
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Die multiple lineare Regression ist eine Methode, mit der wir die Beziehung zwischen zwei oder mehr erklärenden Variablen und einer Antwortvariablen verstehen können.
In diesem Tutorial wird erläutert, wie Sie in SPSS eine multiple lineare Regression durchführen.
Angenommen, wir möchten wissen, ob die Anzahl der Stunden des Studiums und die Anzahl der vorbereiteten Prüfungen die Punktzahl beeinflusst, die ein Schüler für eine bestimmte Prüfung erhält. Um dies zu untersuchen, können wir mithilfe der folgenden Variablen mehrere lineare Regressionen durchführen:
Erklärende Variablen:
Antwortvariable:
Führen Sie die folgenden Schritte aus, um diese multiple lineare Regression in SPSS durchzuführen.
Schritt 1: Geben Sie die Daten ein.
Geben Sie die folgenden Daten für die Anzahl der Stunden, die vorbereiteten Prüfungen und die Prüfungsergebnisse für 20 Studenten ein:
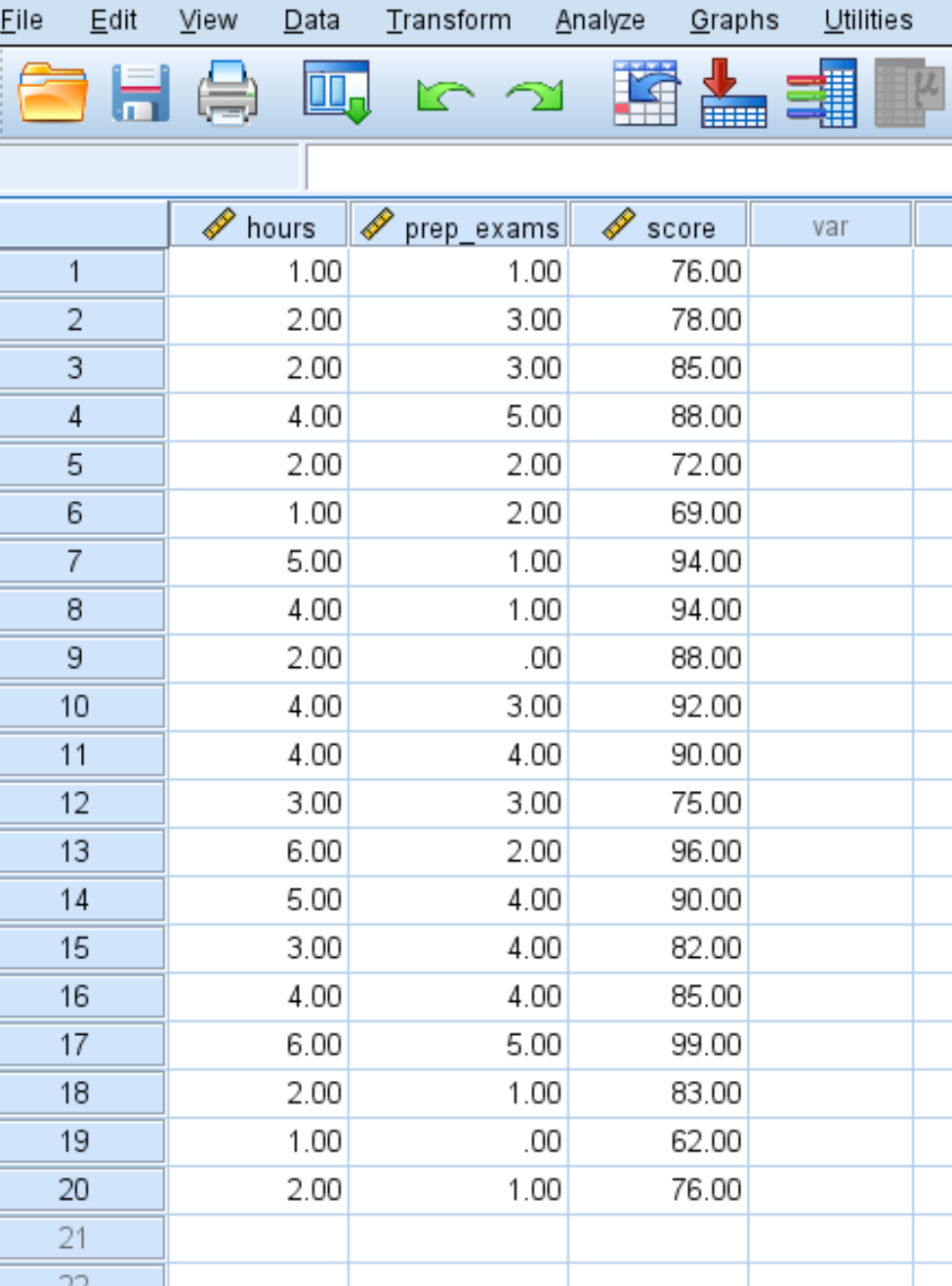
Schritt 2: Führen Sie eine multiple lineare Regression durch.
Klicken Sie auf die Registerkarte Analysieren, dann auf Regression und dann auf Linear:
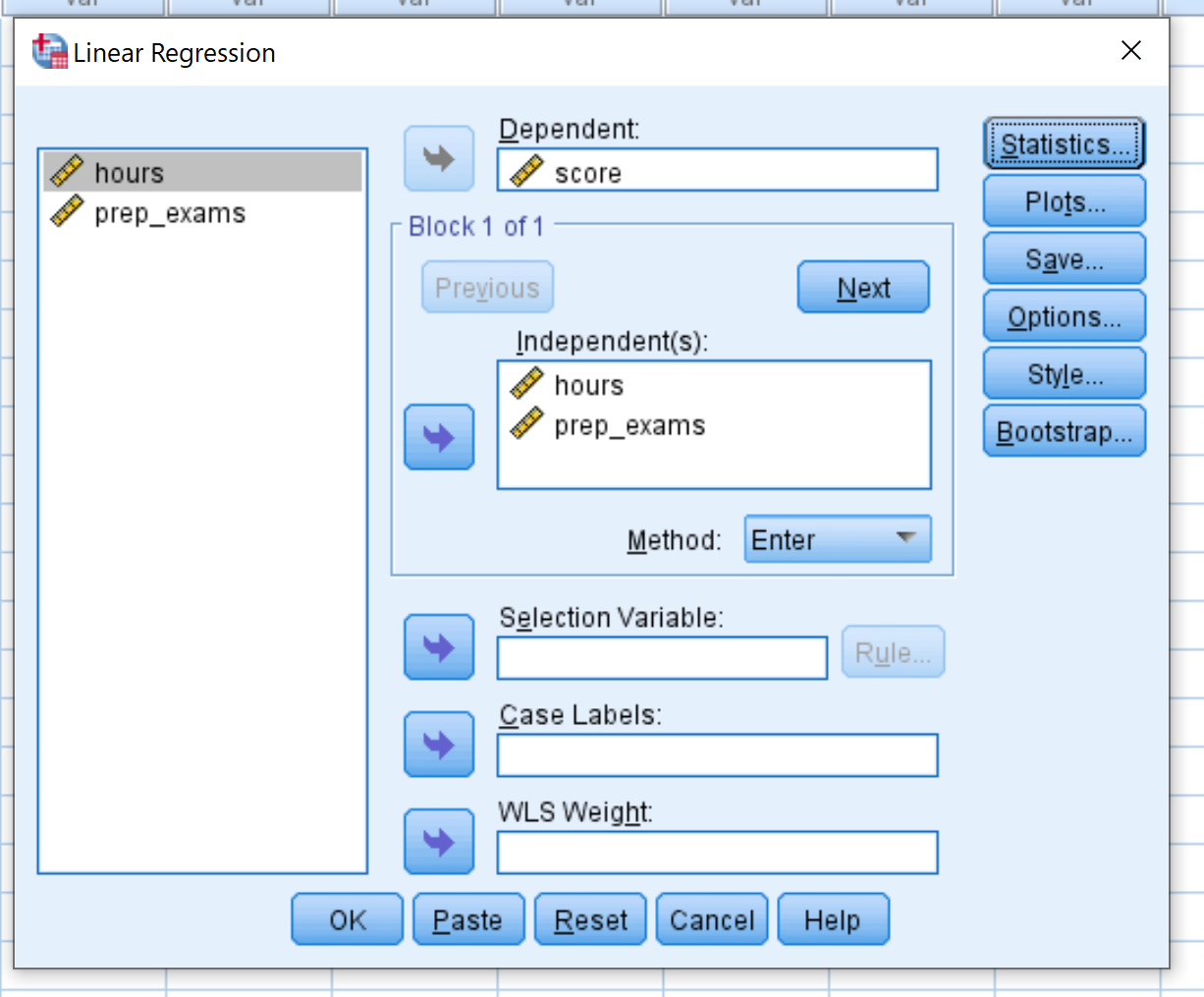
Ziehen Sie die Variable score in das Feld Abhängig. Ziehen Sie die Variablen hours und prep_exams in das Feld Unabhängige(n). Klicken Sie dann auf OK.
Schritt 3: Interpretieren Sie die Ausgabe.
Sobald Sie auf OK klicken, werden die Ergebnisse der multiplen linearen Regression in einem neuen Fenster angezeigt.
Die erste Tabelle, die uns interessiert, trägt den Titel Model Summary:

So interpretieren Sie die wichtigsten Zahlen in dieser Tabelle:
Die nächste Tabelle an der wir interessiert sind trägt den Titel ANOVA:
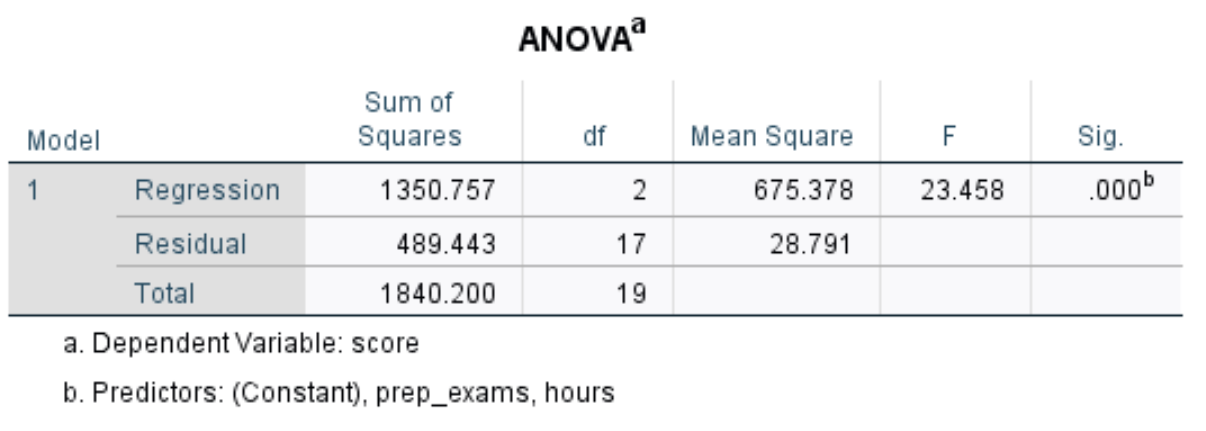
So interpretieren Sie die wichtigsten Zahlen in dieser Tabelle:
Die nächste Tabelle, die uns interessiert, trägt den Titel Coefficients:
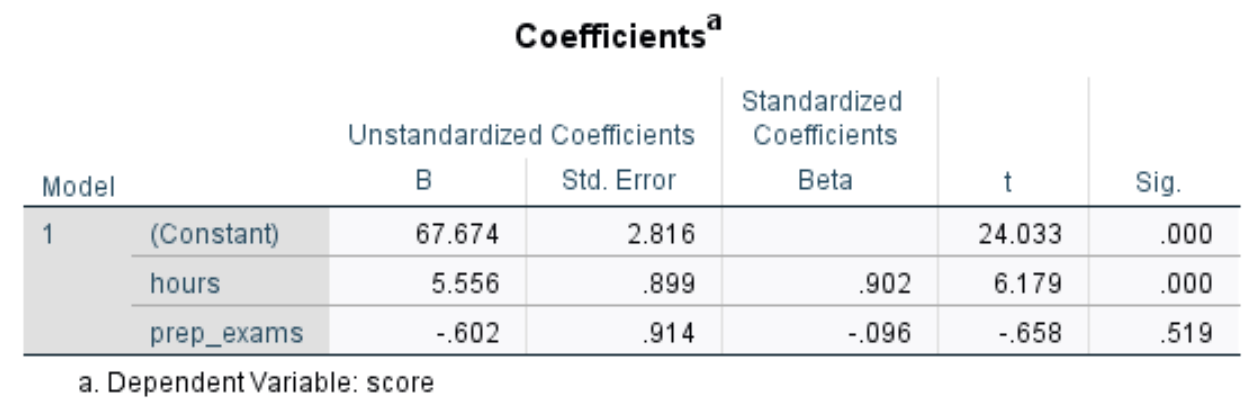
So interpretieren Sie die wichtigsten Zahlen in dieser Tabelle:
Zuletzt können wir eine Regressionsgleichung unter Verwendung der in der Tabelle angegebenen Werte für constant, hours und prep_exams bilden. In diesem Fall wäre die Gleichung:
Geschätzte Prüfungspunktzahl = 67,674 + 5,556 * (hours) – 0,602 * (prep_exams)
Wir können diese Gleichung verwenden, um die geschätzte Prüfungspunktzahl für einen Schüler zu ermitteln, basierend auf der Anzahl der Stunden, die er studiert hat, und der Anzahl der Vorbereitungsprüfungen, die er abgelegt hat. Beispielsweise wird von einem Studenten, der 3 Stunden studiert und 2 Vorbereitungsprüfungen ablegt, eine Prüfungsnote von 83,1 erwartet:
Geschätzte Prüfungspunktzahl = 67,674 + 5,556 * (3) – 0,602 * (2) = 83,1
Hinweis:* Da festgestellt wurde, dass die Vorbereitungsprüfungen für erklärende Variablen statistisch nicht signifikant sind, können wir sie aus dem Modell entfernen und stattdessen eine einfache lineare Regression unter Verwendung der untersuchten Stunden* als einzige erklärende Variable durchführen.
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …