
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
In diesem Handbuch wird ein Beispiel für die Durchführung einer multiplen linearen Regression in R beschrieben, einschließlich:
Los geht’s!
In diesem Beispiel verwenden wir den integrierten R-Datensatz mtcars, der Informationen zu verschiedenen Attributen für 32 verschiedene Fahrzeuge enthält:
#Die ersten sechs Zeilen von mtcars anzeigen
head(mtcars)
# mpg cyl disp hp drat wt qsec vs am gear carb
#Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
#Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
#Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
#Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
#Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
#Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
In diesem Beispiel erstellen wir ein multiples lineares Regressionsmodell, das mpg als Antwortvariable und disp, hp und drat als Prädiktorvariablen verwendet.
#Erstellen Sie ein neues Dataframe, der nur die Variablen enthält, die wir verwenden möchten um das Regressionsmodell anzupassen
data <- mtcars[ , c("mpg", "disp", "hp", "drat")]
# Die ersten sechs Zeilen des neuen Dataframes anzeigen
head(Daten)
# mpg disp hp drat
#Mazda RX4 21.0 160 110 3.90
#Mazda RX4 Wag 21.0 160 110 3.90
#Datsun 710 22.8 108 93 3.85
#Hornet 4 Drive 21.4 258 110 3.08
#Hornet Sportabout 18.7 360 175 3.15
#Valiant 18.1 225 105 2.76
Bevor wir das Modell anpassen, können wir die Daten untersuchen, um sie besser zu verstehen, und auch visuell beurteilen, ob die multiple lineare Regression ein gutes Modell für die Anpassung an diese Daten sein kann.
Insbesondere müssen wir prüfen, ob die Prädiktorvariablen eine lineare Assoziation mit der Antwortvariablen haben, was darauf hinweisen würde, dass ein multiples lineares Regressionsmodell geeignet sein könnte.
Dazu können wir mit der Funktion pair() ein Streudiagramm jedes möglichen Variablenpaars erstellen:
pairs(data, pch = 18, col = "steelblue")

Aus diesem Paardiagramm können wir Folgendes sehen:
Beachten Sie, dass wir auch die Funktion ggpairs() aus der GGally-Bibliothek verwenden können, um ein ähnliches Diagramm zu erstellen, das die tatsächlichen linearen Korrelationskoeffizienten für jedes Variablenpaar enthält:
#Installieren und laden Sie die GGally- Bibliothek
install.packages("GGally")
library(GGally)
#Generieren Sie das Paardiagramm
ggpairs(data)
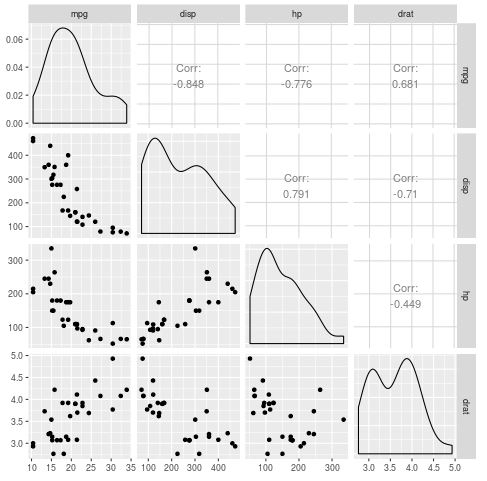
Jede der Prädiktorvariablen scheint eine merkliche lineare Korrelation mit der Antwortvariablen mpg zu haben, daher werden wir das lineare Regressionsmodell an die Daten anpassen.
Die grundlegende Syntax zum Anpassen eines multiplen linearen Regressionsmodells in R lautet wie folgt:
lm(response_variable ~ predictor_variable1 + predictor_variable2 + ..., data = data)
Mit unseren Daten können wir das Modell mit dem folgenden Code anpassen:
model <- lm(mpg ~ disp + hp + drat, data = data)
Bevor wir die Ausgabe des Modells überprüfen, müssen wir zunächst überprüfen, ob die Modellannahmen erfüllt sind. Wir müssen nämlich Folgendes überprüfen:
1. Die Verteilung der Modellresiduen sollte ungefähr normal sein.
Wir können überprüfen, ob diese Annahme erfüllt ist, indem wir ein einfaches Histogramm der Residuen erstellen:
hist(residuals(model), col = "steelblue")
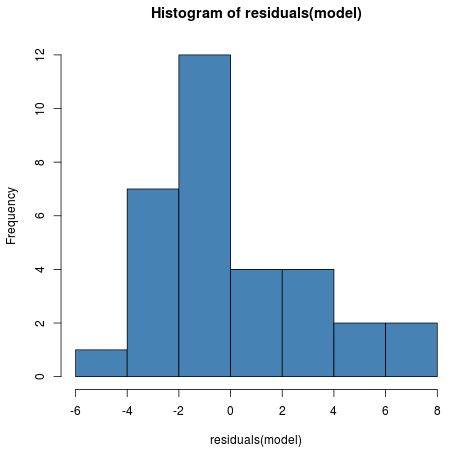
Obwohl die Verteilung leicht nach rechts verzerrt ist, ist sie nicht abnormal genug, um größere Bedenken zu verursachen.
2. Die Varianz der Residuen sollte für alle Beobachtungen konsistent sein.
Diese bevorzugte Bedingung ist als Homoskedastizität bekannt. Ein Verstoß gegen diese Annahme wird als Heteroskedastizität bezeichnet. Um zu überprüfen, ob diese Annahme erfüllt ist, können wir einen fitted value vs. residual plot erstellen :
#fitted value vs. residual plot
plot(fitted(model), residuals(model))
#Horizontale Linie bei 0 hinzufügen
abline(h = 0, lty = 2)
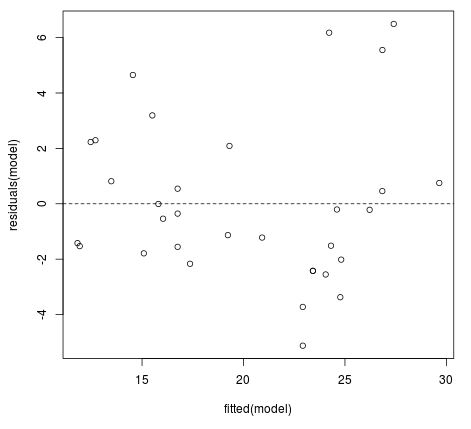
Idealerweise möchten wir, dass die Residuen bei jedem angepassten Wert gleichmäßig gestreut werden. Wir können dem Diagramm entnehmen, dass die Streuung bei größeren angepassten Werten tendenziell etwas größer wird, aber dieses Muster ist nicht extrem genug, um zu viel Sorge zu verursachen.
Sobald wir überprüft haben, ob die Modellannahmen ausreichend erfüllt sind, können wir die Ausgabe des Modells mithilfe der Funktion summary() betrachten:
summary(model)
#Call:
#lm(formula = mpg ~ disp + hp + drat, data = data)
#
#Residuals:
# Min 1Q Median 3Q Max
#-5.1225 -1.8454 -0.4456 1.1342 6.4958
#
#Coefficients:
# Estimate Std. Error t value Pr(>|t|)
#(Intercept) 19.344293 6.370882 3.036 0.00513 **
#disp -0.019232 0.009371 -2.052 0.04960 *
#hp -0.031229 0.013345 -2.340 0.02663 *
#drat 2.714975 1.487366 1.825 0.07863.
#---
#Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#
#Residual standard error: 3.008 on 28 degrees of freedom
#Multiple R-squared: 0.775, Adjusted R-squared: 0.7509
#F-statistic: 32.15 on 3 and 28 DF, p-value: 3.28e-09
Aus der Ausgabe können wir Folgendes sehen:
Um zu beurteilen, wie „gut“ das Regressionsmodell zu den Daten passt, können wir verschiedene Metriken betrachten:
1. Mehrfaches R-Quadrat
Dies misst die Stärke der linearen Beziehung zwischen den Prädiktorvariablen und der Antwortvariablen. Ein mehrfaches R-Quadrat von 1 zeigt eine perfekte lineare Beziehung an, während ein mehrfaches R-Quadrat von 0 keinerlei lineare Beziehung anzeigt.
Das multiple R ist auch die Quadratwurzel des R-Quadrats,d.h.der Anteil der Varianz in der Antwortvariablen, der durch die Prädiktorvariablen erklärt werden kann. In diesem Beispiel beträgt das multiple R-Quadrat 0,775. Somit beträgt das R-Quadrat 0,775 2 = 0,601. Dies zeigt, dass 60,1% der Varianz in mpg durch die Prädiktoren im Modell erklärt werden können.
Verwandt: Was ist ein guter R-Quadrat-Wert?
2. Standardfehler der Residuen
Dies misst den durchschnittlichen Abstand, um den die beobachteten Werte von der Regressionslinie fallen. In diesem Beispiel fallen die beobachteten Werte durchschnittlich um 3,008 Einheiten von der Regressionslinie ab .
Verbunden: Grundlegendes zum Standardfehler der Regression
Aus der Ausgabe des Modells wissen wir, dass die angepasste multiple lineare Regressionsgleichung wie folgt lautet:
mpg hat = -19,343 – 0,019 * disp – 0,031 * PS + 2,715 * drat
Wir können diese Gleichung verwenden, um Vorhersagen darüber zu treffen, was mpg für neue Beobachtungen sein wird. Zum Beispiel können wir den vorhergesagten Wert von mpg für ein Auto finden, das die folgenden Attribute hat:
#Definieren Sie die Koeffizienten aus der Modellausgabe
intercept <- coef(summary(model))["(Intercept)", "Estimate"]
disp <- coef(summary(model))["disp", "Estimate"]
hp <- coef(summary(model))["hp", "Estimate"]
drat <- coef(summary(model))["drat", "Estimate"]
#Verwenden Sie die Modellkoeffizienten, um den Wert für mpg vorherzusagen
intercept + disp*220 + hp*150 + drat*3
# [1] 18.57373
Für ein Auto mit disp = 220, hp = 150 und drat = 3 sagt das Modell voraus, dass das Auto einen mpg von 18,57373 haben würde.
Weiterführende Literatur:
Ein Leitfaden zu Multikollinearität und VIF in der Regression
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …