attributen (in Zentimetern) für 50 Blumen von 3 verschiedenen Arten enthält.
In diesem Tutorial wird erläutert …
Die Funktion seq() in R kann verwendet werden, um eine Zahlenfolge zu generieren.
Diese Funktion verwendet die folgende grundlegende Syntax:
seq(from=1, to=1, by=1, length.out=NULL …
Quartile sind Werte, die einen Datensatz in vier gleiche Teile aufteilen.
Es gibt drei verschiedene Funktionen, mit denen Sie Quartile in Excel berechnen können:
1. QUARTILE.EXKL: Diese Funktion verwendet …
Es gibt drei verschiedene Funktionen, mit denen Sie die Varianz in Excel berechnen können:
1. VAR.P: Diese Funktion berechnet die Populationsvarianz. Verwenden Sie diese Funktion, wenn der Wertebereich die …
Das n-te Perzentil eines Datensatzes ist der Wert, der die ersten n Prozent der Datenwerte abschneidet, wenn alle Werte vom kleinsten zum größten sortiert sind.
Das 90. Perzentil eines Datasets …
Eine Box-Cox-Transformation ist eine häufig verwendete Methode zum Transformieren eines nicht normalverteilten Datensatzes in einen normalverteilten.
Die Grundidee besteht darin, mit der folgenden Formel einen Wert für λ zu finden …
Eine Arkussinus-Transformation kann verwendet werden, um Datenpunkte, die zwischen den Werten 0 und 1 liegen, zu „strecken“.
Diese Art der Transformation wird normalerweise bei Proportionen und Prozentsätzen verwendet.
Wir können …
Viele statistische Tests gehen davon aus, dass Datensätze normalverteilt sind.
Diese Annahme wird jedoch in der Praxis häufig verletzt. Eine Möglichkeit, dieses Problem zu beheben, besteht darin, die Werte des …
Sie können die folgende Formel verwenden, um eine Median-IF-Funktion in Excel auszuführen:
=MEDIAN(WENN(GRUPPE_RANGE = WERT, MEDIAN_RANGE))
Diese Formel ermittelt den Medianwert aller Zellen in einem bestimmten Bereich, die zu …
Sie können die folgende Formel verwenden, um eine Perzentil-IF-Funktion in Excel auszuführen:
=QUANTIL(WENN(GRUPPE_BEREICH=GRUPPE, WERTE_BEREICH ), k)
Diese Formel ermittelt das k-te Perzentil aller Werte, die zu einer bestimmten …
Sie können die folgende Formel verwenden, um die Anzahl der Vorkommen nach Gruppe in einer Excel-Tabelle zu zählen:
= ZÄHLENWENN(Gruppenbereich, Kriterien)
Das folgende Beispiel zeigt die praktische Anwendung dieser Formel …
Sie können die folgende einfache Formel verwenden, um die Summe der Werte nach Gruppen in einer Excel-Tabelle zu berechnen:
=SUMMEWENN(Bereich;Suchkriterien;[Summe_Bereich])
Das folgende Beispiel zeigt die praktische Anwendung …
Oft möchten Sie vielleicht die Steigung einer Trendlinie in Excel ermitteln.
Glücklicherweise ist dies ziemlich einfach und das folgende Schritt-für-Schritt-Beispiel zeigt, wie es geht.
In der Statistik bezieht sich die gepoolte Varianz auf den Durchschnitt von zwei oder mehr Gruppenvarianzen.
Wir verwenden das Wort "gepoolt", um anzuzeigen, dass wir zwei oder mehr Gruppenvarianzen "poolen …
Die gewichtete Standardabweichung ist eine nützliche Methode, um die Streuung von Werten in einem Dataset zu messen, wenn einige Werte im Dataset höhere Gewichtungen haben als andere.
Die Formel zur …
Das Cronbachsche Alpha ist eine Möglichkeit, die interne Konsistenz eines Fragebogens oder einer Umfrage zu messen.
Das Cronbachsche Alpha liegt zwischen 0 und 1, wobei höhere Werte darauf hindeuten, dass …
Ein klasseninterner Korrelationskoeffizient (ICC) wird verwendet, um zu bestimmen, ob Items (oder Themen) von verschiedenen Bewertern zuverlässig bewertet werden können.
Der Wert eines ICC kann von 0 bis 1 reichen …
Der vom Biostatistiker Karl Pearson entwickelte Pearson-Schiefekoeffizient ist eine Möglichkeit, die Schiefe in einem Beispieldatensatz zu messen.
Es gibt eigentlich zwei Methoden, die verwendet werden können, um den Schiefe-Koeffizienten nach …
Winsorizing bedeuted, extreme Ausreisser gleich eines angegebenens Perzentils zu setzen.
Ein Winsorizing von 90% setzt beispielsweise alle Beobachtungen, die größer als das 95. Perzentil sind, gleich dem Wert des 95 …
Die Wahrscheinlichkeit beschreibt wie wahrscheinlich es ist, dass ein Ereignis eintritt.
Wir können Wahrscheinlichkeiten in Excel berechnen, indem wir die WAHRSCHBEREICH- Funktion verwenden, die die folgende Syntax verwendet:
WAHRSCHBEREICH(Beob_Werte …
Das 90. Perzentil eines Datasets ist der Wert, der die unteren 90 Prozent der Datenwerte von den oberen 10 Prozent der Datenwerte abschneidet, wenn alle Werte vom kleinsten zum größten …
Fleiss' Kappa ist eine Möglichkeit, den Grad der Übereinstimmung zwischen drei oder mehr Bewertern zu messen, wenn die Bewerter einem Satz von Items kategoriale Bewertungen zuweisen.
Fleiss' Kappa reicht von …
Die punktbiseriale Korrelation wird verwendet, um die Beziehung zwischen einer binären Variablen x und einer kontinuierlichen Variablen y zu messen.
Ähnlich wie der Korrelationskoeffizient nach Pearson nimmt die punktbiseriale Korrelationskoeffizient …
Oft möchten Sie möglicherweise einen kumulativen Prozentsatz eines Datensatzes berechnen. Glücklicherweise ist dies mit den integrierten Funktionen in Excel einfach.
Das folgende Schritt-für-Schritt-Beispiel zeigt, wie kumulierte Prozentsätze in Excel berechnet …
In der Statistik verwenden wir häufig denKorrelationskoeffizienten nach Pearson, um die lineare Beziehung zwischen zwei Variablen zu messen. Manchmal sind wir jedoch daran interessiert, die Beziehung zwischen zwei Variablen …
Der Satz von Bayes besagt für zwei beliebige Ereignisse A und B Folgendes:
P(A|B) = P(A)*P(B|A) / P(B)
wo:
Kosinusähnlichkeit ist ein Maß für die Ähnlichkeit zwischen zwei Vektoren eines inneren Produktraums.
Für zwei Vektoren, A und B, wird die Kosinus-Ähnlichkeit wie folgt berechnet:
Kosinusähnlichkeit = & Sgr; A i b …
Häufigkeiten geben an, wie oft unterschiedliche Werte in einem Datensatz vorkommen.
Wir können Häufigkeiten in Google Tabellen leicht berechnen, indem wir die Funktion FREQUENCY() verwenden, die die folgende Syntax hat …
Die Kovarianz ist ein Maß dafür, wie Änderungen einer Variablen mit Änderungen einer zweiten Variablen verbunden sind. Insbesondere ist es ein Maß für den Grad, in dem zwei Variablen linear …
In der Statistik bezieht sich Korrelation auf die Stärke und Richtung einer Beziehung zwischen zwei Variablen. Der Wert eines Korrelationskoeffizienten kann von -1 bis 1 reichen, mit den folgenden Interpretationen …
Mit dem Standardfehler des arithmetischen Mittels lässt sich messen, wie die Werte in einem Dataset verteilt sind. Es wird berechnet als:
Standardfehler = s / √n
wo:
Ein Variationskoeffizient, oft abgekürzt als CV, ist eine Möglichkeit zu messen, wie die Streuung von Werten in einem Datensatz relativ zum Mittelwert ist. Es wird berechnet als:
CV = σ / μ …
Eine Fünf-Punkte-Zusammenfassung ist eine Möglichkeit, ein Datensatz mit den folgenden fünf Werten zusammenzufassen:
Die Fünf-Punkte-Zusammenfassung ist nützlich, da …
In der Statistik sagt uns ein Z-Wert, wie viele Standardabweichungen ein Wert vom Mittelwert entfernt ist. Wir verwenden die folgende Formel, um einen Z-Wert zu berechnen:
z = (X – μ) / σ …
Der Interquartilsabstand, oft bezeichnet IQR, ist ein Weg, um die Ausbreitung des mittleren 50% eines Datensatz zu messen. Er wird als Differenz zwischen dem ersten Quartil (Q1) und dem dritten …
In diesem Tutorial wird erläutert, wie Sie das Punktprodukt in Google Tabellen berechnen.
Bei gegebenem Vektor a = [a 1, a 2, a 3 ] und Vektor b …
Eine Möglichkeit, die Beziehung zwischen zwei Variablen zu quantifizieren, besteht darin, den Korrelationskoeffizienten nach Pearson zu verwenden, der ein Maß für den linearen Zusammenhang zwischen zwei Variablen ist . Es hat …
Das Mittel eines Datensatzes wird wie folgt berechnet:
Mittel = (größter Wert + kleinster Wert) / 2
Dieser Wert ist einfach der Durchschnitt der größten und kleinsten Werte im Datensatz und gibt uns …
In der Statistik sind Schiefe und Kurtosis zwei Möglichkeiten, die Form einer Verteilung zu messen.
Die Schiefe ist ein Maß für die Asymmetrie einer Verteilung. Dieser Wert kann positiv oder …
Die mittlere absolute Abweichung ist eine Möglichkeit, die Streuung für einen Satz von Datenwerten zu messen.
Ein niedriger Wert für die mittlere absolute Abweichung ist ein Hinweis darauf, dass die …
Um einen Satz von Datenwerten zu normalisieren, müssen die Werte so skaliert werden, dass der Mittelwert aller Werte 0 und die Standardabweichung 1 ist.
In diesem Tutorial wird erläutert, wie …
Eine Pivot-Tabelle ist ein Tabellentyp, der ein Dataset mithilfe von Zusammenfassungsstatistiken zusammenfasst.
Wir können Pivot-Tabellen in Python erstellen, indem wir die Funktion pivot_table aus dem Pandas-Paket verwenden, die die folgende …
Der Standardfehler des Mittelwerts ist eine Möglichkeit zu messen, wie verteilt die Werte in einem Datensatz sind. Es wird berechnet als:
Standardfehler des Mittelwerts = s / √n
wo:
Eine Häufigkeitstabelle ist eine Tabelle, in der die Häufigkeiten verschiedener Kategorien angezeigt werden. Dieser Tabellentyp ist besonders nützlich, um die Verteilung von Werten in einem Dataset zu verstehen.
In diesem …
In der Statistik wird beim Binning numerische Werte in Bins platziert.
Die häufigste Form des Binning ist das Binning gleicher Breite, bei dem wir einen Datensatz in k Bins gleicher …
Cramers V ist ein Maß für die Assoziationsstärke zwischen zwei nominalen Variablen.
Es reicht von 0 bis 1, wobei:
Eine Box-Cox-Transformation ist eine häufig verwendete Methode zum Transformieren eines nicht normalverteilten Datensatzes in einen normalverteilten.
Die Grundidee hinter dieser Methode besteht darin, einen Wert für λ zu finden, so …
Der Mahalanobis-Abstand ist der Abstand zwischen zwei Punkten in einem multivariaten Raum. Es wird häufig verwendet, um Ausreißer in statistischen Analysen zu finden, die mehrere Variablen umfassen.
In diesem Tutorial …
Der Levenshtein-Distanz zwischen zwei Zeichenfolgen ist die Mindestanzahl von Einzelzeichenänderungen, die erforderlich sind, um ein Wort in das andere umzuwandeln.
Das Wort "Einzelzeichenänderungen" umfasst dabei Ersetzungen, Einfügungen und Löschungen.
Angenommen …
Ein Variationskoeffizient, oft als CV abgekürzt, ist eine Methode, um zu messen, wie verteilt Werte in einem Datensatz relativ zum Mittelwert sind. Es wird berechnet als:
CV = σ / μ
wo …
In der Statistik sind Schiefe und Kurtosis zwei Möglichkeiten, um die Form einer Verteilung zu messen.
Die Schiefe ist ein Maß für die Asymmetrie einer Verteilung. Dieser Wert kann positiv …
Die Kosinus-Ähnlichkeit ist ein Maß für die Ähnlichkeit zwischen zwei Vektoren eines inneren Produktraums.
Für zwei Vektoren, A und B, wird die Kosinus-Ähnlichkeit wie folgt berechnet:
Kosinus-Ähnlichkeit = ΣAiB …
Der euklidische Abstand zwischen zwei Vektoren A und B wird berechnet als:
Euklidischer Abstand = √ Σ (A i - B i ) 2
Um den euklidischen Abstand zwischen zwei Vektoren in Python zu …
Das n-te Perzentil eines Datensatzes ist der Wert, der die ersten n Prozent der Datenwerte abschneidet, wenn alle Werte vom kleinsten zum größten sortiert sind.
Das 90. Perzentil eines Datasets …
Der Hamming-Abstand zwischen zwei Vektoren ist einfach die Summe der entsprechenden Elemente, die sich zwischen den Vektoren unterscheiden.
Angenommen, wir haben die folgenden zwei Vektoren:
x = [1, 2, 3, 4 …Der Interquartilsabstand, oft bezeichnet „IQR“ (engl. interquartile range), ist ein Weg, um die Ausbreitung des mittleren 50% eines Datensatz zu messen. Sie wird als Differenz zwischen dem ersten Quartil * (dem …
Der Levenshtein-Abstand zwischen zwei Zeichenfolgen ist die Mindestanzahl von Einzelzeichenänderungen, die erforderlich sind, um ein Wort in das andere umzuwandeln.
Das Wort "Änderungen" umfasst Ersetzungen, Einfügungen und Löschungen.
Angenommen, wir …
Der euklidische Abstand zwischen zwei Vektoren A und B wird berechnet als:
Euklidischer Abstand = √ Σ (A i - B i ) 2
Um den euklidischen Abstand zwischen zwei Vektoren in R zu …
Die Autokorrelation misst den Ähnlichkeitsgrad zwischen einer Zeitreihe und einer verzögerten Version von sich selbst über aufeinanderfolgende Zeitintervalle.
Es wird manchmal auch als "serielle Korrelation" oder "verzögerte Korrelation" bezeichnet, da …
Bootstrapping ist eine Methode, mit der der Standardfehler einer Statistik geschätzt und ein Konfidenzintervall für die Statistik erstellt werden kann.
Der grundlegende Prozess für das Bootstrapping ist wie folgt:
Eine Häufigkeitstabelle ist eine Tabelle, in der die Häufigkeiten verschiedener Kategorien angezeigt werden. Diese Art von Tabelle ist besonders nützlich, um die Verteilung von Werten in einem Dataset zu verstehen …
Der Jaccard-Koeffizient misst die Ähnlichkeit zwischen zwei Datensätzen. Er kann zwischen 0 und 1 liegen. Je höher die Zahl, desto ähnlicher sind die beiden Datensätze.
Der Jaccard-Koeffizient wird berechnet als …
Die Kovarianz ist ein Maß dafür, wie Änderungen in einer Variablen mit Änderungen in einer zweiten Variablen verbunden sind. Insbesondere ist dies ein Maß für den Grad, in dem zwei …
Mit der Funktion cumsum() aus Basis R können Sie die kumulative Summe eines Vektors numerischer Werte einfach berechnen.
In diesem Tutorial wird erläutert, wie Sie mit dieser Funktion die kumulative …
Der Mahalanobis-Abstand ist der Abstand zwischen zwei Punkten in einem multivariaten Raum. Es wird häufig verwendet, um Ausreißer in statistischen Analysen zu finden, die mehrere Variablen umfassen.
In diesem Tutorial …
Der Manhattan-Distanz zwischen zwei Vektoren, A und B, wird wie folgt berechnet:
Σ | a i - b i |
Dabei ist i das i-te Element in jedem Vektor.
Diese Distanz wird verwendet …
Oft möchten Sie den Durchschnitt der Werte über mehrere Zeilen in R berechnen. Glücklicherweise ist dies mit der Funktion rowMeans() einfach zu bewerkstelligen.
Dieses Tutorial zeigt einige Beispiele für die …
Oft möchten Sie den Mittelwert nach Gruppen in R berechnen. Es gibt drei Methoden, mit denen Sie dies tun können:
Methode 1: Verwenden Sie Base R
aggregate(df$col_to_aggregate, list …In der Statistik verwenden wir häufig den Pearson-Korrelationskoeffizienten, um die lineare Beziehung zwischen zwei Variablen zu messen. Manchmal sind wir jedoch daran interessiert, die Beziehung zwischen zwei Variablen zu verstehen …
Quartile sind Werte, die einen Datensatz in vier gleiche Teile aufteilen.
Rollierende Korrelationen sind Korrelationen zwischen zwei Zeitreihen in einem rollierenden Fenster. Ein Vorteil dieser Art von Korrelation besteht darin, dass Sie die Korrelation zwischen zwei Zeitreihen über die Zeit visualisieren …
In der Statistik sind Schiefe und Kurtosis zwei Möglichkeiten, um die Form einer Verteilung zu messen.
Die Schiefe ist ein Maß für die Asymmetrie einer Verteilung. Dieser Wert kann positiv …
Die Spannweite ist die Differenz zwischen dem größten und dem kleinsten Wert in einem Datensatz.
Wir können die folgende Syntax verwenden, um die Spannweite eines Datensatzes in R zu ermitteln …
Die Varianz ist ein Weg, um zu messen, wie verteilt die Datenwerte um den Mittelwert liegen.
Die Formel zum Ermitteln der Varianz einer Population lautet:
σ 2 = Σ (x i …
Ein Ausreißer ist eine Beobachtung, die ungewöhnlich weit von anderen Werten in einem Datensatz entfernt ist. Ausreißer können problematisch sein, da sie die Ergebnisse einer Analyse beeinflussen können.
In diesem …
Die Kosinusähnlichkeit ist ein Maß für die Ähnlichkeit zwischen zwei Vektoren eines inneren Produktraums.
Für zwei Vektoren, A und B, wird die Kosinusähnlichkeit wie folgt berechnet:
Kosinusähnlichkeit = & Sgr; A i …
Oft möchten Sie den Mittelwert mehrerer Spalten in R berechnen. Glücklicherweise können Sie dies einfach mit der Funktion colMeans() tun.
colMeans(df)
Die folgenden Beispiele zeigen, wie diese Funktion in …
In der Statistik gibt ein Z-Score an, wie viele Standardabweichungen ein Wert vom Mittelwert entfernt ist. Wir verwenden die folgende Formel, um einen Z-Score zu berechnen:
z = (X - μ) / σ …
Oft möchten Sie möglicherweise die Summe eines bestimmten Satzes von Spalten in einem Dataframe in R finden. Glücklicherweise ist dies mit der Funktion rowSums() einfach zu bewerkstelligen.
Dieses Tutorial zeigt …
Oft möchten Sie möglicherweise nur die Anzahl der Zeilen in einem R-Dataframe zählen, die bestimmte Kriterien erfüllen. Glücklicherweise ist dies mit der folgenden grundlegenden Syntax einfach zu bewerkstelligen:
sum(df …Die Punktbiseriale Korrelation wird verwendet, um die Beziehung zwischen einer binären Variablen x und einer kontinuierlichen Variablen y zu messen.
Ähnlich wie der Pearson-Korrelationskoeffizient nimmt der Punktbiseriale Korrelationskoeffizient einen Wert …
Der Hamming-Abstand zwischen zwei Vektoren ist einfach die Summe der entsprechenden Elemente, die sich zwischen den Vektoren unterscheiden.
Angenommen, wir haben die folgenden zwei Vektoren:
x = [1, 2, 3, 4 …Bei gegebenem Vektor a = [a 1 , a 2 , a 3 ] und Vektor b = [b 1 , b 2 , b 3 ] ist das als a · b bezeichnete Skalarprodukt von Vektor a und …
Ein Konfidenzintervall ist ein Wertebereich, der wahrscheinlich einen Populationsparameter mit einem bestimmten Konfidenzniveau enthält.
Sie wird nach folgender allgemeiner Formel berechnet:
Konfidenzintervall = (Punktschätzung) +/- (kritischer Wert) * (Standardfehler)
Diese Formel erstellt ein …
Der Standardfehler des Mittelwerts ist eine Möglichkeit zu messen, wie verteilt die Werte in einem Datensatz sind. Es wird berechnet als:
Standardfehler = s / √n
wo:
Der euklidische Abstand zwischen zwei Vektoren A und B wird berechnet als:
Euklidischer Abstand = √ Σ (A i - B i ) 2
wo:
Der Hamming-Abstand zwischen zwei Vektoren ist einfach die Summe der entsprechenden Elemente, die sich zwischen den Vektoren unterscheiden.
Angenommen, wir haben die folgenden zwei Vektoren:
Der Hamming-Abstand zwischen den beiden …
Es gibt drei verschiedene Funktionen, mit denen Sie die Standardabweichung in Excel berechnen können:
Diese Funktion berechnet die Populationsstandardabweichung. Verwenden Sie diese Funktion, wenn der Wertebereich die …
Eine Zusammenfassung mit fünf Zahlen ist eine Möglichkeit, einen Datensatz mit den folgenden fünf Werten zusammenzufassen:
Die Zusammenfassung …
Die Schiefe ist ein Maß für die Asymmetrie eines Datensatzes oder einer Verteilung. Dieser Wert kann positiv oder negativ sein. Es ist nützlich zu wissen, weil es uns hilft, die …
Ein Ausreißer ist eine Beobachtung, die ungewöhnlich weit von anderen Werten in einem Datensatz entfernt ist. Ausreißer können problematisch sein, da sie die Ergebnisse einer Analyse beeinflussen können.
Wir werden …
Die relative Standardabweichung ist ein Maß für die Standardabweichung der Stichprobe relativ zum Stichprobenmittelwert für einen bestimmten Datensatz.
Es wird berechnet als:
Relative Standardabweichung = s / x * 100%
wo:
In diesem Artikel wird erläutert, wie Sie den Interquartilsabstand eines Datensatzes in Excel berechnen.
Der Interquartilsabstand, oft bezeichnet IQB, ist ein Weg, um die Ausbreitung des …
Eine Frequenztabelle ist eine Tabelle, in der Informationen zu Frequenzen angezeigt werden. Frequenzen sagen uns einfach, wie oft ein bestimmtes Ereignis aufgetreten ist.
Die folgende Tabelle zeigt beispielsweise, wie viele …
In einer Häufigkeitsverteilung bezieht sich die Klassenbreite auf den Unterschied zwischen der oberen und unteren Grenze einer Klasse oder Kategorie.
Die folgende Häufigkeitsverteilung hat beispielsweise eine Klassenbreite von 4:
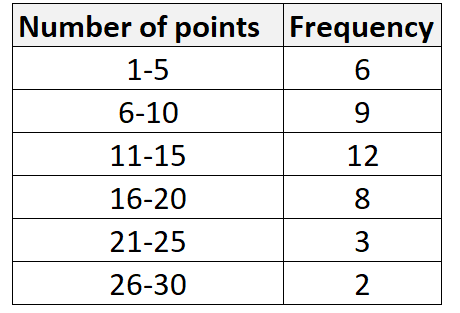
Z …
Eine Frequenztabelle ist eine Tabelle, in der Informationen zu Frequenzen angezeigt werden. Frequenzen sagen uns einfach, wie oft ein bestimmtes Ereignis aufgetreten ist.
Für Blutzuckerwer le, die folgende Tabelle zeigt …
In der Statistik sind Dezile Zahlen, die einen Datensatz in zehn Gruppen gleicher Häufigkeit aufteilen.
Das erste Dezil ist der Punkt, an dem 10% aller Datenwerte darunter liegen. Das zweite …
Der Mittelwert repräsentiert den Durchschnittswert in einem Datensatz. Es gibt uns eine gute Vorstellung davon, wo sich das Zentrum eines Datensatzes befindet.
Die Standardabweichung gibt an, wie verteilt die Werte …
In der Statistik gibt ein z-Wert an, wie viele Standardabweichungen ein Wert vom Mittelwert entfernt ist. Wir verwenden die folgende Formel, um einen z-Wert zu berechnen:
z = (X – μ) / σ …
Ein Variationskoeffizient (auch: Abweichungskoeffizient), ist eine Möglichkeit zu messen, wie verteilt Werte in einem Datensatz relativ zum Mittelwert sind. Es wird berechnet als:
VarK = σ / μ
wobei:
In der Statistik bezieht sich die Korrelation auf die Stärke und Richtung einer Beziehung zwischen zwei Variablen. Der Wert eines Korrelationskoeffizienten kann mit den folgenden Interpretationen zwischen -1 und 1 …
Ein Ausreißer ist eine Beobachtung, die ungewöhnlich weit von anderen Werten in einem Datensatz entfernt ist. Ausreißer können problematisch sein, da sie die Ergebnisse einer Analyse beeinflussen können.
In diesem …
Um einen Satz von Datenwerten zu „normalisieren“, müssen die Werte so skaliert werden, dass der Mittelwert aller Werte 0 und die Standardabweichung 1 ist.
In diesem Tutorial wird erklärt, wie …
In diesem Tutorial wird erklärt, wie das Skalarprodukt in Excel berechnet wird.
Bei gegebenem Vektor a = [a 1 , a 2 , a 3 ] und Vektor b = [b …
Das n-te Perzentil eines Datensatzes ist der Wert, der die ersten n Prozent der Datenwerte abschneidet, wenn alle Werte vom kleinsten zum größten sortiert sind.
Das 90. Perzentil eines Datasets …
Eine Pivot-Tabelle ist ein Tabellentyp, der ein Dataset mithilfe von Zusammenfassungsstatistiken zusammenfasst.
Wir können Pivot-Tabellen in Python erstellen, indem wir die Funktion pivot_table aus dem Pandas-Paket verwenden, die die folgende …
In der Statistik verwenden wir häufig den Pearson-Korrelationskoeffizienten, um die lineare Beziehung zwischen zwei Variablen zu messen. Manchmal sind wir jedoch daran interessiert, die Beziehung zwischen zwei Variablen zu verstehen …
Ein Ausreißer ist eine Beobachtung, die ungewöhnlich weit von anderen Werten in einem Datensatz entfernt ist. Ausreißer können problematisch sein, da sie die Ergebnisse einer Analyse beeinflussen können.
In diesem …
Der Jaccard-Index oder Jaccard-Koeffizient misst die Ähnlichkeit zwischen zwei DatenDatensätzen. Sie kann zwischen 0 und 1 liegen. Je höher die Zahl, desto ähnlicher sind die beiden Datensätze.
Der Jaccard-Koeffizient wird …
In der Statistik sind wir häufig daran interessiert zu verstehen, wie ein Datensatz verteilt ist. Insbesondere sind vier Dinge hilfreich, die Sie über eine Distribution wissen sollten:
1. Form
In der Statistik sind wir häufig daran interessiert, einen Populationsparameter anhand einer Stichprobe zu schätzen. Zum Beispiel möchten wir vielleicht die mittlere Größe der Schüler einer bestimmten Schule wissen. Wenn …
Die Kovarianz ist ein Maß dafür, wie Änderungen in einer Variablen mit Änderungen in einer zweiten Variablen verbunden sind. Insbesondere ist dies ein Maß für den Grad, in dem zwei …
Eine Möglichkeit, die Beziehung zwischen zwei Variablen zu quantifizieren, besteht darin, den Pearson-Korrelationskoeffizienten zu verwenden, der ein Maß für die lineare Assoziation zwischen zwei Variablen ist . Es nimmt einen Wert …
In der Statistik verwenden wir häufig den Pearson-Korrelationskoeffizienten, um die lineare Beziehung zwischen zwei Variablen zu messen. Manchmal sind wir jedoch daran interessiert, die Beziehung zwischen zwei Variablen zu verstehen …
Eine Möglichkeit, die Beziehung zwischen zwei Variablen zu quantifizieren, besteht darin, den Pearson-Korrelationskoeffizienten zu verwenden, der ein Maß für die lineare Assoziation zwischen zwei Variablen ist . Es nimmt immer einen …
In der Statistik bezieht sich die Korrelation auf die Stärke und Richtung einer Beziehung zwischen zwei Variablen. Der Wert eines Korrelationskoeffizienten kann im Bereich von -1 bis 1 liegen, wobei …
Die bedingte Wahrscheinlichkeit, dass Ereignis A auftritt, wenn Ereignis B aufgetreten ist, wird wie folgt berechnet:
P(A | B) = P(A∩B) / P(B)
wobei:
In einem Experiment gibt es zwei Hauptvariablen:
Die unabhängige Variable: Die Variable, die ein Experimentator ändert oder steuert, damit er die Auswirkungen auf die abhängige Variable beobachten kann.
Die abhängige …
In der Statistik sind wir oft daran interessiert zu wissen, wie „verteilt“ die Werte in einer Verteilung sind.
Eine beliebte Methode zur Messung der Streuung ist der Interquartilsabstand, der als …
Die Kovarianz ist ein Maß dafür, wie Änderungen in einer Variablen mit Änderungen in einer zweiten Variablen verbunden sind. Insbesondere ist dies ein Maß für den Grad, in dem zwei …
Eine Überlebenskurve ist ein Diagramm, das den Anteil einer Bevölkerung zeigt, die nach einem bestimmten Alter oder zu einem bestimmten Zeitpunkt nach einer Krankheit noch am Leben ist.
Dieses Tutorial …
Wenn wir einen Datensatz analysieren, kümmern wir uns oft um zwei Dinge:
1. Wo sich der Mittelwert befindet. Wir messen das „Zentrum“ oft anhand des Mittelwerts und des Medians.
2 …
Eine Häufigkeitstabelle ist eine Tabelle, in der die Häufigkeiten verschiedener Kategorien angezeigt werden. Diese Art von Tabelle ist besonders nützlich, um die Verteilung von Werten in einem Dataset zu verstehen …
Ein z-Score gibt an, wie viele Standardabweichungen ein bestimmter Wert vom Mittelwert entfernt ist. Der z-Wert eines bestimmten Wertes wird berechnet als:
z-Score = (x – μ) / σ
wo:
Der beste Weg, um einen Datensatz zu verstehen, besteht darin, beschreibende Statistiken für die Variablen innerhalb des Datensatzes zu berechnen. Es gibt drei gängige Formen der deskriptiven Statistik:
Eine Möglichkeit, die Beziehung zwischen zwei Variablen zu quantifizieren, besteht darin, den Pearson-Korrelationskoeffizienten zu verwenden, der ein Maß für die lineare Assoziation zwischen zwei Variablen ist. Es nimmt immer einen …
Wenn wir einen Datensatz analysieren, kümmern wir uns oft um zwei Dinge:
In der Statistik wird Kurtosis verwendet, um die Form einer Wahrscheinlichkeitsverteilung zu beschreiben.
Insbesondere wird angegeben, inwieweit sich Datenwerte in den Endpunkten oder in der Spitze einer Verteilung sammeln.
Die …
In der Statistik ist der Mittelwert eines Datensatzes der Durchschnittswert. Es ist nützlich zu wissen, weil es uns eine Vorstellung davon gibt, wo sich das „Zentrum“ des Datensatzes befindet. Es …
Ein Maß für die zentrale Tendenz ist ein einzelner Wert, der den Mittelpunkt eines Datensatzes darstellt. Dieser Wert kann auch als „zentraler Ort“ eines Datensatzes bezeichnet werden.
In der Statistik …
"Statistik in Excel leicht gemacht" ist eine Sammlung von 16 Excel-Tabellen, die integrierte Formeln enthalten, um die wichtigsten statistischen Tests und Funktionen durchzuführen.

Statologie ist eine Website, die das Erlernen von Statistik erleichtert. Wir bei Statologie glauben, dass Statistik ein unglaublich nützliches Feld ist, viele aber von den verwirrenden Notationen und komplizierten Formeln eingeschüchtert werden.
Aus diesem Grund widmen wir uns dem Unterrichten auf einfache und unkomplizierte Weise - anhand von Beispielen, Abbildungen und Praxisnähe können wir Konzepte auf eine Weise erklären, die tatsächlich Sinn macht.