
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Wenn wir ein Regressionsmodell an einen Datensatz anpassen, interessiert uns häufig, wie gut das Regressionsmodell zum Datensatz passt. Zwei Metriken, die üblicherweise zur Messung der Anpassungsgüte verwendet werden, umfassen das R-Quadrat (R2) und den Standardfehler der Regression, der häufig mit S bezeichnet wird.
In diesem Tutorial wird erklärt, wie der Standardfehler der Regression (S) interpretiert wird und warum er möglicherweise nützlichere Informationen als R 2 liefert.
Angenommen, wir haben einen einfachen Datensatz, der zeigt, wie viele Stunden 12 Schüler pro Tag pro Monat pro Tag gelernt haben, bevor eine wichtige Prüfung durchgeführt wurde, zusammen mit ihrer Prüfungsnote:

Wenn wir diesem Datensatz in Excel ein einfaches lineares Regressionsmodell anpassen, erhalten wir die folgende Ausgabe:

Das R-Quadrat ist der Anteil der Varianz in der Antwortvariablen, der durch die Prädiktorvariable erklärt werden kann. In diesem Fall können 65,76% der Varianz in den Prüfungsergebnissen durch die Anzahl der Stunden erklärt werden, die für das Lernen aufgewendet wurden.
Der Standardfehler der Regression ist der durchschnittliche Abstand, um den die beobachteten Werte von der Regressionslinie fallen. In diesem Fall fallen die beobachteten Werte durchschnittlich um 4,89 Einheiten von der Regressionslinie ab.
Wenn wir die tatsächlichen Datenpunkte zusammen mit der Regressionslinie zeichnen, können wir dies deutlicher sehen:
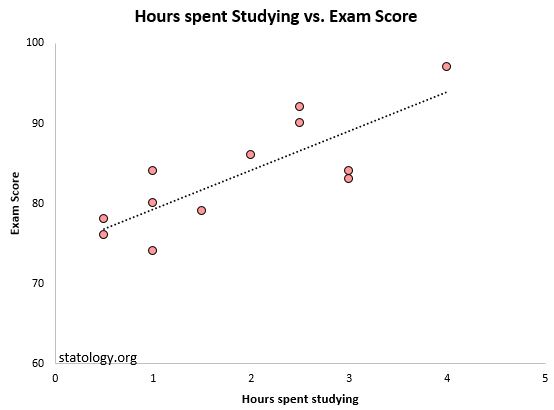
Beachten Sie, dass einige Beobachtungen sehr nahe an der Regressionslinie liegen, während andere nicht ganz so nahe sind. Im Durchschnitt fallen die beobachteten Werte jedoch um 4,19 Einheiten von der Regressionslinie ab.
Der Standardfehler der Regression ist besonders nützlich, da er zur Beurteilung der Genauigkeit von Vorhersagen verwendet werden kann. Etwa 95% der Beobachtung sollten innerhalb von +/- zwei Standardfehlern der Regression liegen, was eine schnelle Annäherung an ein Vorhersageintervall von 95% darstellt.
Wenn wir Vorhersagen unter Verwendung des Regressionsmodells treffen möchten, kann der Standardfehler der Regression eine nützlichere Metrik sein als das R-Quadrat, da er uns eine Vorstellung davon gibt, wie genau unsere Vorhersagen in Einheiten sein werden.
Um zu veranschaulichen, warum der Standardfehler der Regression eine nützlichere Messgröße für die Beurteilung der „Anpassung“ eines Modells sein kann, betrachten Sie einen anderen Beispieldatensatz, der zeigt, wie viele Stunden 12 Schüler pro Tag pro Tag vor einer wichtigen Prüfung zusammen mit studiert haben ihre Prüfungsergebnisse:
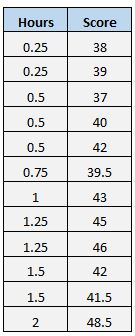
Beachten Sie, dass dies genau derselbe Datensatz wie zuvor ist, außer dass alle Werte s in zwei Hälften geschnitten werden. Somit haben die Schüler in diesem Datensatz genau halb so lange studiert wie die Schüler im vorherigen Datensatz und genau die Hälfte der Prüfungsergebnisse erhalten.
Wenn wir diesem Datensatz in Excel ein einfaches lineares Regressionsmodell anpassen, erhalten wir die folgende Ausgabe:
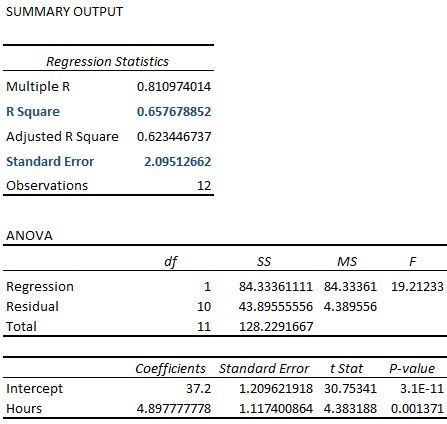
Beachten Sie, dass das R-Quadrat von 65,76% genau dem vorherigen Beispiel entspricht.
Der Standardfehler der Regression beträgt jedoch 2,095, was genau halb so groß ist wie der Standardfehler der Regression im vorherigen Beispiel.
Wenn wir die tatsächlichen Datenpunkte zusammen mit der Regressionslinie zeichnen, können wir dies deutlicher sehen:
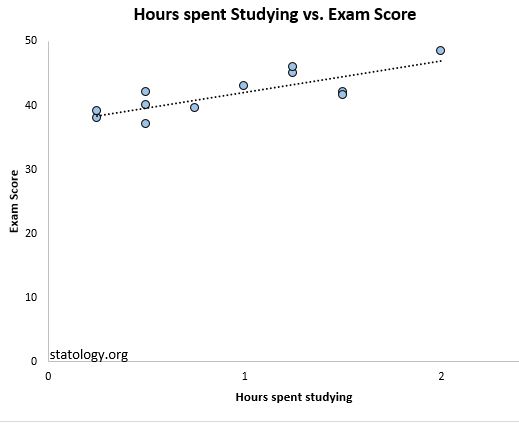
Beachten Sie, wie die Beobachtungen viel enger um die Regressionslinie gepackt sind. Im Durchschnitt fallen die beobachteten Werte um 2,095 Einheiten von der Regressionslinie ab.
Obwohl beide Regressionsmodelle ein R-Quadrat von 65,76% haben, wissen wir, dass das zweite Modell genauere Vorhersagen liefern würde, da es einen niedrigeren Standardfehler der Regression aufweist.
Der Standardfehler der Regression (S) ist oft nützlicher zu wissen als das R-Quadrat des Modells, da er uns tatsächliche Einheiten liefert. Wenn wir ein Regressionsmodell verwenden möchten, um Vorhersagen zu erstellen, kann S uns sehr leicht sagen, ob ein Modell präzise genug ist, um für Vorhersagen verwendet zu werden.
Angenommen, wir möchten ein Vorhersageintervall von 95% erstellen, in dem wir Prüfungsergebnisse innerhalb von 6 Punkten des tatsächlichen Ergebnisses vorhersagen können.
Unser erstes Modell hat ein R-Quadrat von 65,76%, aber dies sagt nichts darüber aus, wie genau unser Vorhersageintervall sein wird. Zum Glück wissen wir auch, dass das erste Modell ein S von 4,19 hat. Dies bedeutet, dass ein Vorhersageintervall von 95% ungefähr 2 * 4,19 = +/- 8,38 Einheiten breit wäre, was für unser Vorhersageintervall zu breit ist.
Unser zweites Modell hat ebenfalls ein R-Quadrat von 65,76%, aber auch dies sagt nichts darüber aus, wie genau unser Vorhersageintervall sein wird. Wir wissen jedoch, dass das zweite Modell einen S von 2,095 hat. Dies bedeutet, dass ein Vorhersageintervall von 95% ungefähr 2 × 2,095 = +/- 4,19 Einheiten breit wäre, was weniger als 6 ist und somit ausreichend genau ist, um zur Erzeugung von Vorhersageintervallen verwendet zu werden.
Weiterführende Literatur
Einführung in die einfache lineare Regression
Was ist ein guter R-Quadrat-Wert?
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …