
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Die multiple lineare Regression ist eine Methode, mit der wir die Beziehung zwischen mehreren erklärenden Variablen und einer Antwortvariablen verstehen können.
Leider ist ein Problem, das bei der Regression häufig auftritt, die Heteroskedastizität, bei der sich die Varianz der Residuen über einen Bereich von Messwerten systematisch ändert.
Dies führt zu einer Erhöhung der Varianz der Regressionskoeffizientenschätzungen, das Regressionsmodell greift dies jedoch nicht auf. Dies macht es für ein Regressionsmodell viel wahrscheinlicher, zu erklären, dass ein Begriff im Modell statistisch signifikant ist, obwohl dies tatsächlich nicht der Fall ist.
Eine Möglichkeit, dieses Problem zu berücksichtigen, besteht darin, robuste Standardfehler zu verwenden, die für das Problem der Heteroskedastizität „robuster“ sind und tendenziell ein genaueres Maß für den tatsächlichen Standardfehler eines Regressionskoeffizienten liefern.
In diesem Tutorial wird erläutert, wie robuste Standardfehler bei der Regressionsanalyse in Stata verwendet werden.
Wir werden das integrierte automatische Stata-Dataset verwenden, um zu veranschaulichen, wie robuste Standardfehler bei der Regression verwendet werden.
Schritt 1: Laden und Anzeigen der Daten.
Verwenden Sie zunächst den folgenden Befehl, um die Daten zu laden:
sysuse auto
Zeigen Sie dann die Rohdaten mit dem folgenden Befehl an:
br

Schritt 2: Führen Sie eine mehrfache lineare Regression ohne robuste Standardfehler durch.
Als nächstes geben wir den folgenden Befehl ein, um eine multiple lineare Regression durchzuführen, wobei der Preis als Antwortvariable und mpg und das Gewicht als erklärende Variablen verwendet werden:
regress price mpg weight
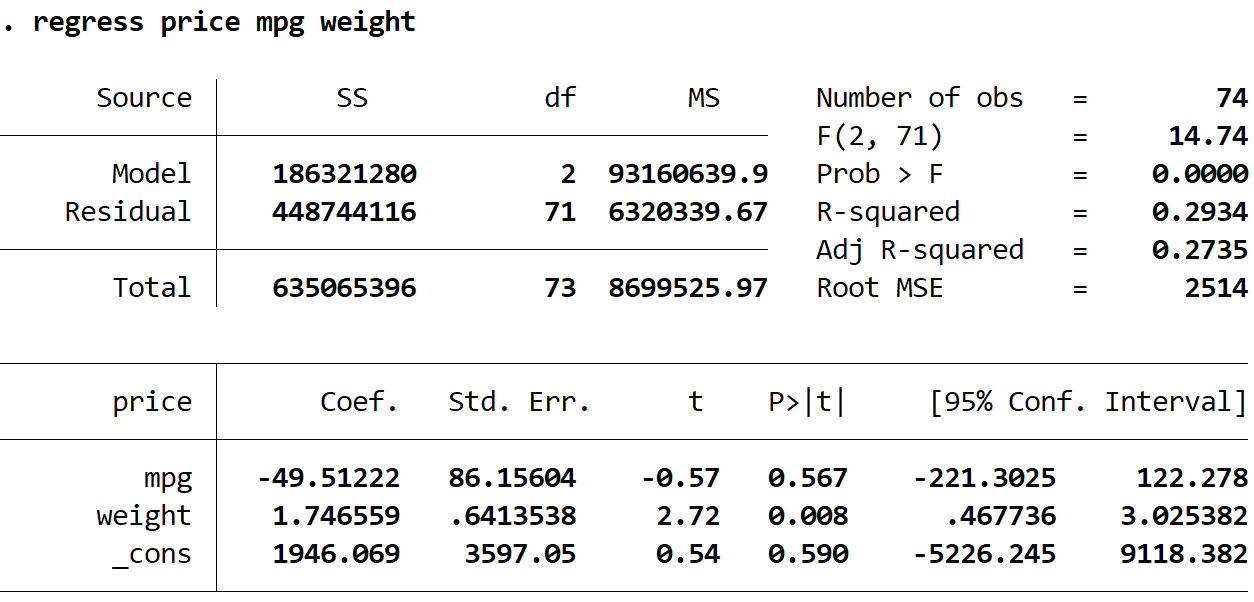
Schritt 3: Führen Sie eine multiple lineare Regression mit robusten Standardfehlern durch.
Jetzt führen wir genau dieselbe multiple lineare Regression durch, aber dieses Mal verwenden wir den Befehl vce(robust), damit Stata robuste Standardfehler verwenden kann:
regress price mpg weight, vce(robust)
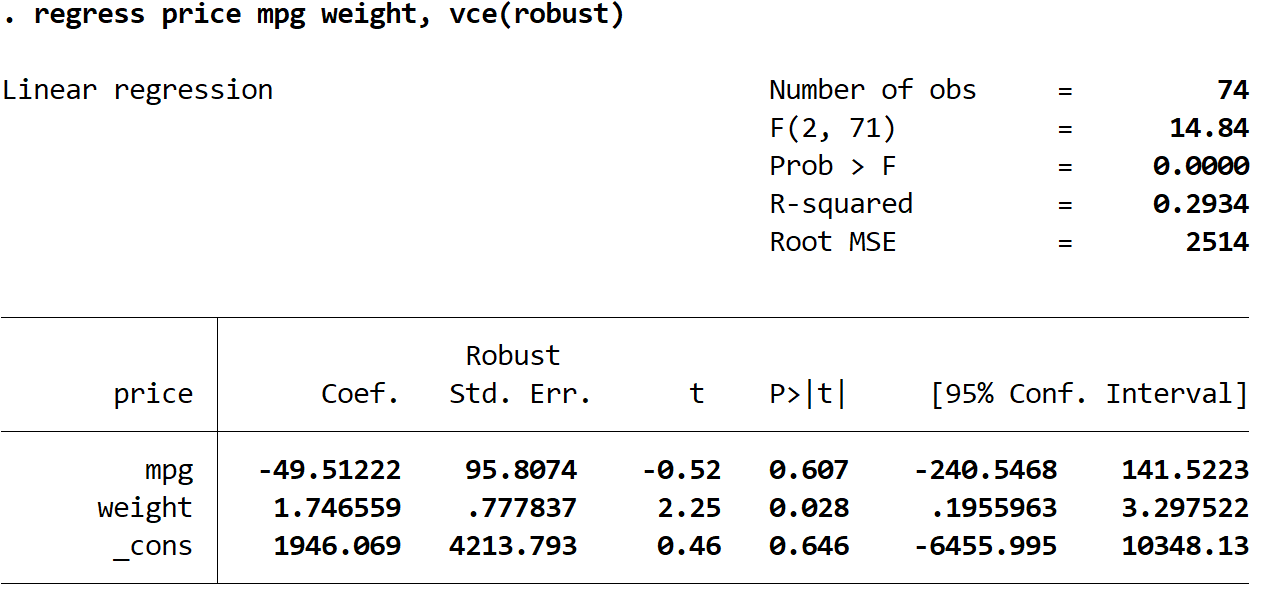
Hier sind einige interessante Dinge zu beachten:
Die Koeffizientenschätzungen blieben gleich. Wenn wir robuste Standardfehler verwenden, ändern sich die Koeffizientenschätzungen überhaupt nicht. Beachten Sie, dass die Koeffizientenschätzungen für mpg, Gewicht und Konstante für beide Regressionen wie folgt sind:
Die Standardfehler haben sich geändert. Beachten Sie, dass bei Verwendung robuster Standardfehler die Standardfehler für jede der Koeffizientenschätzungen zunahmen.
Notiz: In den meisten Fällen sind robuste Standardfehler größer als die normalen Standardfehler. In seltenen Fällen können die robusten Standardfehler jedoch tatsächlich kleiner sein.
Die Teststatistik jedes Koeffizienten wurde geändert. Beachten Sie, dass der Absolutwert jeder Teststatistik t abgenommen hat. Dies liegt daran, dass die Teststatistik als geschätzter Koeffizient geteilt durch den Standardfehler berechnet wird. Je größer der Standardfehler ist, desto kleiner ist der Absolutwert der Teststatistik.
Die p-Werte haben sich geändert. Beachten Sie, dass die p-Werte für jede Variable ebenfalls erhöht wurden. Dies liegt daran, dass kleinere Teststatistiken mit größeren p-Werten verbunden sind.
Obwohl sich die p-Werte für unsere Koeffizienten geändert haben, ist die Variable mpg bei α = 0,05 immer noch statistisch nicht signifikant und das variable Gewicht ist bei α = 0,05 immer noch statistisch signifikant.
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …