
Ein Mann-Kendall-Trendtest wird verwendet, um festzustellen, ob in Zeitreihendaten ein Trend vorhanden ist oder nicht. Es ist ein nichtparametrischer Test, was bedeutet, dass keine zugrunde liegende Annahme über die Normalität …
Der Shapiro-Wilk-Test ist ein Test der Normalität. Es wird verwendet, um zu bestimmen, ob eine Probe aus einer Normalverteilung stammt oder nicht.
Diese Art von Test ist nützlich, um festzustellen, ob ein bestimmter Datensatz aus einer Normalverteilung stammt oder nicht. Dies ist eine häufige Annahme, die in vielen statistischen Tests verwendet wird, einschließlich Regression, ANOVA, t-Tests und vielen anderen.
Mit der folgenden in R integrierten Funktion können wir problemlos einen Shapiro-Wilk-Test für einen bestimmten Datensatz durchführen:
shapiro.test(x)
wo:
- x: Ein numerischer Vektor von Datenwerten.
Diese Funktion erzeugt eine Teststatistik W zusammen mit einem entsprechenden p-Wert. Wenn der p-Wert kleiner als α = 0,05 ist, gibt es genügend Hinweise darauf, dass die Stichprobe nicht aus einer normalverteilten Population stammt.
Hinweis: Die Stichprobengröße muss zwischen 3 und 5.000 liegen, um die Funktion shapiro.test() verwenden zu können.
Dieses Tutorial zeigt einige Beispiele für die praktische Verwendung dieser Funktion.
Beispiel 1: Shapiro-Wilk-Test an normalen Daten
Der folgende Code zeigt, wie ein Shapiro-Wilk-Test an einem Datensatz mit der Stichprobengröße n = 100 durchgeführt wird:
#Machen Sie dieses Beispiel reproduzierbar
set.seed (0)
#Erstellen Sie einen Datensatz mit 100 zufälligen Werten, die aus einer Normalverteilung generiert wurden
data <- rnorm(100)
#Shapiro-Wilk-Test auf Normalität durchführen
shapiro.test(data)
Shapiro-Wilk normality test
data: data
W = 0.98957, p-value = 0.6303
Der p-Wert des Tests beträgt 0,6303. Da dieser Wert nicht kleiner als 0,05 ist, können wir davon ausgehen, dass die Beispieldaten aus einer Population stammen, die normal verteilt ist.
Dieses Ergebnis sollte nicht überraschen, da wir die Beispieldaten mit der Funktion rnorm() generiert haben, die Zufallswerte aus einer Normalverteilung mit Mittelwert = 0 und Standardabweichung = 1 generiert.
Verwandt: Ein Leitfaden für dnorm, pnorm, qnorm und rnorm in R
Wir können auch ein Histogramm erstellen, um visuell zu überprüfen, ob die Probendaten normal verteilt sind:
hist(data, col='steelblue')
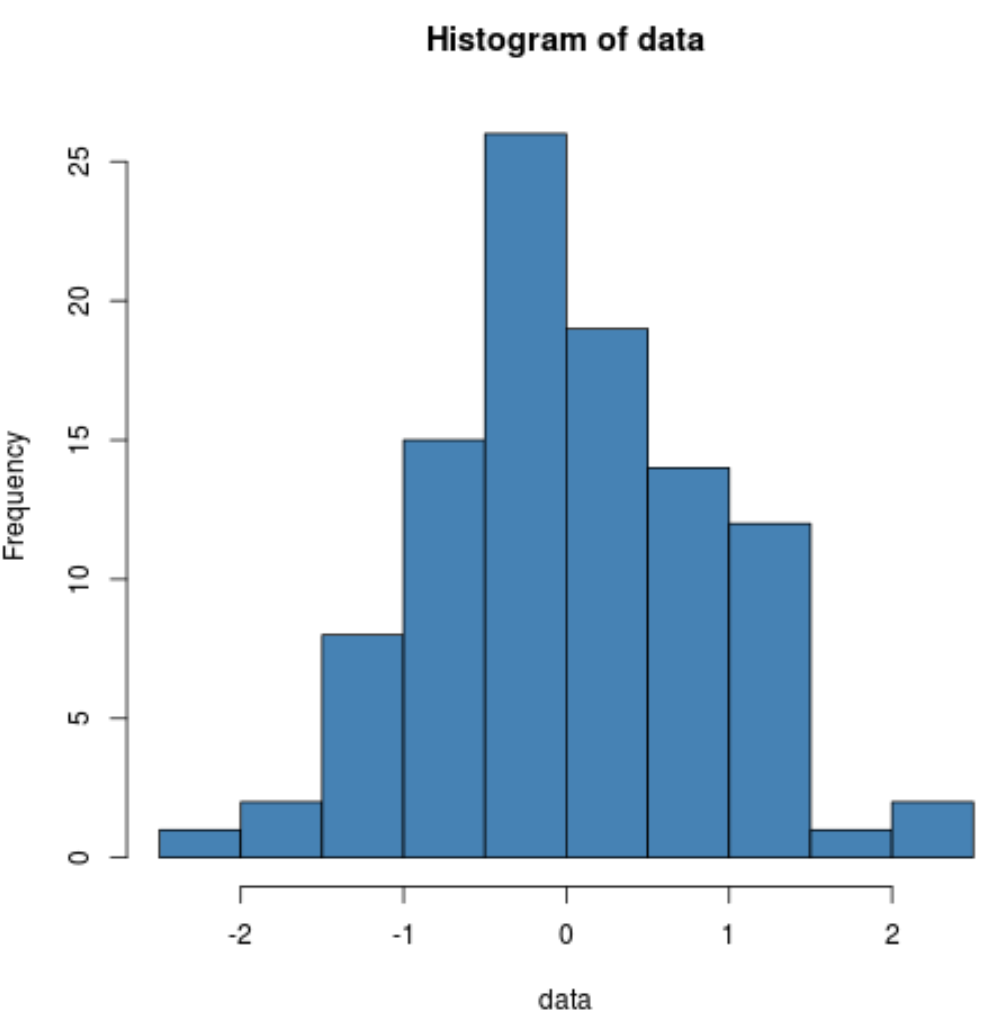
Wir können sehen, dass die Verteilung ziemlich glockenförmig ist und einen Peak in der Mitte der Verteilung aufweist, was typisch für normal verteilte Daten ist.
Beispiel 2: Shapiro-Wilk-Test an nicht normalen Daten
Der folgende Code zeigt, wie ein Shapiro-Wilk-Test an einem Datensatz mit der Stichprobengröße n = 100 durchgeführt wird, bei dem die Werte zufällig aus einerPoisson-Verteilung generiert werden:
#Machen Sie dieses Beispiel reproduzierbar
set.seed(0)
#Erstellen Sie einen Datensatz mit 100 zufälligen Werten, die aus einer Poisson-Verteilung generiert wurden
data <- rpois(n=100, lambda=3)
# Shapiro-Wilk-Test auf Normalität durchführen
shapiro.test(data)
Shapiro-Wilk normality test
data: data
W = 0.94397, p-value = 0.0003393
Der p-Wert des Tests beträgt 0,0003393. Da dieser Wert kleiner als 0,05 ist, haben wir genügend Beweise dafür, dass die Probendaten nicht aus einer normalverteilten Population stammen.
Dieses Ergebnis sollte nicht überraschen, da wir die Beispieldaten mit der Funktion rpois() generiert haben, die Zufallswerte aus einer Poisson-Verteilung generiert.
Verwandt: Ein Leitfaden für dpois, ppois, qpois und rpois in R
Wir können auch ein Histogramm erstellen, um visuell zu sehen, dass die Probendaten nicht normal verteilt sind:
hist(data, col='coral2')

Wir können sehen, dass die Verteilung rechtwinklig ist und nicht die typische „Glockenform“ aufweist, die mit einer Normalverteilung verbunden ist. Somit stimmt unser Histogramm mit den Ergebnissen des Shapiro-Wilk-Tests überein und bestätigt, dass unsere Probendaten nicht aus einer Normalverteilung stammen.
Was tun mit nicht normalverteilten Daten?
Wenn ein bestimmter Datensatz nicht normal verteilt ist, können wir häufig eine der folgenden Transformationen durchführen, um ihn "normalverteilter" zu machen:
1. Protokolltransformation: Transformieren Sie die Antwortvariable von y in log(y).
2. Quadratwurzel-Transformation: Transformieren Sie die Antwortvariable von y nach √y.
3. Kubikwurzel-Transformation: Transformieren Sie die Antwortvariable von y nach y 1/3.
Durch Ausführen dieser Transformationen nähert sich die Antwortvariable typischerweise der Normalverteilung an. In diesem Tutorial erfahren Sie, wie Sie diese Transformationen in der Praxis durchführen.
Zusätzliche Ressourcen
Wie man einen Anderson-Darling-Test in R durchführt
So führen Sie einen Shapiro-Wilk-Test in Python durch
Shapiro-Wilk Test-Rechner
Das könnte Sie auch interessieren:
So führen Sie einen Mann-Kendall-Trendtest in Python durch
So führen Sie einen Chow-Test in Python durch
Ein Chow-Test wird verwendet, um zu testen, ob die Koeffizienten in zwei verschiedenen Regressionsmodellen auf verschiedenen Datensätzen gleich sind.
Dieser Test wird typischerweise im Bereich der Ökonometrie mit Zeitreihendaten verwendet …