
Sie können die folgende Formel verwenden, um eine Median-IF-Funktion in Google Tabellen auszuführen:
=MEDIAN(IF(GROUP_RANGE=VALUE, MEDIAN_RANGE))
Diese Formel findet den Mittelwert aller Zellen in einem bestimmten Bereich, die …
Eine Box-Cox-Transformation ist eine häufig verwendete Methode zum Transformieren eines nicht normalverteilten Datensatzes in einen normalverteilten.
Die Grundidee hinter dieser Methode besteht darin, einen Wert für λ zu finden, so dass die transformierten Daten unter Verwendung der folgenden Formel so nahe wie möglich an der Normalverteilung liegen:
Wir können eine Box-Cox-Transformation in Python mithilfe der Funktion scipy.stats.boxcox() durchführen.
Das folgende Beispiel zeigt, wie diese Funktion in der Praxis verwendet wird.
Angenommen, wir generieren eine zufällige Menge von 1.000 Werten, die aus einer Exponentialverteilung stammen:
# notwendige Pakete laden
import numpy as np
from scipy.stats import boxcox
import seaborn as sns
#Machen Sie dieses Beispiel reproduzierbar
np.random.seed(0)
# Datensatz generieren
data = np.random.exponential(size=1000)
# Zeichnen Sie die Verteilung der Datenwerte
sns.distplot(data, hist=False, kde=True)

Wir können sehen, dass die Verteilung nicht normal zu sein scheint.
Wir können die boxcox()-Funktion verwenden, um einen optimalen Lambda-Wert zu finden, der eine normalere Verteilung erzeugt:
# Box-Cox-Transformation für Originaldaten durchführen
transformed_data, best_lambda = boxcox(data)
# Zeichnen Sie die Verteilung der transformierten Datenwerte
sns.distplot(transformed_data, hist=False, kde=True)
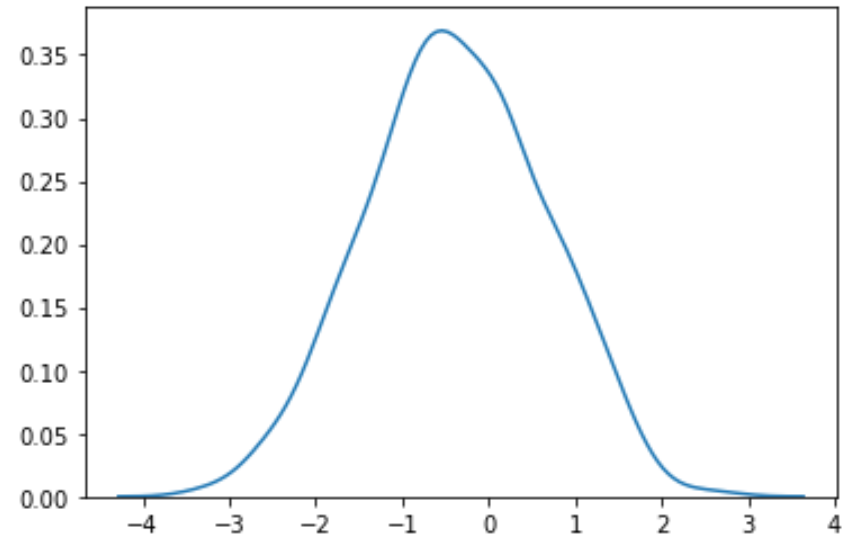
Wir können sehen, dass die transformierten Daten viel mehr einer Normalverteilung folgen.
Wir können auch den genauen Lambda-Wert finden, der zur Durchführung der Box-Cox-Transformation verwendet wird:
# optimalen Lambda-Wert anzeigen
print(best_lambda)
0.2420131978174143
Das optimale Lambda betrug ungefähr 0,242.
Somit wurde jeder Datenwert unter Verwendung der folgenden Gleichung transformiert:
Neu = (alt 0,242 - 1) / 0,242
Wir können dies bestätigen, indem wir die Werte aus den Originaldaten im Vergleich zu den transformierten Daten betrachten:
# Die ersten fünf Werte des Originaldatensatzes anzeigen
data[0:5]
array([0.79587451, 1.25593076, 0.92322315, 0.78720115, 0.55104849])
# Die ersten fünf Werte des transformierten Datensatzes anzeigen
transformed_data[0:5]
array([-0.22212062, 0.23427768, -0.07911706, -0.23247555, -0.55495228])
Der erste Wert im Originaldatensatz war 0,79587. Daher haben wir die folgende Formel angewendet, um diesen Wert zu transformieren:
New = (0,79587 ,242-1) / 0,242 = -0,222
Wir können bestätigen, dass der erste Wert im transformierten Datensatz tatsächlich -0,222 ist.
So erstellen und interpretieren Sie ein QQ-Diagramm in Python
So führen Sie einen Shapiro-Wilk-Test auf Normalität in Python durch
Sie können die folgende Formel verwenden, um eine Median-IF-Funktion in Google Tabellen auszuführen:
=MEDIAN(IF(GROUP_RANGE=VALUE, MEDIAN_RANGE))
Diese Formel findet den Mittelwert aller Zellen in einem bestimmten Bereich, die …
Die prozentuale Änderung der Werte zwischen einer Periode und einer anderen Periode wird wie folgt berechnet:
Prozentuale Änderung = (Wert 2 – Wert 1 ) / Wert 1 * 100
Angenommen, ein Unternehmen macht in …