
Ein Log-Log-Diagramm ist ein Diagramm, das sowohl auf der x-Achse als auch auf der y-Achse logarithmische Skalen verwendet.
Diese Art von Diagramm ist nützlich, um zwei Variablen zu visualisieren, wenn …
Sie können die Funktion regplot() aus der Seaborn-Datenvisualisierungsbibliothek verwenden, um eine logistische Regressionskurve in Python zu zeichnen:
import seaborn as sns
sns.regplot(x=x, y=y, data=df, logistic=True, ci=None)
Das folgende Beispiel zeigt, wie Sie diese Syntax in der Praxis verwenden können.
Für dieses Beispiel verwenden wir das Standard -Dataset aus dem Buch Introduction to Statistical Learning . Wir können den folgenden Code verwenden, um eine Zusammenfassung des Datensatzes zu laden und anzuzeigen:
#Datensatz aus CSV-Datei auf Github importieren
url = "https://raw.githubusercontent.com/Statology/Python-Guides/main/default.csv"
data = pd.read_csv(url)
#erste sechs Zeilen des Datensatzes anzeigen
data[0:6]
default student balance income
0 0 0 729.526495 44361.625074
1 0 1 817.180407 12106.134700
2 0 0 1073.549164 31767.138947
3 0 0 529.250605 35704.493935
4 0 0 785.655883 38463.495879
5 0 1 919.588530 7491.558572
Dieser Datensatz enthält die folgenden Informationen über 10.000 Personen:
Angenommen, wir möchten ein logistisches Regressionsmodell erstellen, das „Balance“ verwendet, um die Wahrscheinlichkeit vorherzusagen, dass eine bestimmte Person ausfällt.
Wir können den folgenden Code verwenden, um eine logistische Regressionskurve zu zeichnen:
#definieren Sie die Prädiktorvariable und die Antwortvariable
x = data['balance']
y = data['default']
#plot logistische Regressionskurve
sns.regplot(x=x, y=y, data=data, logistic=True, ci=None)
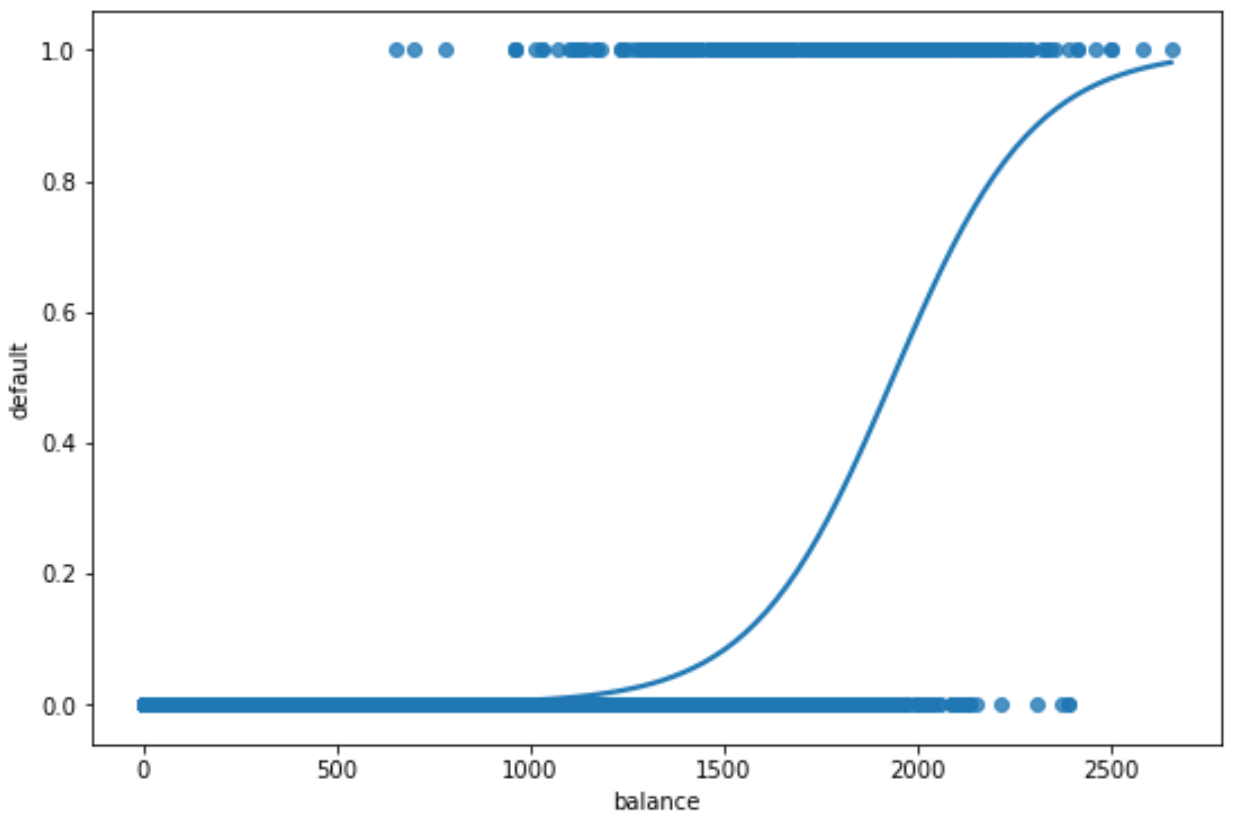
Die x-Achse zeigt die Werte der Prädiktorvariablen „Saldo“ und die y-Achse die prognostizierte Ausfallwahrscheinlichkeit.
Wir können deutlich erkennen, dass höhere Saldowerte mit höheren Wahrscheinlichkeiten verbunden sind, dass eine Person ausfällt.
Beachten Sie, dass Sie auch scatter_kws und line_kws verwenden können, um die Farben der Punkte und der Kurve im Diagramm zu ändern:
#definieren Sie die Prädiktorvariable und die Antwortvariable
x = data['balance']
y = data['default']
#plot logistische Regressionskurve mit schwarzen Punkten und roter Linie
sns.regplot(x=x, y=y, data=data, logistic=True, ci=None),
scatter_kws={'color': 'black'}, line_kws={'color': 'red'})
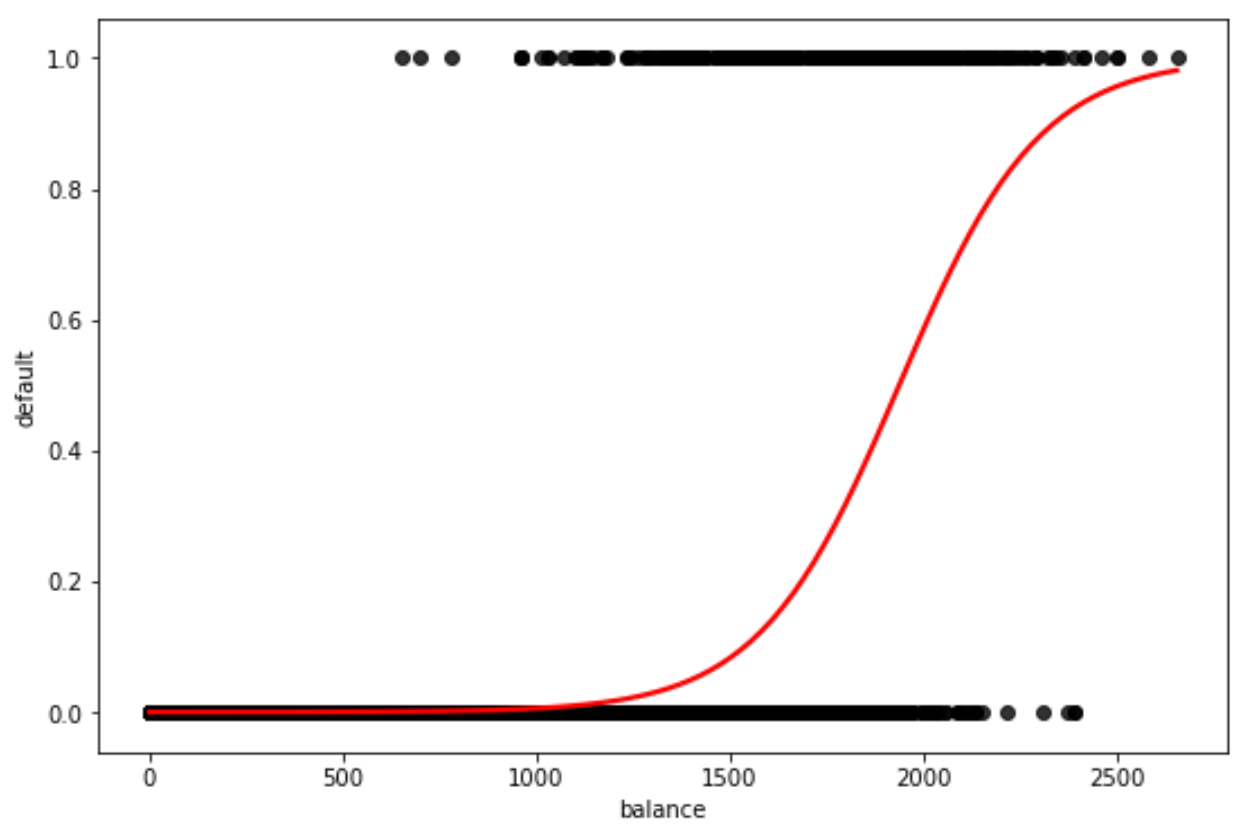
Fühlen Sie sich frei, die Farben zu wählen, die Sie in der Handlung möchten.
Die folgenden Tutorials bieten zusätzliche Informationen zur logistischen Regression:
Einführung in die logistische Regression
So führen Sie eine logistische Regression in Python durch (Schritt für Schritt)
Ein Log-Log-Diagramm ist ein Diagramm, das sowohl auf der x-Achse als auch auf der y-Achse logarithmische Skalen verwendet.
Diese Art von Diagramm ist nützlich, um zwei Variablen zu visualisieren, wenn …
Bei der Verwendung von Klassifizierungsmodellen beim maschinellen Lernen verwenden wir häufig zwei Metriken, um die Qualität des Modells zu bewerten, nämlich Präzision und Erinnerung.
Precision: Korrigieren Sie positive Vorhersagen im …