
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Eine Dummy-Variable ist ein Variablentyp, den wir in der Regressionsanalyse erstellen, damit wir eine kategoriale Variable als numerische Variable darstellen können, die einen von zwei Werten annimmt: null oder eins.
Angenommen, wir haben den folgenden Datensatz und möchten das Alter und den Familienstand zur Vorhersage des Einkommens verwenden:
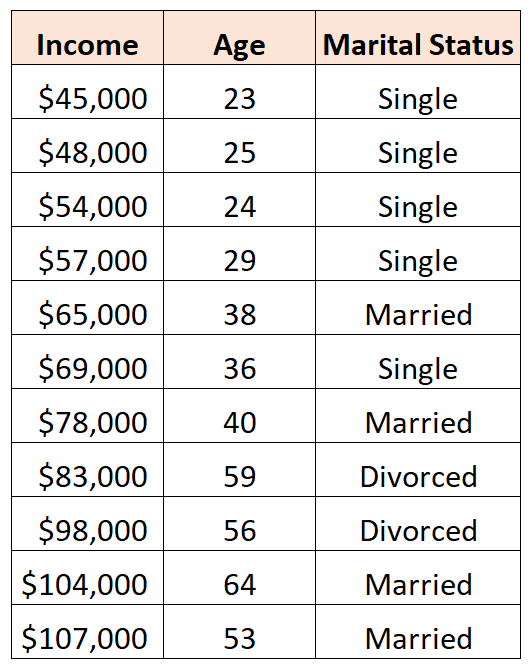
Um den Familienstand als Prädiktorvariable in einem Regressionsmodell zu verwenden, müssen wir ihn in eine Dummy-Variable umwandeln.
Da es sich derzeit um eine kategoriale Variable handelt, die drei verschiedene Werte annehmen kann („Single“, „Verheiratet“ oder „Geschieden“), müssen wir k -1 = 3-1 = 2 Dummy-Variablen erstellen.
Um diese Dummy-Variable zu erstellen, können wir „Single“ als Basiswert verwenden, da dies am häufigsten vorkommt. So würden wir den Familienstand in Dummy-Variablen umwandeln:
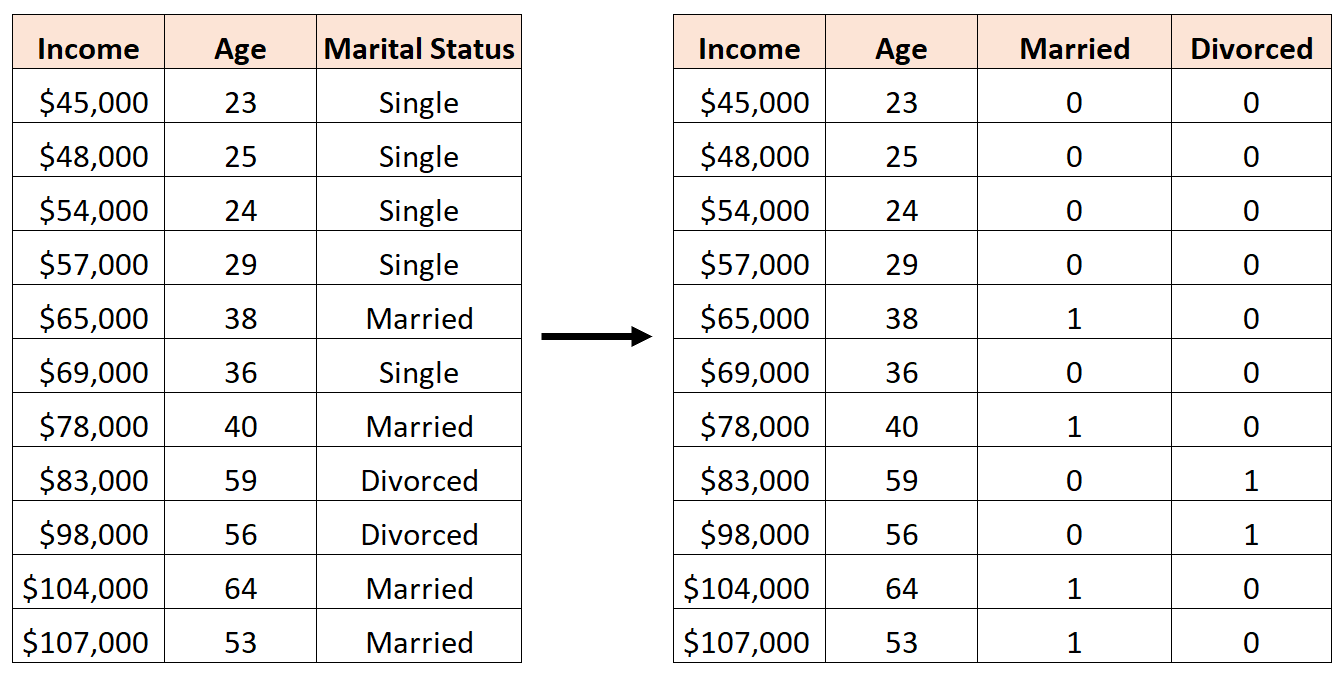
Dieses Tutorial bietet ein schrittweises Beispiel dafür, wie Sie Dummy-Variablen für genau diesen Datensatz in Excel erstellen und dann eine Regressionsanalyse mit diesen Dummy-Variablen als Prädiktoren durchführen.
Zuerst erstellen wir den Datensatz in Excel:
Als nächstes können wir die Werte in den Spalten A und B in die Spalten E und F kopieren und dann die WENN()-Funktion in Excel verwenden, um zwei neue Dummy-Variablen zu definieren: Verheiratet und Geschieden.
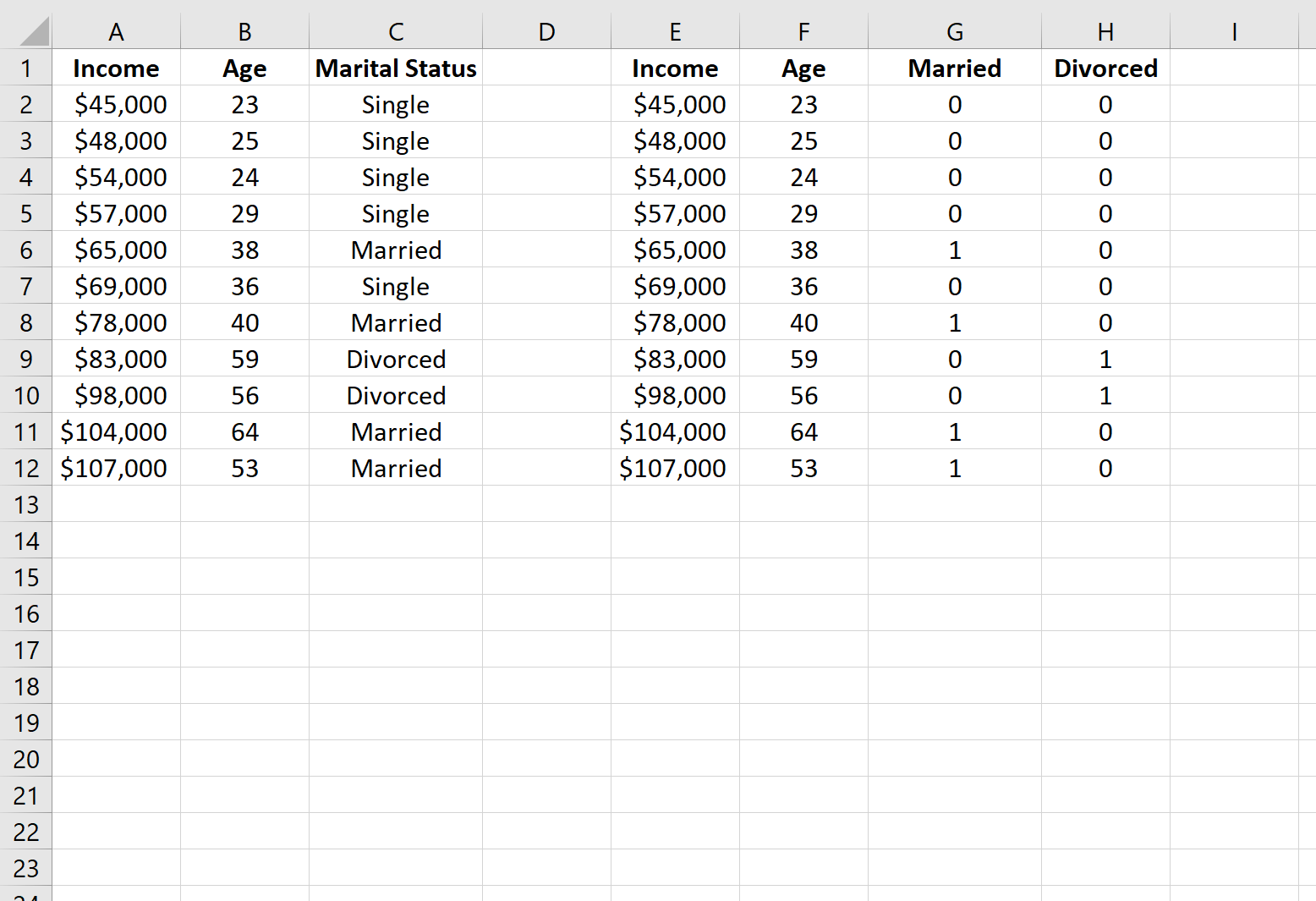
Hier ist die Formel, die wir in Zelle G2 verwendet haben und die wir in die restlichen Zellen in Spalte G kopiert haben:
=WENN(C2 = "Married", 1, 0)
Und hier ist die Formel, die wir in Zelle H2 verwendet haben und die wir in die restlichen Zellen in Spalte H kopiert haben:
=WENN(C2 = "Divorced", 1, 0)
Als Nächstes können wir diese Dummy-Variablen in einem Regressionsmodell verwenden, um das Einkommen vorherzusagen.
Um mehrere lineare Regression durchführen, müssen wir auf die Registerkarte Daten entlang der oberen Band klicken, dann Datenanalyse im Abschnitt Analyse:
Wenn diese Option nicht verfügbar ist, müssen Sie zuerst das Analysis Toolpak laden.
Klicken Sie im angezeigten Fenster auf Regression und dann auf OK.
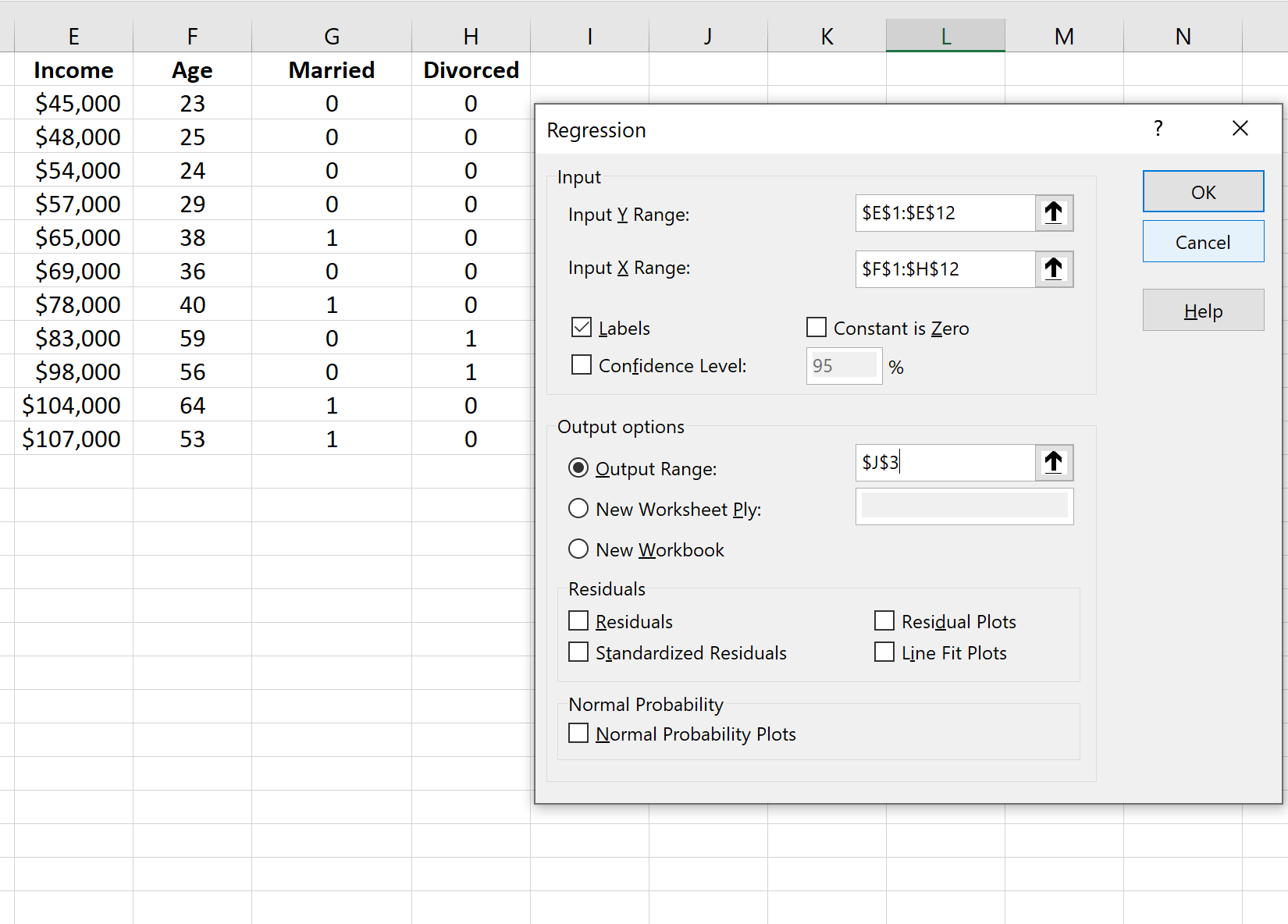
Geben Sie als Nächstes die folgenden Informationen ein und klicken Sie dann auf OK.
Dies erzeugt die folgende Ausgabe:
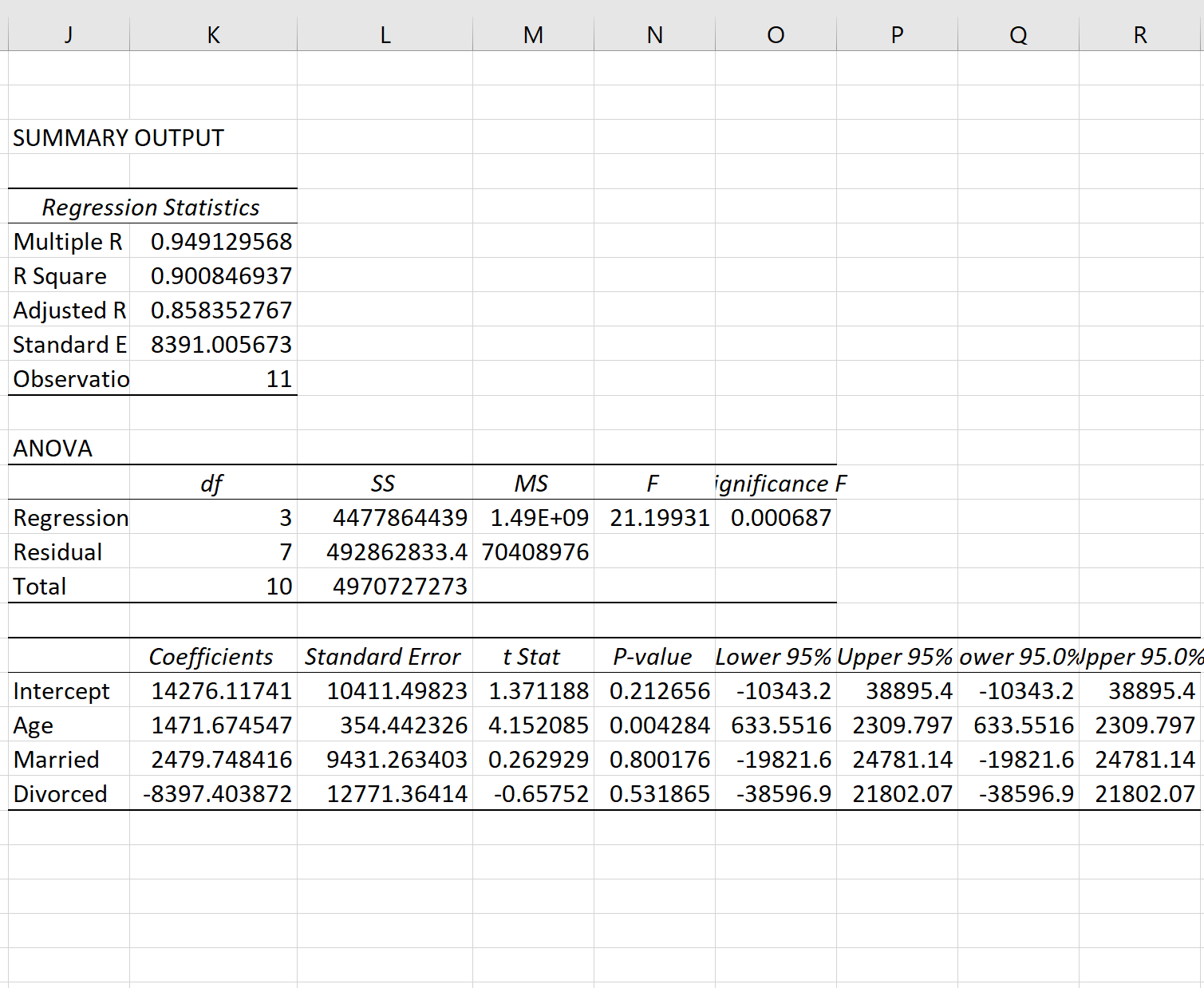
Aus der Ausgabe können wir sehen, dass die angepasste Regressionsgerade ist:
Income = 14,276.12 + 1,471.67*(age) + 2,479.75*(married) – 8,397.40*(divorced)
Wir können diese Gleichung verwenden, um das geschätzte Einkommen einer Person basierend auf ihrem Alter und Familienstand zu ermitteln. Zum Beispiel wird ein Einkommen von einer 35-jährigen und verheirateten Person auf 68.264 US-Dollar geschätzt:
Income = 14,276.12 + 1,471.67*(35) + 2,479.75*(1) – 8,397.40*(0) = $68,264
So interpretieren Sie die Regressionskoeffizienten aus der Tabelle:
Da beide Dummy-Variablen statistisch nicht signifikant waren, konnten wir marital status als Prädiktor aus dem Modell streichen, da er keinen Vorhersagewert für das Einkommen zu haben scheint.
So führen Sie eine einfache lineare Regression in Excel durch
So berechnen Sie die Residualsumme von Quadraten in Excel
So führen Sie eine polynomielle Regression in Excel durch
So erstellen Sie ein Residualdiagramm in Excel
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …