
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Die einfache lineare Regression ist eine statistische Methode, mit der Sie die Beziehung zwischen zwei Variablen, x und y, verstehen können.
Eine Variable, x, ist als Prädiktorvariable bekannt.
Die andere Variable y ist als Antwortvariable bekannt.
Angenommen, wir haben den folgenden Datensatz mit dem Gewicht und der Größe von sieben Personen:
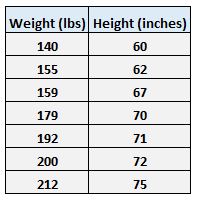
Das Gewicht sei die Prädiktorvariable und die Höhe die Antwortvariable.
Wenn wir diese beiden Variablen mithilfe eines Streudiagramms mit Gewicht auf der x-Achse und Höhe auf der y-Achse grafisch darstellen, würde dies folgendermaßen aussehen:
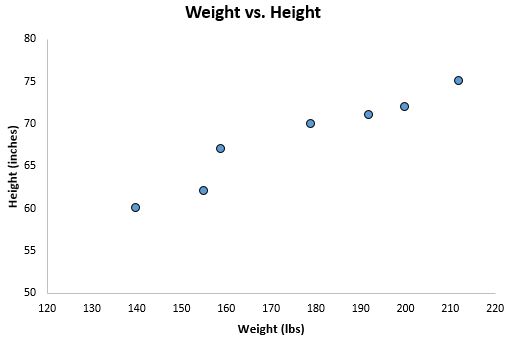
Angenommen, wir möchten die Beziehung zwischen Gewicht und Größe verstehen. Aus dem Streudiagramm können wir deutlich erkennen, dass mit zunehmendem Gewicht auch die Größe tendenziell zunimmt. Um diese Beziehung zwischen Gewicht und Größe tatsächlich zu quantifizieren, müssen wir jedoch eine lineare Regression verwenden.
Mithilfe der linearen Regression können wir die Linie finden, die am besten zu unseren Daten passt. Diese Linie ist als Regressionslinie der kleinsten Quadrate bekannt und kann verwendet werden, um die Beziehungen zwischen Gewicht und Größe zu verstehen. Normalerweise verwenden Sie Software wie Microsoft Excel, SPSS oder einen Grafikrechner, um die Gleichung für diese Linie zu finden.
Die Formel für die Linie der besten Anpassung lautet wie folgt:
ŷ = b 0 + b 1 x
Dabei ist ŷ der vorhergesagte Wert der Antwortvariablen, b 0 der y-Achsenabschnitt, b 1 der Regressionskoeffizient und x der Wert der Prädiktorvariablen.
Verwandt: 4 Beispiele für die Verwendung der linearen Regression im wirklichen Leben

Der Rechner findet automatisch die Regressionslinie der kleinsten Quadrate:
ŷ = 32,7830 + 0,2001x
Wenn wir unser Streudiagramm von vorher verkleinern und diese Linie zum Diagramm hinzufügen, sieht es folgendermaßen aus:

Beachten Sie, wie unsere Datenpunkte eng um diese Linie verteilt sind. Das liegt daran, dass diese Regressionsgeraden der kleinsten Quadrate die am besten passende Linie für unsere Daten aus allen möglichen Linien sind, die wir zeichnen könnten.
So interpretieren Sie diese Regressionslinie der kleinsten Quadrate: ŷ = 32,7830 + 0,2001x
b 0 = 32,7830. Dies bedeutet, wenn das variable Gewicht des Prädiktors null Pfund beträgt, beträgt die vorhergesagte Höhe 32,7830 Zoll. Manchmal kann es nützlich sein, den Wert für b 0 zu kennen, aber in diesem speziellen Beispiel ist es nicht sinnvoll, b 0 zu interpretieren, da eine Person keine Null Pfund wiegen kann.
b 1 = 0,2001. Dies bedeutet, dass eine Erhöhung von x um eine Einheit mit einer Erhöhung von y um 0,2001 Einheiten verbunden ist. In diesem Fall ist eine Gewichtszunahme von einem Pfund mit einer Zunahme der Höhe um 0,2001 Zoll verbunden.
Mit dieser Regressionsgeraden der kleinsten Quadrate können wir Fragen beantworten wie:
Wie groß würden wir für eine Person mit einem Gewicht von 170 Pfund erwarten?
Um dies zu beantworten, können wir einfach 170 in unsere Regressionslinie für x einfügen und nach y auflösen:
ŷ = 32,7830 + 0,2001 (170) = 66,8 Zoll
Wie groß würden wir für eine Person mit einem Gewicht von 150 Pfund erwarten?
Um dies zu beantworten, können wir 150 in unsere Regressionslinie für x einfügen und nach y auflösen:
ŷ = 32,7830 + 0,2001 (150) = 62,798 Zoll
Achtung: Wenn Sie eine Regressionsgleichung verwenden, um Fragen wie diese zu beantworten, stellen Sie sicher, dass Sie nur Werte für die Prädiktorvariable verwenden, die im Bereich der Prädiktorvariablen im ursprünglichen Datensatz liegen, den wir zum Generieren der Regressionslinie der kleinsten Quadrate verwendet haben. Zum Beispiel lagen die Gewichte in unserem Datensatz zwischen 140 lbs und 212 lbs. Daher ist es nur sinnvoll, Fragen zur vorhergesagten Größe zu beantworten, wenn das Gewicht zwischen 140 lbs und 212 lbs liegt.
Eine Möglichkeit zu messen, wie gut die Regressionslinie der kleinsten Quadrate zu den Daten „passt“, ist die Verwendung des Bestimmungskoeffizienten, der als R 2 bezeichnet wird.
Der Bestimmungskoeffizient ist der Anteil der Varianz in der Antwortvariablen, der durch die Prädiktorvariable erklärt werden kann.
Der Bestimmungskoeffizient kann im Bereich von 0 bis 1 liegen. Ein Wert von 0 zeigt an, dass die Antwortvariable überhaupt nicht durch die Prädiktorvariable erklärt werden kann. Ein Wert von 1 gibt an, dass die Antwortvariable durch die Prädiktorvariable fehlerfrei perfekt erklärt werden kann.
Ein R 2 zwischen 0 und 1 gibt an, wie gut die Antwortvariable durch die Prädiktorvariable erklärt werden kann. Zum Beispiel zeigt ein R 2 von 0,2 an, dass 20% der Varianz in der Antwortvariablen durch die Prädiktorvariable erklärt werden können; Ein R 2 von 0,77 zeigt an, dass 77% der Varianz in der Antwortvariablen durch die Prädiktorvariable erklärt werden können.
Beachten Sie, dass wir in unserer Ausgabe von vorher einen R 2 von 0,9311 erhalten haben, was darauf hinweist, dass 93,11% der Variabilität in der Höhe durch die Prädiktorvariable des Gewichts erklärt werden können:

Dies sagt uns, dass das Gewicht ein sehr guter Prädiktor für die Größe ist.
Damit die Ergebnisse eines linearen Regressionsmodells gültig und zuverlässig sind, müssen wir überprüfen, ob die folgenden vier Annahmen erfüllt sind:
1. Lineare Beziehung: Es besteht eine lineare Beziehung zwischen der unabhängigen Variablen x und der abhängigen Variablen y.
2. Unabhängigkeit: Die Residuen sind unabhängig. Insbesondere gibt es keine Korrelation zwischen aufeinanderfolgenden Residuen in Zeitreihendaten.
3. Homoskedastizität: Die Residuen weisen auf jeder Ebene von x eine konstante Varianz auf.
4. Normalität: Die Residuen des Modells sind normalverteilt.
Wenn eine oder mehrere dieser Annahmen verletzt werden, können die Ergebnisse unserer linearen Regression unzuverlässig oder sogar irreführend sein.
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …