Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …
Bei der Verwendung von Klassifizierungsmodellen beim maschinellen Lernen ist eine gängige Metrik, die wir verwenden, um die Qualität des Modells zu bewerten, der F1-Score.
Diese Metrik wird wie folgt berechnet …
In der Statistik enthalten die Datensätze, mit denen wir arbeiten, häufig kategoriale Variablen.
Dies sind Variablen, die Namen oder Bezeichnungen annehmen. Beispiele beinhalten:
Ein Likelihood-Quotienten-Test vergleicht die Anpassungsgüte zweier verschachtelter Regressionsmodelle .
Ein verschachteltes Modell ist einfach eines, das eine Teilmenge der Prädiktorvariablen im gesamten Regressionsmodell enthält.
Angenommen, wir haben das folgende Regressionsmodell mit …
Die One-Hot-Kodierung wird verwendet, um kategoriale Variablen in ein Format zu konvertieren, das von maschinellen Lernalgorithmen problemlos verwendet werden kann.
Die Grundidee der One-Hot-Kodierung besteht darin, neue Variablen zu erstellen …
Ausgewogene Genauigkeit (engl. balanced accuracy) ist eine Metrik, die wir verwenden können, um die Leistung eines Klassifizierungsmodells zu bewerten.
Es wird berechnet als:
Ausgewogene Genauigkeit = (Sensitivität + Spezifität) / 2
wo:
Die exponentielle Regression ist eine Art der Regression, die verwendet werden kann, um die folgenden Situationen zu modellieren:
1. Exponentielles Wachstum: Das Wachstum beginnt langsam und beschleunigt sich dann ohne …
Die logarithmische Regression ist eine Art der Regression, die verwendet wird, um Situationen zu modellieren, in denen Wachstum oder Verfall sich zunächst schnell beschleunigen und dann im Laufe der Zeit …
Das Bayes'sche Informationskriterium, oft abgekürzt BIC (engl. Bayes information criterium), ist eine Metrik, die verwendet wird, um die Anpassungsgüte verschiedener Regressionsmodelle zu vergleichen.
In der Praxis passen wir mehrere Regressionsmodelle …
Der Matthews-Korrelationskoeffizient (MCC, engl. Matthews correlation coefficient) ist eine Metrik, die wir verwenden können, um die Leistung eines Klassifizierungsmodells zu bewerten.
Es wird berechnet als:
MCC = (TP*TN – FP*FN …
Die logistische Regression ist eine Art von Regression, die wir verwenden können, wenn die Antwortvariable binär ist.
Eine gängige Methode zur Bewertung der Qualität eines logistischen Regressionsmodells besteht darin, eine …
Die Regressionsanalyse wird verwendet, um die Beziehung zwischen einer oder mehreren Prädiktorvariablen und einer Antwortvariablen zu quantifizieren.
Die häufigste Art der Regressionsanalyse ist die einfache lineare Regression, die verwendet wird …
In der Statistik ist die Regressionsanalyse eine Technik, die verwendet werden kann, um die Beziehung zwischen Prädiktorvariablen und einer Antwortvariablen zu analysieren. Wenn Sie Software (wie R, Stata, SPSS usw …
Ein Residuum ist die Differenz zwischen einem beobachteten Wert und einem vorhergesagten Wert in der Regressionsanalyse.
Es wird berechnet als:
Residuum = Beobachteter Wert – Vorhergesagter Wert
Denken Sie daran, dass das …
Eine der wichtigsten Annahmen der linearen Regression besteht darin, dass die Residuen auf jeder Ebene der Prädiktorvariablen mit gleicher Varianz verteilt werden. Diese Annahme wird als Homoskedastizität bezeichnet.
Wenn diese …
Ein partieller F-Test wird verwendet, um zu bestimmen, ob ein statistisch signifikanter Unterschied zwischen einem Regressionsmodell und einer verschachtelten Version desselben Modells besteht.
Ein verschachteltes Modell ist einfach eines, das …
Wir verwenden oft drei verschiedene Quadratsummenwerte, um zu messen, wie gut eine Regressionslinie tatsächlich zu einem Datensatz passt:
1. Totale Quadratsumme (SST) – Die Summe der quadrierten Differenzen zwischen einzelnen Datenpunkten …
Eine Dummy-Variable ist ein Variablentyp, den wir in der Regressionsanalyse erstellen, damit wir eine kategoriale Variable als numerische Variable darstellen können, die einen von zwei Werten annimmt: null oder eins …
Ein Residuum ist die Differenz zwischen einem beobachteten Wert und einem vorhergesagten Wert in einem Regressionsmodell.
Es wird berechnet als:
Residuum = Beobachteter Wert – Vorhergesagter Wert
Eine Möglichkeit zu verstehen, wie …
Eine einfache lineare Regressionslinie stellt die Linie dar, die am besten zu einem Datensatz passt.
Dieses Tutorial bietet ein schrittweises Beispiel dafür, wie Sie einem Streudiagramm in Excel schnell eine …
R-Quadrat, oft geschrieben als R2, ist der Anteil der Varianz in der Antwortvariablen, der durch die Prädiktorvariablen in einem linearen Regressionsmodell erklärt werden kann.
Der Wert für R-Quadrat kann …
R-Quadrat, oft als r2 geschrieben, ist ein Maß dafür, wie gut ein lineares Regressionsmodell zu einem Datensatz passt.
Technisch gesehen ist es der Anteil der Varianz in der Antwortvariablen …
Multikollinearität in der Regressionsanalyse tritt auf, wenn zwei oder mehr erklärende Variablen stark miteinander korreliert sind, sodass sie keine eindeutigen oder unabhängigen Informationen im Regressionsmodell liefern. Wenn der Korrelationsgrad zwischen …
Immer wenn wir ein lineares Regressionsmodell anpassen, nimmt das Modell die folgende Form an:
Y = β 0 + β 1 X + … + β i X +ϵ
wobei ϵ ein von X unabhängiger …
Ein Residuum ist die Differenz zwischen einem beobachteten Wert und einem vorhergesagten Wert in einem Regressionsmodell.
Es wird berechnet als:
Residuum = Beobachteter Wert – Vorhergesagter Wert
Wenn wir die beobachteten Werte …
Die Methode der kleinsten Quadrate ist eine Methode, mit der wir die Regressionslinie finden können, die am besten zu einem bestimmten Datensatz passt.
Um die Methode der kleinsten Quadrate zu …
Die multiple lineare Regression ist eine der am häufigsten verwendeten Techniken in der gesamten Statistik.
In diesem Tutorial wird erläutert, wie Sie jeden Wert in der Ausgabe eines multiplen linearen …
Die Regressionsanalyse wird verwendet, um die Beziehung zwischen einer oder mehreren erklärenden Variablen und einer Antwortvariablen zu quantifizieren.
Die häufigste Art der Regressionsanalyse ist die einfache lineare Regression, die verwendet …
Die Potenzregression ist eine Art nichtlinearer Regression, die die folgende Form annimmt:
y = ax b
wo:
Die exponentielle Regression ist eine Art von Regressionsmodell, mit dem die folgenden Situationen modelliert werden können:
1. Exponentielles Wachstum: Das Wachstum beginnt langsam und beschleunigt sich dann ohne Grenzen schnell …
Die logarithmische Regression ist eine Art von Regression, die verwendet wird, um Situationen zu modellieren, in denen Wachstum oder Verfall zuerst schnell beschleunigt und dann im Laufe der Zeit verlangsamt …
Die kubische Regression ist eine Regressionstechnik, die wir verwenden können, wenn die Beziehung zwischen einer Prädiktorvariablen und einer Antwortvariablen nicht linear ist.
Das folgende Schritt-für-Schritt-Beispiel zeigt, wie ein kubisches Regressionsmodell …
Die nichtlineare Regression ist eine Regressionstechnik, die verwendet wird, wenn die Beziehung zwischen einer Prädiktorvariablen und einer Antwortvariablen keinem linearen Muster folgt.
Das folgende Schritt-für-Schritt-Beispiel zeigt, wie Sie eine nichtlineare …
Die lineare Regression ist eine Methode, mit der die Beziehung zwischen einer oder mehreren erklärenden Variablen und einer Antwortvariablen quantifiziert werden kann.
Wir verwenden die einfache lineare Regression, wenn es …
R-Quadrat, oft R 2 geschrieben, ist der Anteil der Varianz in der Antwortvariablen, der durch die Prädiktorvariablen in einem linearen Regressionsmodell erklärt werden kann.
Der Wert für das R-Quadrat kann …
Ein Q-Q-Plot, kurz für „Quantil-Quantil“ -Diagramm, wird häufig verwendet, um zu bewerten, ob ein Datensatz möglicherweise aus einer theoretischen Verteilung stammt oder nicht. In den meisten Fällen wird diese Art …
Ein Residuum ist die Differenz zwischen einem beobachteten Wert und einem vorhergesagten Wert in einem Regressionsmodell.
Es wird berechnet als:
Residuum = beobachteter Wert - vorhergesagter Wert
Eine Möglichkeit zu verstehen, wie …
Ein Residuum ist die Differenz zwischen einem beobachteten Wert und einem vorhergesagten Wert in einem Regressionsmodell.
Es wird berechnet als:
Residuum = beobachteter Wert - vorhergesagter Wert
Wenn wir die beobachteten Werte …
Ein studentisiertes Residuum ist einfach ein Residuum geteilt durch seine geschätzte Standardabweichung.
In der Praxis sagen wir normalerweise, dass jede Beobachtung in einem Datensatz, deren studentisierter Residuum größer als ein …
Ein Residuendiagramm ist ein Diagrammtyp, bei dem die angepassten Werte gegen die Residuenwerte für ein Regressionsmodell angezeigt werden. Diese Art von Diagramm wird häufig verwendet, um zu bewerten, ob ein …
In der Regressionsanalyse bezieht sich Heteroskedastizität auf die ungleiche Streuung von Residuen. Insbesondere bezieht es sich auf den Fall, dass sich die Verteilung der Residuen über den Bereich der Messwerte …
Die lineare Regression ist eine Methode, mit der wir die Beziehung zwischen einer oder mehreren Prädiktorvariablen und einer Antwortvariablen verstehen können.
Wenn wir eine lineare Regression durchführen, sind wir normalerweise …
Der Cook-Abstand wird verwendet, um einflussreiche Beobachtungen in einem Regressionsmodell zu identifizieren.
Die Formel für den Cook-Abstand lautet:
D i = (r i 2 / p * MSE) * (h ii / (1-h ii ) 2 …
Die Regressionsanalyse wird verwendet, um die Beziehung zwischen einer oder mehreren erklärenden Variablen und einer Antwortvariablen zu quantifizieren.
Die häufigste Art der Regressionsanalyse ist die einfache lineare Regression, die verwendet …
Ein Anderson-Darling-Test ist ein Anpassungstest, der misst, wie gut Ihre Daten zu einer bestimmten Verteilung passen. Dieser Test wird am häufigsten verwendet, um festzustellen, ob Ihre Daten einer Normalverteilung folgen …
Eine der Annahmen der linearen Regression ist, dass es keine Korrelation zwischen den Residuen gibt. Mit anderen Worten wird angenommen, dass die Residuen unabhängig sind.
Eine Möglichkeit, um festzustellen, ob …
Multikollinearität in der Regressionsanalyse tritt auf, wenn zwei oder mehr erklärende Variablen stark miteinander korreliert sind, sodass sie keine eindeutigen oder unabhängigen Informationen im Regressionsmodell liefern. Wenn der Korrelationsgrad zwischen …
Die lineare Regression ist eine Methode, mit der wir die Beziehung zwischen einer oder mehreren Prädiktorvariablen und einer Antwortvariablen verstehen können.
In diesem Tutorial wird erklärt, wie Sie in Python …
Die quadratische Regression ist eine Art von Regression, mit der wir die Beziehung zwischen einer Prädiktorvariablen und einer Antwortvariablen quantifizieren können, wenn die wahren Beziehungen quadratisch sind, was in einem …
In einem Hypothesentest gibt es immer eine Fehlerrate vom Typ I, die die Wahrscheinlichkeit angibt, eine tatsächlich zutreffende Nullhypothese abzulehnen. Mit anderen Worten, es ist die Wahrscheinlichkeit, ein "falsches Positiv …
Wenn wir eine einfache lineare Regression in R durchführen, ist es einfach, die angepasste Regressionslinie zu visualisieren, da wir nur mit einer einzelnen Prädiktorvariablen und einer einzelnen Antwortvariablen arbeiten.
Der …
Immer wenn wir ein lineares Regressionsmodell in R anpassen, nimmt das Modell die folgende Form an:
Y = β 0 + β 1 X +… + β i X + ϵ
Dabei ist ϵ ein …
Der Goldfeld-Quandt-Test wird verwendet, um festzustellen, ob in einem Regressionsmodell Heteroskedastizität vorliegt.
Heteroskedastizität bezieht sich auf die ungleiche Streuung von Residuen auf verschiedenen Ebenen einer Antwortvariablen in einem Regressionsmodell.
Wenn …
Eine der Hauptannahmen bei der linearen Regression ist, dass es keine Korrelation zwischen den Residuen gibt, z. B. sind die Residuen unabhängig.
Eine Möglichkeit, um festzustellen, ob diese Annahme erfüllt …
Eine der Hauptannahmen der linearen Regression ist, dass die Residuen normal verteilt sind.
Eine Möglichkeit, diese Annahme visuell zu überprüfen, besteht darin, ein Histogramm der Residuen zu erstellen und zu …
Der Bestimmungskoeffizient (üblicherweise mit R 2 bezeichnet ) ist der Anteil der Varianz in der Antwortvariablen, der durch die erklärenden Variablen in einem Regressionsmodell erklärt werden kann.
Dieses Tutorial bietet ein …
Eine Box-Cox-Transformation ist eine häufig verwendete Methode zum Transformieren eines nicht normalverteilten Datensatzes in einen normalverteilten.
Die Grundidee hinter dieser Methode besteht darin, einen Wert für λ zu finden, so …
In der Statistik möchten wir oft wissen, wie einflussreich verschiedene Beobachtungen in Regressionsmodellen sind.
Eine Möglichkeit, den Einfluss von Beobachtungen zu berechnen, besteht in der Verwendung einer als DFBETAS bezeichneten …
In der Statistik möchten wir oft wissen, wie einflussreich verschiedene Beobachtungen in Regressionsmodellen sind.
Eine Möglichkeit, den Einfluss von Beobachtungen zu berechnen, besteht in der Verwendung einer Metrik namens DFFITS …
Um ein lineares Regressionsmodell in R anzupassen, können wir den Befehl lm() verwenden.
Um die Ausgabe des Regressionsmodells anzuzeigen, können Sie den Befehl summary() verwenden.
In diesem Tutorial wird erklärt …
Residuenplot werden häufig verwendet, um zu bewerten, ob die Residuen in einer Regressionsanalyse normal verteilt sind oder nicht und ob sie eine Heteroskedastizität aufweisen oder nicht.
In diesem Tutorial wird …
Der White-Test wird verwendet, um festzustellen, ob in einem Regressionsmodell Heteroskedastizität vorliegt.
Heteroskedastizität bezieht sich auf die ungleiche Streuung von Residuen auf verschiedenen Ebenen einer Antwortvariablen in einem Regressionsmodell, was …
Dieser Rechner erzeugt eine quadratische Regressionsgleichung basierend auf Werten für eine Prädiktorvariable und eine Antwortvariable.
Geben Sie einfach eine Liste mit Werten für eine Prädiktorvariable und eine Antwortvariable in die …
Dieser Rechner ermittelt die Regressionsquadratsumme einer Regressionsgleichung basierend auf Werten für eine Prädiktorvariable und eine Antwortvariable.
Geben Sie einfach eine Liste mit Werten für eine Prädiktorvariable und eine Antwortvariable in …
Ein Residuum ist die Differenz zwischen einem beobachteten Wert und einem vorhergesagten Wert in einem Regressionsmodell. Es wird berechnet als:
Residuum = beobachteter Wert - vorhergesagter Wert
Dieser Rechner findet die Residuen …
Dieser Rechner ermittelt die Residuenquadratsumme einer Regressionsgleichung basierend auf Werten für eine Prädiktorvariable und eine Antwortvariable.
Geben Sie einfach eine Liste mit Werten für eine Prädiktorvariable und eine Antwortvariable in …
Ein standardisiertes Residuum ist ein Residuum, das durch seine Standardabweichung geteilt wurde. Es wird berechnet als:
r i = e i / RSE√ 1-h ii
wo:
Dieser Rechner ermittelt die totale Quadratsumme einer Regressionsgleichung basierend auf Werten für eine Prädiktorvariable und eine Antwortvariable.
Geben Sie einfach eine Liste mit Werten für eine Prädiktorvariable und eine Antwortvariable …
Dieser Rechner erstellt ein Vorhersageintervall für einen bestimmten Wert in einer Regressionsanalyse.
Geben Sie einfach eine Liste mit Werten für eine Prädiktorvariable, eine Antwortvariable, einen einzelnen Wert zum Erstellen eines …
Dieser Rechner erzeugt eine lineare Regressionsgleichung basierend auf Werten für eine Prädiktorvariable und eine Antwortvariable.
Geben Sie einfach eine Liste mit Werten für eine Prädiktorvariable und eine Antwortvariable in die …
Wenn wir die Beziehung zwischen einer einzelnen Prädiktorvariablen und einer Antwortvariablen verstehen wollen, verwenden wir häufig eine einfache lineare Regression.
Wenn wir jedoch die Beziehung zwischen mehreren Prädiktorvariablen und einer …
Die einfache lineare Regression ist eine statistische Methode, mit der Sie die Beziehung zwischen zwei Variablen, x und y, verstehen können.
Eine Variable, x, ist als Prädiktorvariable bekannt.
Die andere …
Ein Breusch-Pagan-Test wird verwendet, um festzustellen, ob in einer Regressionsanalyse Heteroskedastizität vorliegt.
In diesem Tutorial wird erklärt, wie ein Breusch-Pagan-Test in R durchgeführt wird.
In diesem …
Die einfache lineare Regression ist eine statistische Methode, mit der Sie die Beziehung zwischen einer Prädiktorvariablen und einer Antwortvariablen quantifizieren können.
In diesem Tutorial wird erklärt, wie Sie eine einfache …
Die einfache lineare Regression ist eine Methode, mit der wir die Beziehung zwischen einer Prädiktorvariablen und einer Antwortvariablen verstehen können.
In diesem Tutorial wird erklärt, wie Sie eine einfache lineare …
Die multiple lineare Regression ist eine Methode, mit der wir die Beziehung zwischen zwei oder mehr erklärenden Variablen und einer Antwortvariablen verstehen können.
In diesem Tutorial wird erläutert, wie Sie …
Die logistische Regression ist eine Methode, mit der wir ein Regressionsmodell anpassen, wenn die Antwortvariable binär ist.
In diesem Tutorial wird erläutert, wie Sie eine logistische Regression in SPSS durchführen …
Hierarchische Regression ist eine Technik, mit der wir verschiedene lineare Modelle vergleichen können.
Die Grundidee ist, dass wir zuerst ein lineares Regressionsmodell mit nur einer erklärenden Variablen anpassen. Dann passen …
Wenn zwei Variablen eine lineare Beziehung haben, können wir häufig eine einfache lineare Regression verwenden, um ihre Beziehung zu quantifizieren.
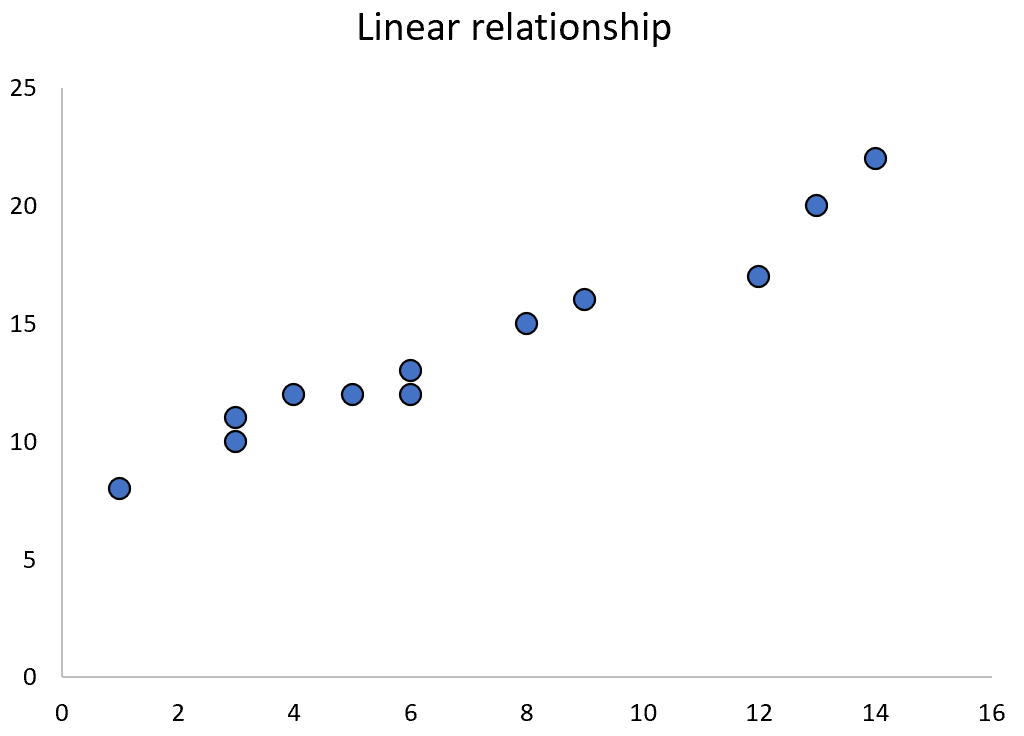
Wenn jedoch zwei Variablen eine quadratische Beziehung haben, können wir …
Die logistische Regression ist eine Methode, mit der wir ein Regressionsmodell anpassen, wenn die Antwortvariable binär ist.
In diesem Tutorial wird erläutert, wie Sie eine logistische Regression in Excel durchführen …
Die multiple lineare Regression ist eine Methode, mit der wir die Beziehung zwischen zwei oder mehr erklärenden Variablen und einer Antwortvariablen verstehen können.
In diesem Tutorial wird erklärt, wie Sie …
Die einfache lineare Regression ist eine statistische Methode, mit der Sie die Beziehung zwischen zwei Variablen, x und y, verstehen können. Eine Variable x, ist als Prädiktorvariable bekannt. Die andere …
Ein Residuendiagramm ist ein Diagrammtyp, bei dem die angepassten Werte gegen die Residuenwerte für ein Regressionsmodell angezeigt werden. Diese Art von Diagramm wird häufig verwendet, um zu bewerten, ob ein …
Ein Q-Q-Plot, kurz für „Quantil-Quantil“-Diagramm, wird häufig verwendet, um zu bewerten, ob ein Datensatz möglicherweise aus einer theoretischen Verteilung stammt oder nicht. In den meisten Fällen wird diese Art …
Ein Breusch-Pagan-Test wird verwendet, um festzustellen, ob in einer Regressionsanalyse Heteroskedastizität vorliegt.
In diesem Tutorial wird erklärt, wie ein Breusch-Pagan-Test in Excel durchgeführt wird.
In diesem …
Beim globalen F-Tests (auch Overall-F-Test oder F-Test auf Gesamtsignifikanz eines Modells) wird geprüft, ob mindestens eine erklärende Variable einen Erklärungsgehalt für das Modell liefert und das Modell somit als …
In der Statistik ist die Regressionsanalyse eine Technik, mit der die Beziehung zwischen Prädiktorvariablen und einer Antwortvariablen analysiert werden kann. Wenn Sie eine Regressionsanalyse mit Software (wie R, Stata, SPSS …
In der Statistik ist die Regression eine Technik, mit der die Beziehung zwischen Prädiktorvariablen und einer Antwortvariablen analysiert werden kann.
Wenn Sie eine Regressionsanalyse mit Software (wie R, SAS, SPSS …
Wenn wir ein Regressionsmodell an einen Datensatz anpassen, interessiert uns häufig, wie gut das Regressionsmodell zum Datensatz passt. Zwei Metriken, die üblicherweise zur Messung der Anpassungsgüte verwendet werden, umfassen das …
Die einfache lineare Regression ist eine Methode, mit der Sie die Beziehung zwischen einer erklärenden Variablen x und einer Antwortvariablen y verstehen können.
In diesem Tutorial wird erklärt, wie eine …
Die lineare Regression ist eine Methode, mit der wir die Beziehung zwischen einer oder mehreren erklärenden Variablen und einer Antwortvariablen verstehen können.
Wenn wir eine lineare Regression durchführen, sind wir …
In diesem Handbuch wird ein Beispiel für die Durchführung einer multiplen linearen Regression in R beschrieben, einschließlich:
Die Regression ist eine statistische Methode, mit der wir die Beziehung zwischen Prädiktorvariablen und einer Antwortvariablen verstehen können.
Die schrittweise Regression ist ein Verfahren, mit dem wir ein Regressionsmodell aus …
Wenn zwei Variablen eine lineare Beziehung haben, können Sie häufig eine einfache lineare Regression verwenden, um ihre Beziehung zu quantifizieren.
Eine einfache lineare Regression funktioniert jedoch nicht gut, wenn zwei …
In der Statistik ist die einfache lineare Regression eine Technik, mit der wir die Beziehung zwischen einer Prädiktorvariablen x und einer Antwortvariablen y quantifizieren können.
Wenn wir eine einfache lineare …
In der Statistik sind wir oft daran interessiert zu verstehen, wie zwei Variablen miteinander zusammenhängen. Zum Beispiel möchten wir vielleicht wissen:
Ein lineares Regressionsmodell kann für zwei Dinge nützlich sein:
(1) Quantifizieren der Beziehung zwischen einer oder mehreren Prädiktorvariablen und einer Antwortvariablen.
(2) Verwenden des Modells zur Vorhersage zukünftiger Werte.
In …
Eine Kriteriumsvariable ist einfach ein anderer Name für eine abhängige Variable oder eine Antwortvariable. Dies ist die Variable, die in einer statistischen Analyse vorhergesagt wird.
So wie erklärende Variablen unterschiedliche …
Multikollinearität in der Regressionsanalyse tritt auf, wenn zwei oder mehr Prädiktorvariablen stark miteinander korreliert sind, sodass sie keine eindeutigen oder unabhängigen Informationen im Regressionsmodell liefern. Wenn der Korrelationsgrad zwischen Variablen …
Die logistische Regression ist eine statistische Methode, mit der wir ein Regressionsmodell anpassen, wenn die Antwortvariable binär ist. Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz passt …
Die logistische Regression ist eine statistische Methode, mit der wir ein Regressionsmodell anpassen, wenn die Antwortvariable binär ist. Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz passt …
Ein Brier-Score ist eine Metrik, die wir in Statistiken verwenden, um die Genauigkeit probabilistischer Vorhersagen zu messen. Es wird normalerweise verwendet, wenn das Ergebnis einer Prognose binär ist – entweder tritt …
Der Sinn der Regressionsanalyse besteht darin, die Beziehung zwischen einer oder mehreren Prädiktorvariablen und einer Antwortvariablen zu verstehen.
Zum Beispiel könnte uns die Beziehung zwischen der Anzahl der untersuchten Stunden …
Die Regression ist eine statistische Technik, mit der wir die Beziehung zwischen einer oder mehreren Prädiktorvariablen und einer Antwortvariablen erklären können. Die häufigste Art der Regression ist die lineare Regression …
Die lineare Regression ist eine nützliche statistische Methode, mit der wir die Beziehung zwischen zwei Variablen, x und y, verstehen können. Bevor wir jedoch eine lineare Regression durchführen, müssen wir …
Angenommen, wir haben den folgenden Datensatz, der die Fläche und den Preis von 12 verschiedenen Häusern zeigt:
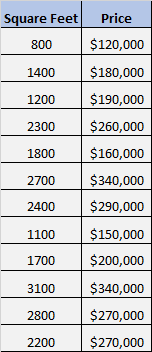
Wir möchten wissen, ob es einen signifikanten Zusammenhang zwischen der Fläche und dem …
Der Jarque-Bera-Test ist ein Anpassungstest, bei dem festgestellt wird, ob die Probendaten eine Schiefe und Kurtosis aufweisen, die einer Normalverteilung entsprechen.
Die Teststatistik des Jarque-Bera-Tests ist immer eine positive Zahl …
In der Statistik erstellen wir Modelle häufig aus zwei Gründen:
Die logistische Regression ist eine statistische Methode, mit der wir ein Regressionsmodell anpassen, wenn die Antwortvariable binär ist. Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz passt …
Die logistische Regression ist eine statistische Methode, mit der wir ein Regressionsmodell anpassen, wenn die Antwortvariable binär ist.
In diesem Tutorial werden vier verschiedene Beispiele für die Verwendung der logistischen …
Wenn zwei Variablen eine lineare Beziehung haben, können Sie häufig eine einfache lineare Regression verwenden, um ihre Beziehung zu quantifizieren.
Wenn jedoch zwei Variablen eine quadratische Beziehung haben, können Sie …
In der Regressionsanalyse bezieht sich Heteroskedastizität (manchmal buchstabierte Heteroskedastizität) auf die ungleiche Streuung von Residuen oder Fehlertermen. Insbesondere bezieht es sich auf den Fall, dass sich die Verteilung der Residuen …
Die multiple lineare Regression ist eine Methode, mit der Sie die Beziehung zwischen mehreren erklärenden Variablen und einer Antwortvariablen verstehen können.
In diesem Tutorial wird erklärt, wie Sie in Stata …
Das R-Quadrat ist ein Maß dafür, wie gut ein lineares Regressionsmodell zu einem Datensatz passt. R-Quadrat wird auch als Bestimmtheitsmaß bezeichnet und ist der Anteil der Varianz in der Antwortvariablen …
Die einfache lineare Regression (auch lineare Einfachregression) ist eine Methode, mit der wir die Beziehung zwischen einer erklärenden Variablen x und einer Antwortvariablen y verstehen können.
In diesem Tutorial wird …
Die lineare Regression ist eine der am häufigsten verwendeten Techniken in der Statistik. Es wird verwendet, um die Beziehung zwischen einer oder mehreren Prädiktorvariablen und einer Antwortvariablen zu quantifizieren.
Die …
Die logistische Regression ist eine Methode, mit der wir ein Regressionsmodell anpassen, wenn die Antwortvariable binär ist. Hier sind einige Beispiele, wann wir logistische Regression verwenden können:
Multikollinearität in der Regressionsanalyse tritt auf, wenn zwei oder mehr erklärende Variablen stark miteinander korreliert sind, sodass sie keine eindeutigen oder unabhängigen Informationen im Regressionsmodell liefern. Wenn der Korrelationsgrad zwischen …
Multikollinearität bei der Regressionsanalyse tritt auf, wenn zwei oder mehr Prädiktorvariablen stark miteinander korreliert sind, sodass sie keine eindeutigen oder unabhängigen Informationen im Regressionsmodell liefern. Wenn der Korrelationsgrad zwischen Variablen …
Die multiple lineare Regression ist eine Methode, mit der wir die Beziehung zwischen mehreren erklärenden Variablen und einer Antwortvariablen verstehen können.
Leider ist ein Problem, das bei der Regression häufig …
Wenn zwei Variablen eine lineare Beziehung haben, können wir häufig eine einfache lineare Regression verwenden, um ihre Beziehung zu quantifizieren.
Wenn jedoch zwei Variablen eine quadratische Beziehung haben, können wir …
Die multiple lineare Regression ist eine Methode, mit der wir die Beziehung zwischen mehreren erklärenden Variablen und einer Antwortvariablen verstehen können.
Leider ist ein Problem, das bei der Regression häufig …
Die lineare Regression ist eine Methode, mit der wir die Beziehung zwischen einer erklärenden Variablen x und einer Antwortvariablen y verstehen können.
In diesem Tutorial wird erklärt, wie eine lineare …
Ein Korrelationskoeffizient ist ein Maß für die lineare Assoziation zwischen zwei Variablen. Es kann einen Wert zwischen -1 und 1 annehmen, wobei:
Der Pearson-Korrelationskoeffizient (auch als „Produkt-Moment-Korrelationskoeffizient“ bekannt) ist ein Maß für die lineare Assoziation zwischen zwei Variablen X und Y. Er hat einen Wert zwischen -1 und 1, wobei:
"Statistik in Excel leicht gemacht" ist eine Sammlung von 16 Excel-Tabellen, die integrierte Formeln enthalten, um die wichtigsten statistischen Tests und Funktionen durchzuführen.

Statologie ist eine Website, die das Erlernen von Statistik erleichtert. Wir bei Statologie glauben, dass Statistik ein unglaublich nützliches Feld ist, viele aber von den verwirrenden Notationen und komplizierten Formeln eingeschüchtert werden.
Aus diesem Grund widmen wir uns dem Unterrichten auf einfache und unkomplizierte Weise - anhand von Beispielen, Abbildungen und Praxisnähe können wir Konzepte auf eine Weise erklären, die tatsächlich Sinn macht.