
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Bei der Verwendung von Klassifizierungsmodellen beim maschinellen Lernen ist eine gängige Metrik, die wir verwenden, um die Qualität des Modells zu bewerten, der F1-Score.
Diese Metrik wird wie folgt berechnet:
F1-Punktzahl = 2 * (Präzision * Erinnerung) / (Präzision + Erinnerung)
wo:
Angenommen, wir verwenden ein logistisches Regressionsmodell, um vorherzusagen, ob 400 verschiedene College-Basketballspieler in die NBA eingezogen werden oder nicht.
Die folgende Konfusionsmatrix fasst die Vorhersagen des Modells zusammen:
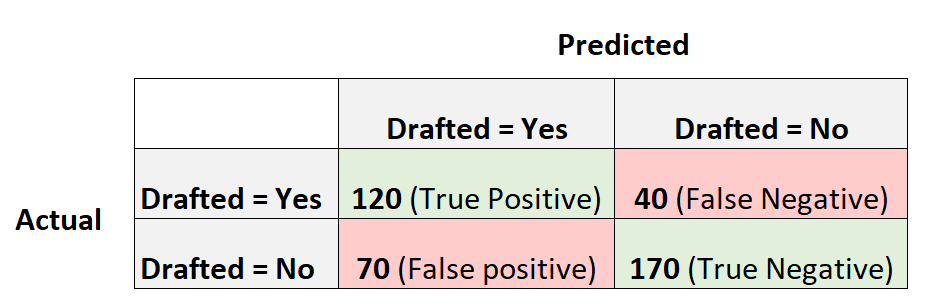
So berechnen Sie den F1-Score des Modells:
Genauigkeit = Richtig Positiv / (Richtig Positiv + Falsch Positiv) = 120/ (120+70) = 0,63157
Erinnerung = Richtig Positiv / (Richtig Positiv + Falsch Negativ) = 120 / (120+40) = 0,75
F1-Punktzahl = 2 * (0,63157 * 0,75) / (0,63157 + 0,75) = . 6857
Das folgende Beispiel zeigt, wie der F1-Score für genau dieses Modell in Python berechnet wird.
Der folgende Code zeigt, wie die Funktion f1_score() aus dem Paket sklearn in Python verwendet wird, um den F1-Score für ein bestimmtes Array von vorhergesagten Werten und tatsächlichen Werten zu berechnen.
import numpy as np
from sklearn.metrics import f1_score
#Array von tatsächlichen Klassen definieren
actual = np.repeat([1, 0], repeats=[160, 240])
#Array vorhergesagter Klassen definieren
pred = np.repeat([1, 0, 1, 0], repeats=[120, 40, 70, 170])
#Berechnen Sie den F1-Score
f1_score(actual, pred)
0.6857142857142857
Wir können sehen, dass der F1-Score 0,6857 beträgt. Dies entspricht dem Wert, den wir zuvor von Hand berechnet haben.
Hinweis : Die vollständige Dokumentation für die Funktion f1_score() finden Sie hier .
Wenn Sie den F1-Score verwenden, um mehrere Modelle zu vergleichen, stellt das Modell mit dem höchsten F1-Score das Modell dar, das Beobachtungen am besten in Klassen einteilen kann.
Wenn Sie beispielsweise ein anderes logistisches Regressionsmodell an die Daten anpassen und dieses Modell einen F1-Score von 0,75 hat, wird dieses Modell als besser angesehen, da es einen höheren F1-Score hat.
So führen Sie eine logistische Regression in Python durch
So erstellen Sie eine Verwirrungsmatrix in Python
So berechnen Sie die ausgewogene Genauigkeit in Python
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …