
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Die logistische Regression ist eine Methode, mit der wir ein Regressionsmodell anpassen, wenn die Antwortvariable binär ist.
In diesem Tutorial wird erläutert, wie Sie eine logistische Regression in SPSS durchführen.
Führen Sie die folgenden Schritte aus, um eine logistische Regression in SPSS für einen Datensatz durchzuführen, der zeigt, ob College-Basketballspieler in die NBA eingezogen wurden (Entwurf: 0 = Nein, 1 = Ja), basierend auf ihren durchschnittlichen Punkten pro Spiel und Divisionsstufe.
Schritt 1: Geben Sie die Daten ein.
Geben Sie zunächst die folgenden Daten ein:
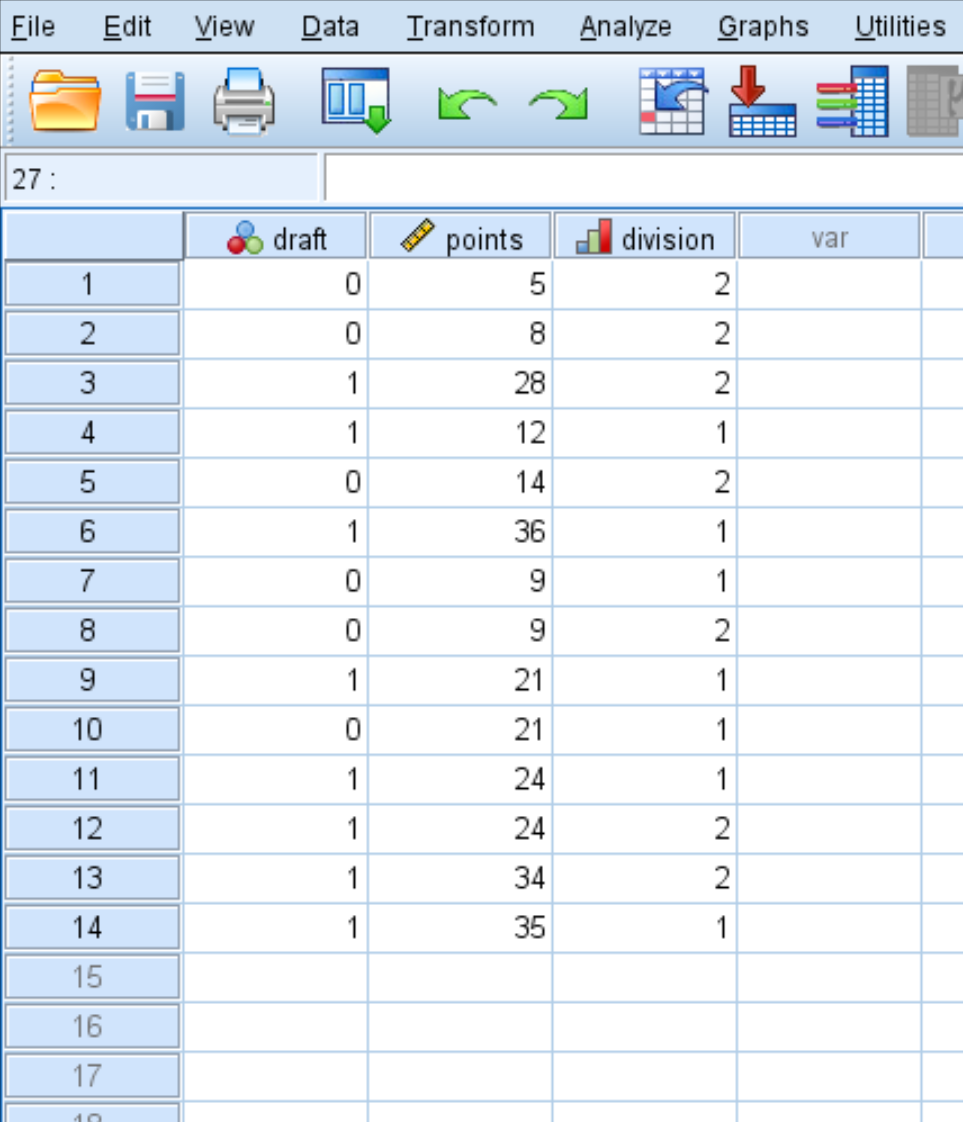
Schritt 2: Führen Sie eine logistische Regression durch.
Klicken Sie auf die Registerkarte Analysieren, dann auf Regression und dann auf Binäre logistische Regression:
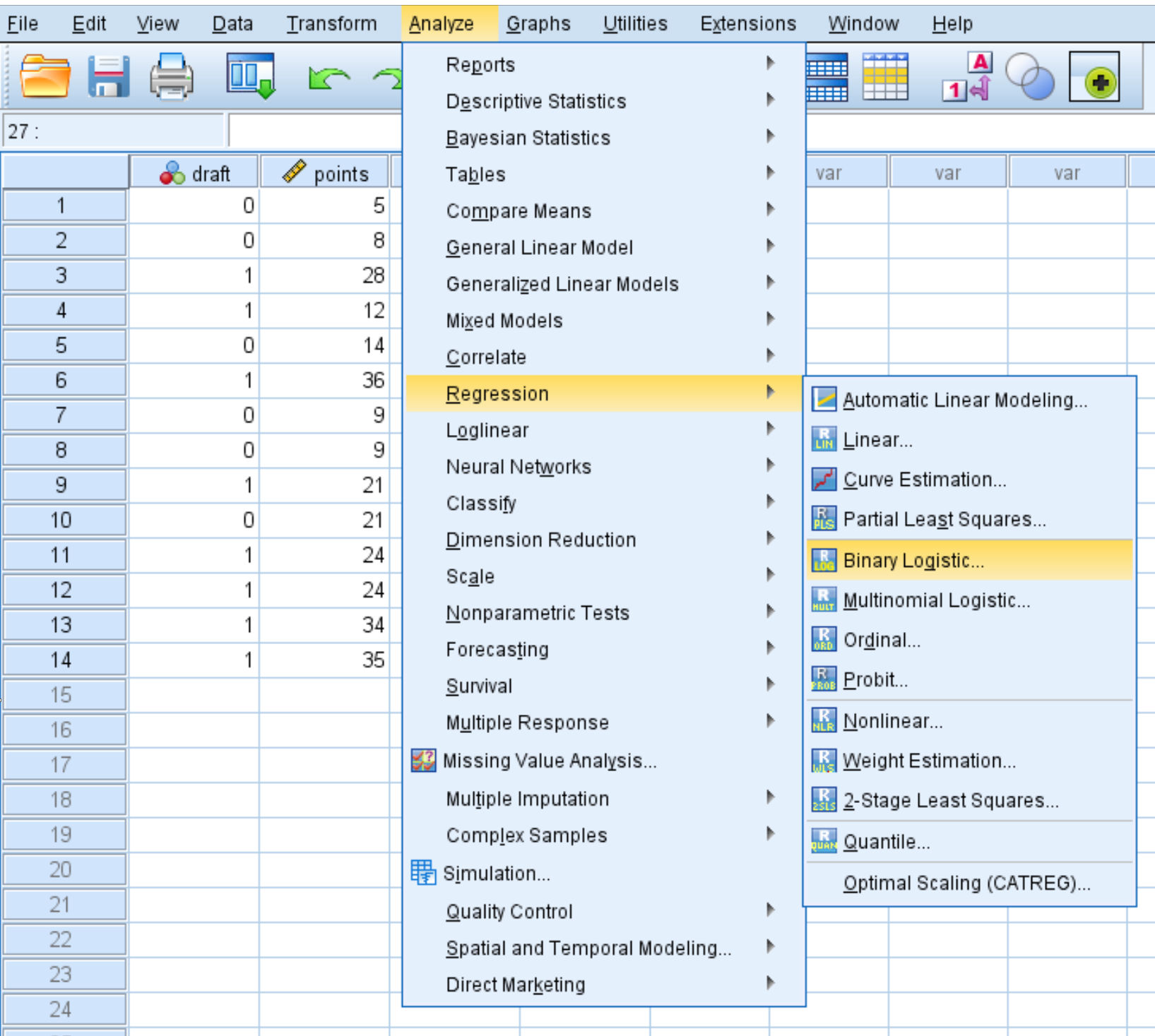
Ziehen Sie im neuen Fenster, das angezeigt wird, den Entwurf der binären Antwortvariablen in das Feld Abhängig. Ziehen Sie dann die beiden Punkte und die Division der Prädiktorvariablen in das Feld mit der Bezeichnung Block 1 von 1. Lassen Sie die Methode auf Enter eingestellt. Klicken Sie dann auf OK.

Schritt 3. Interpretieren Sie die Ausgabe.
Sobald Sie auf OK klicken, wird die Ausgabe der logistischen Regression angezeigt:
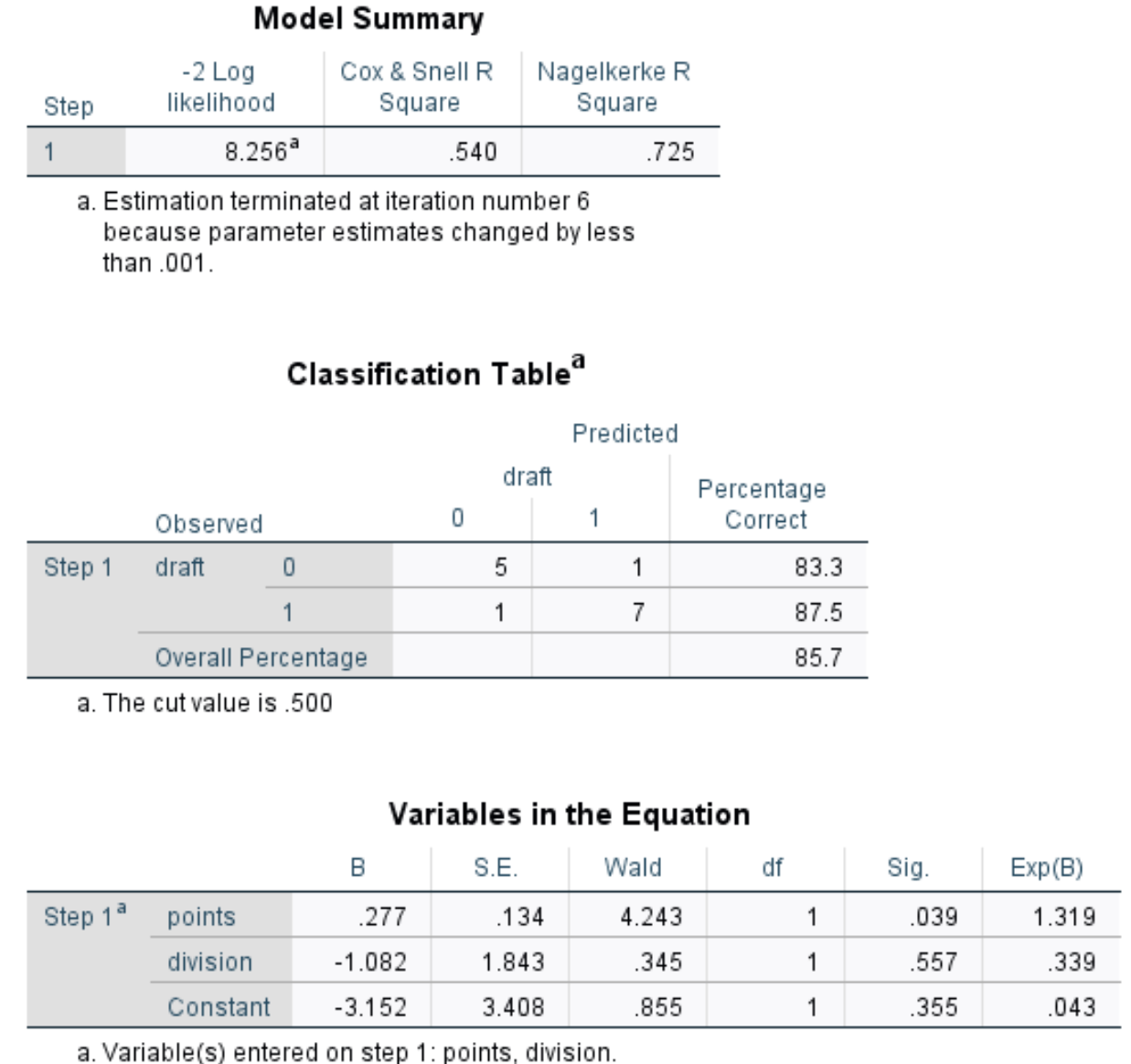
So interpretieren Sie die Ausgabe:
Modellzusammenfassung : Die nützlichste Metrik in dieser Tabelle ist das Nagelkerke R-Quadrat, das den Prozentsatz der Variation der Antwortvariablen angibt, der durch die Prädiktorvariablen erklärt werden kann. In diesem Fall können Punkte und Teilung 72,5% der Variabilität im Entwurf erklären.
Klassifizierungstabelle: Die nützlichste Metrik in dieser Tabelle ist der Gesamtprozentsatz, der den Prozentsatz der Beobachtungen angibt, die das Modell korrekt klassifizieren konnte. In diesem Fall konnte das logistische Regressionsmodell den Entwurf des Ergebnisses von 85,7% der Spieler korrekt vorhersagen.
Variablen in der Gleichung: Diese letzte Tabelle enthält einige nützliche Metriken, darunter:
Wir können dann die Koeffizienten (die Werte in der Spalte mit der Bezeichnung B) verwenden, um die Wahrscheinlichkeit vorherzusagen, dass ein bestimmter Spieler eingezogen wird, indem wir die folgende Formel verwenden:
Wahrscheinlichkeit = e -3,152 + 0,277 (Punkte) – 1,082 (Division) / (1 + e -3,152 + 0,277 (Punkte) – 1,082 (Division) )
Zum Beispiel kann die Wahrscheinlichkeit, dass ein Spieler, der durchschnittlich 20 Punkte pro Spiel erzielt und in Division 1 spielt, eingezogen wird, wie folgt berechnet werden:
Wahrscheinlichkeit = e -3,152 + 0,277 (20) – 1,082 (1) / (1 + e -3,152 + 0,277 (20) – 1,082 (1) ) = 0,787.
Da diese Wahrscheinlichkeit größer als 0,5 ist, würden wir vorhersagen, dass dieser Spieler eingezogen wird.
Schritt 4. Ergebnisse.
Zuletzt möchten wir die Ergebnisse unserer logistischen Regression melden. Hier ist ein Beispiel dafür:
Eine logistische Regression wurde durchgeführt, um zu bestimmen, wie sich Punkte pro Spiel und Divisionsstufe auf die Wahrscheinlichkeit eines Basketballspielers auswirken, eingezogen zu werden. Insgesamt wurden 14 Spieler in die Analyse einbezogen.
Das Modell erklärte 72,5% der Abweichungen im Entwurf des Ergebnisses und klassifizierte 85,7% der Fälle korrekt.
Die Wahrscheinlichkeit, dass ein Spieler in Division 2 eingezogen wird, betrug nur 0,339 der Wahrscheinlichkeit, dass ein Spieler in Division 1 eingezogen wird.
Jede zusätzliche Erhöhung der Punkte pro Spiel um eine Einheit war mit einer Erhöhung der Wahrscheinlichkeit eines eingezogenen Spielers um 1,319 verbunden.
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …