
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Die multiple lineare Regression ist eine der am häufigsten verwendeten Techniken in der gesamten Statistik.
In diesem Tutorial wird erläutert, wie Sie jeden Wert in der Ausgabe eines multiplen linearen Regressionsmodells in Excel interpretieren.
Angenommen, wir möchten wissen, ob die Anzahl der Studienstunden und die Anzahl der abgelegten Vorbereitungsprüfungen die Punktzahl beeinflussen, die ein Student bei einer bestimmten College-Aufnahmeprüfung erhält.
Um diese Beziehung zu untersuchen, können wir eine multiple lineare Regression durchführen, indem wir hours studied (Stunden studiert) und prep exams taken (Anzahl Vorbereitungsprüfungen) als Prädiktorvariablen und exam score (Prüfungsergebnis) als Antwortvariable verwenden.
Der folgende Screenshot zeigt die Regressionsausgabe dieses Modells in Excel:
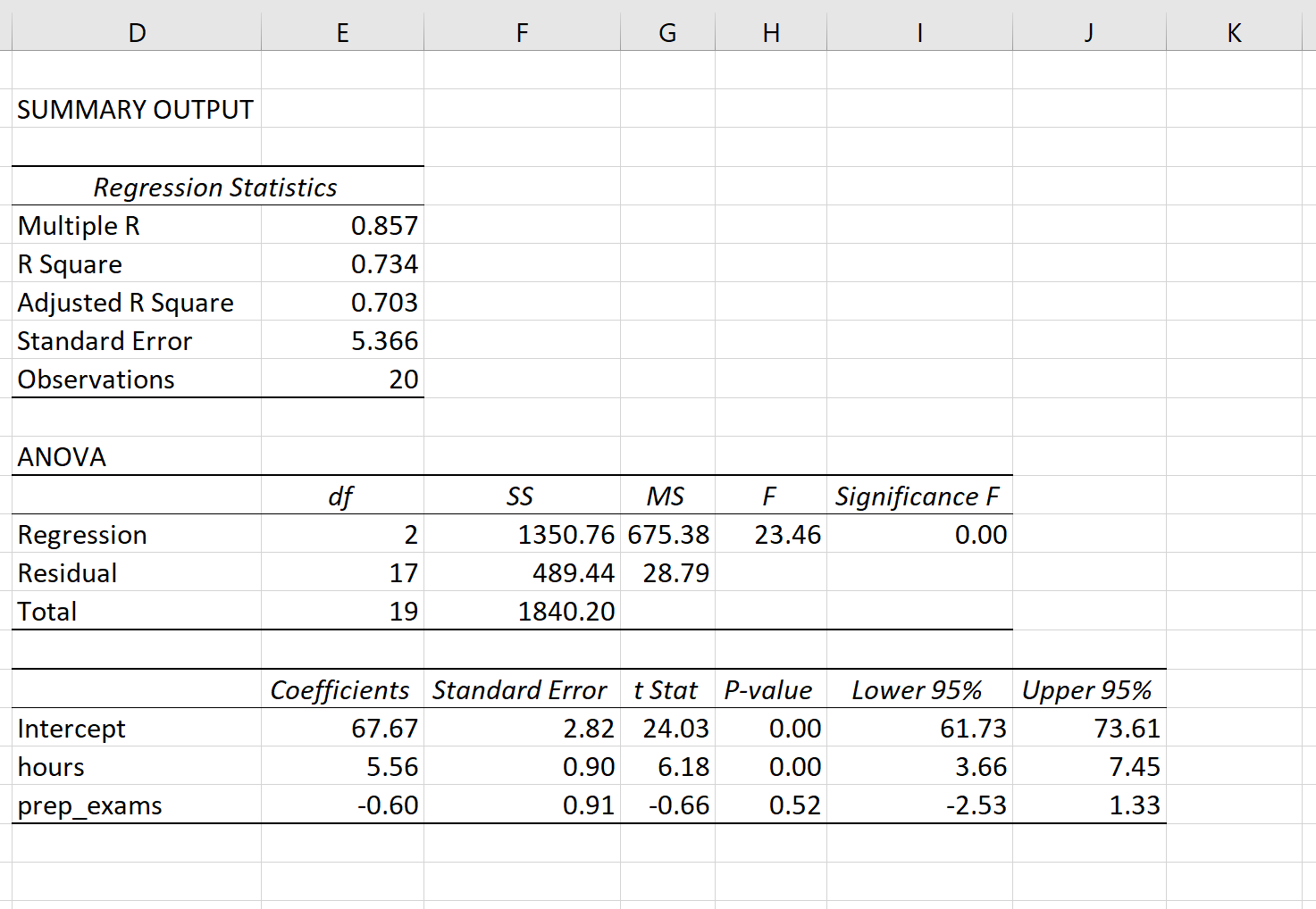
So interpretieren Sie die wichtigsten Werte in der Ausgabe:
Multiple R: 0,857. Dies repräsentiert die multiple Korrelation zwischen der Antwortvariablen und den beiden Prädiktorvariablen.
R Square: 0,734. Dies wird als Bestimmtheitsmaß bezeichnet. Es ist der Anteil der Varianz in der Antwortvariablen, der durch die erklärenden Variablen erklärt werden kann. In diesem Beispiel können 73,4% der Abweichung der Prüfungsergebnisse durch die Anzahl der studierten Stunden und die Anzahl der abgelegten Vorbereitungsprüfungen erklärt werden.
Adjusted R Square: 0,703. Dies stellt den R-Quadrat-Wert dar, angepasst an die Anzahl der Prädiktorvariablen im Modell . Dieser Wert ist auch kleiner als der Wert für R-Quadrat und benachteiligt Modelle, die zu viele Prädiktorvariablen im Modell verwenden.
Standard error: 5.366. Dies ist der durchschnittliche Abstand der beobachteten Werte von der Regressionsgerade. In diesem Beispiel fallen die beobachteten Werte durchschnittlich 5,366 Einheiten von der Regressionsgerade ab.
Observations: 20. Die Gesamtstichprobengröße des Datensatzes, der zur Erstellung des Regressionsmodells verwendet wurde.
F: 23.46. Dies ist die Gesamt-F-Statistik für das Regressionsmodell, berechnet als Regressions-MS / Rest-MS.
Significance F: 0.0000. Dies ist der p-Wert, der der gesamten F-Statistik zugeordnet ist. Sie sagt uns, ob das Regressionsmodell insgesamt statistisch signifikant ist oder nicht.
In diesem Fall liegt der p-Wert unter 0,05, was darauf hindeutet, dass die erklärenden Variablen hours studied und prep exams taken zusammen eine statistisch signifikante Assoziation mit exam score haben.
Coefficients: Die Koeffizienten für jede erklärende Variable geben uns die durchschnittliche erwartete Änderung der Antwortvariablen an, unter der Annahme, dass die andere erklärende Variable konstant bleibt.
Zum Beispiel wird erwartet, dass sich die durchschnittliche Prüfungspunktzahl für jede zusätzliche Stunde, die mit Lernen verbracht wird, um 5,56 erhöht, vorausgesetzt prep exams taken bleibt konstant.
Wir interpretieren den Koeffizienten für den Achsenabschnitt so, dass die erwartete Prüfungspunktzahl für einen Schüler, der null Stunden studiert hat und keine Vorbereitungsprüfungen ablegt, 67,67 beträgt.
P-values: Die einzelnen p-Werte sagen uns, ob jede erklärende Variable statistisch signifikant ist oder nicht. Wir können sehen, dass hours studied statistisch signifikant sind (p = 0,00), während prep exams taken (p = 0,52) mit α = 0,05 statistisch nicht signifikant sind.
Wir können die Koeffizienten aus der Ausgabe des Modells verwenden, um die folgende geschätzte Regressionsgleichung zu erstellen:
exam score = 67,67 + 5,56*(hours studied) – 0,60*(prep exams taken)
Wir können diese geschätzte Regressionsgleichung verwenden, um die erwartete Prüfungspunktzahl für einen Schüler zu berechnen, basierend auf der Anzahl der Stunden, die er lernt, und der Anzahl der Vorbereitungsprüfungen, die er ablegt.
Zum Beispiel wird von einem Studenten, der drei Stunden studiert und eine Vorbereitungsprüfung ablegt, eine Punktzahl von 83,75 erwartet:
exam score = 67,67 + 5,56*(3) – 0,60*(1) = 83,75
Denken Sie daran, dass wir uns möglicherweise entscheiden, prep exams taken zu entfernen, da die Anzahl der abgelegten Vorbereitungsprüfungen statistisch nicht signifikant waren (p = 0,52), da sie das Gesamtmodell nicht verbessert.
In diesem Fall könnten wir eine einfache lineare Regression durchführen, indem wir nur die hours studied als erklärende Variable verwenden.
Einführung in die einfache lineare Regression
Einführung in die multiple lineare Regression
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …