
In der Statistik wird die Gamma-Verteilung häufig verwendet, um Wahrscheinlichkeiten in Bezug auf Wartezeiten zu modellieren.
Die folgenden Beispiele zeigen, wie Sie die Funktion scipy.stats.gamma() verwenden, um eine …
Die Normalverteilung ist die in der Statistik am häufigsten verwendete Verteilung. In diesem Tutorial wird erklärt, wie Sie mit der Normalverteilung in R mithilfe der Funktionen dnorm, pnorm, rnorm und qnorm arbeiten.
Die Funktion dnorm gibt den Wert der Wahrscheinlichkeitsdichtefunktion (pdf) der Normalverteilung bei einer bestimmten Zufallsvariablen x, einem Populationsmittelwert μ und einer Populationsstandardabweichung σ zurück. Die Syntax für die Verwendung von dnorm lautet wie folgt:
dnorm(x, mean, sd)
Der folgende Code zeigt einige Beispiele für dnorm in Aktion:
#Finden Sie den Wert der Standardnormalverteilung pdf bei x = 0
dnorm(x=0, mean=0, sd=1)
# [1] 0.3989423
#Standardmäßig verwendet R mean = 0 und sd = 1
dnorm(x=0)
# [1] 0.3989423
#Finden Sie den Wert der Normalverteilung pdf bei x = 10 mit Mittelwert = 20 und sd = 5dnorm(x=10, mean=20, sd=5)
# [1] 0.01079819
Wenn Sie versuchen, Fragen zur Wahrscheinlichkeit mithilfe der Normalverteilung zu lösen, verwenden Sie normalerweise häufig pnorm anstelle von dnorm. Eine nützliche Anwendung von dnorm ist jedoch das Erstellen eines Normalverteilungsdiagramms in R Der folgende Code veranschaulicht, wie dies getan wird:
#Erstellen Sie eine Folge von 100 gleich beabstandeten Zahlen zwischen -4 und 4
x <- seq(-4, 4, length=100)
#Erstellen Sie einen Wertevektor, der die Höhe der Wahrscheinlichkeitsverteilung anzeigt
#für jeden Wert in x
y <- dnorm(x)
#Plotten Sie x und y als Streudiagramm mit verbundenen Linien (Typ = "l") und addieren Sie
#eine x-Achse mit benutzerdefinierten Beschriftungen
plot(x,y, type = "l", lwd = 2, axes = FALSE, xlab = "", ylab = "")
axis(1, at = -3:3, labels = c("-3s", "-2s", "-1s", "mean", "1s", "2s", "3s"))
Dies erzeugt das folgende Diagramm:
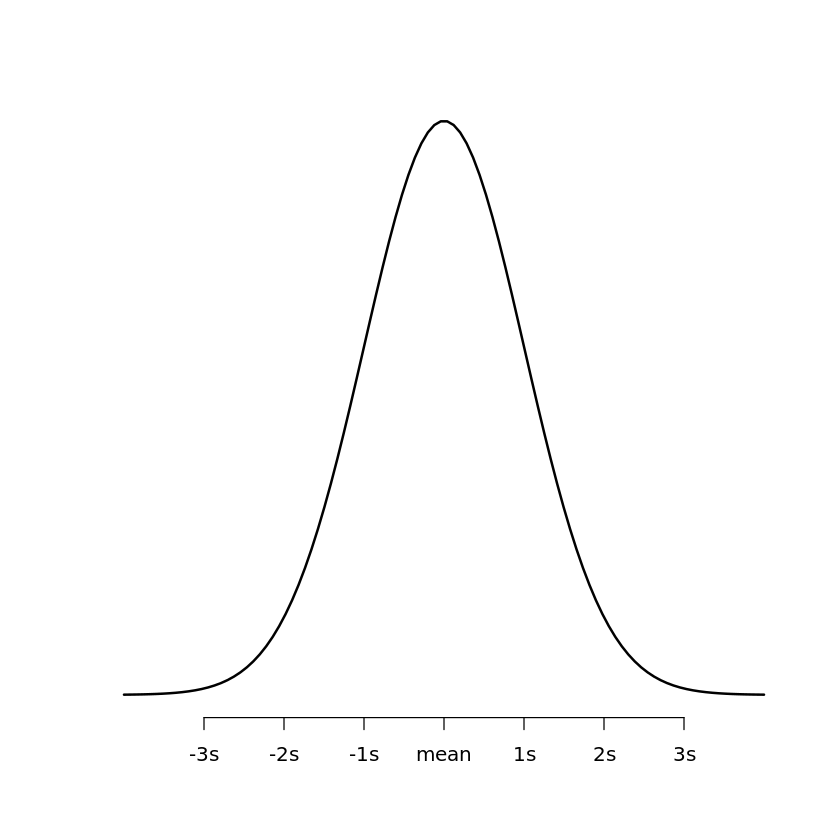
Die Funktion pnorm gibt den Wert der kumulativen Dichtefunktion (cdf) der Normalverteilung bei einer bestimmten Zufallsvariablen q, einem Populationsmittel μ und einer Populationsstandardabweichung σ zurück. Die Syntax für die Verwendung von pnorm lautet wie folgt:
pnorm(q, mean, sd)
Einfach ausgedrückt gibt pnorm den Bereich links von einem bestimmten Wert x in der Normalverteilung zurück. Wenn Sie sich für den Bereich rechts von einem bestimmten Wert q interessieren, können Sie einfach das Argument lower.tail = FALSE hinzufügen
pnorm(q, mean, sd, lower.tail = FALSE)
Die folgenden Beispiele zeigen, wie einige Wahrscheinlichkeitsfragen mit pnorm gelöst werden.
Beispiel 1: Angenommen, die Größe der Männer an einer bestimmten Schule ist normalerweise mit einem Mittelwert von μ = 70 Zoll und einer Standardabweichung von σ = 2 Zoll verteilt. Wie viel Prozent der Männer an dieser Schule sind ungefähr größer als 30 cm?
#Finden Sie den Prozentsatz der Männer, die größer als 74 Zoll in einer Bevölkerung mit sind
#mean = 70 and sd = 2
pnorm(74, mean=70, sd=2, lower.tail=FALSE)
# [1] 0.02275013
An dieser Schule sind 2,275% der Männer größer als 74 Zoll.
Beispiel 2: Angenommen, das Gewicht einer bestimmten Otterart ist normalerweise mit einem Mittelwert von μ = 30 lbs und einer Standardabweichung von σ = 5 lbs verteilt. Wie viel Prozent dieser Otterart wiegen ungefähr 22 Pfund?
#Finden Sie den Prozentsatz der Otter, die weniger als 22 Pfund wiegen in einer Population mit
#mean = 30 und sd = 5
pnorm(22, mean=30, sd=5)
# [1] 0.05479929
Ungefähr 5,4799% dieser Otterarten wiegen weniger als 22 Pfund.
Beispiel 3: Angenommen, die Höhe der Pflanzen in einer bestimmten Region ist normalerweise mit einem Mittelwert von μ = 13 Zoll und einer Standardabweichung von σ = 2 Zoll verteilt. Wie viel Prozent der Pflanzen in dieser Region sind ungefähr 10 bis 14 Zoll groß?
#Finden Sie den Prozentsatz der Pflanzen, die weniger als 14 Zoll groß sind, und subtrahieren Sie dann die
#Prozentsatz der Pflanzen, die weniger als 10 Zoll groß sind, basierend auf einer Population
#with mean = 13 and sd = 2
pnorm(14, mean=13, sd=2) - pnorm(10, mean=13, sd=2)
# [1] 0.6246553
Ungefähr 62,4655% der Pflanzen in dieser Region sind zwischen 10 und 14 Zoll groß.
Die Funktion qnorm gibt den Wert der inversen kumulativen Dichtefunktion (cdf) der Normalverteilung bei einer bestimmten Zufallsvariablen p, einem Populationsmittel μ und einer Populationsstandardabweichung σ zurück. Die Syntax für die Verwendung von qnorm lautet wie folgt:
qnorm(p, mean, sd)
Einfach ausgedrückt, können Sie qnorm verwenden, um herauszufinden, wie hoch der Z-Score des p-ten Quantils der Normalverteilung ist.
Der folgende Code zeigt einige Beispiele für qnorm in Aktion:
#Finden Sie den Z-Score des 99. Quantils der Standardnormalverteilung
qnorm(.99, mean=0, sd=1)
# [1] 2.326348
#Standardmäßig verwendet R mean = 0 und sd = 1
qnorm(.99)
# [1] 2.326348
#Finden Sie den Z-Score des 95. Quantils der Standardnormalverteilung
qnorm(.95)
# [1] 1.644854
#Finden Sie den Z-Score des 10. Quantils der Standardnormalverteilung
qnorm(.10)
# [1] -1.281552
Die Funktion rnorm erzeugt einen Vektor normalverteilter Zufallsvariablen bei einer Vektorlänge n, einem Populationsmittel μ und einer Populationsstandardabweichung σ. Die Syntax für die Verwendung von rnorm lautet wie folgt:
rnorm(n, mean, sd)
Der folgende Code zeigt einige Beispiele für rnorm in Aktion:
#generiere einen Vektor von 5 normalverteilten Zufallsvariablen mit Mittelwert = 10 und sd = 2
five <- rnorm(5, mean = 10, sd = 2)
five
# [1] 10.658117 8.613495 10.561760 11.123492 10.802768
#generiere einen Vektor von 1000 normalverteilten Zufallsvariablen mit Mittelwert = 50 und sd = 5
narrowDistribution <- rnorm(1000, mean = 50, sd = 15)
#generiere einen Vektor von 1000 normalverteilten Zufallsvariablen mit Mittelwert = 50 und sd = 25
wideDistribution <- rnorm(1000, mean = 50, sd = 25)
#Generieren Sie zwei Histogramme, um diese beiden Verteilungen nebeneinander anzuzeigen:
#50 Balken im Histogramm und Grenzwerte für die x-Achse von -50 bis 150
par(mfrow=c(1, 2)) #eine Reihe, zwei Spalten
hist(narrowDistribution, breaks=50, xlim=c(-50, 150))
hist(wideDistribution, breaks=50, xlim=c(-50, 150))
Dies erzeugt die folgenden Histogramme:
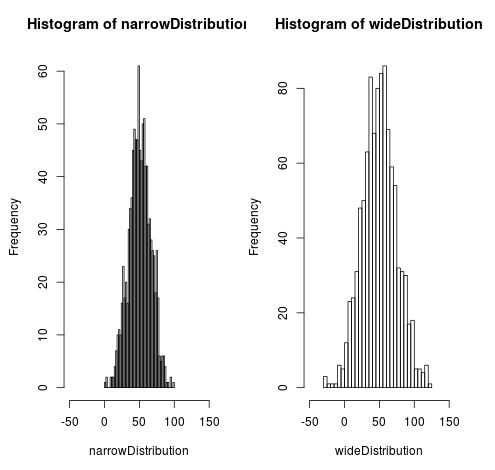
Beachten Sie, dass die weite Verteilung im Vergleich zur engen Verteilung viel weiter verteilt ist. Dies liegt daran, dass wir die Standardabweichung in der breiten Verteilung mit 25 angegeben haben, verglichen mit nur 15 in der engen Verteilung. Beachten Sie auch, dass beide Histogramme um den Mittelwert von 50 zentriert sind.
In der Statistik wird die Gamma-Verteilung häufig verwendet, um Wahrscheinlichkeiten in Bezug auf Wartezeiten zu modellieren.
Die folgenden Beispiele zeigen, wie Sie die Funktion scipy.stats.gamma() verwenden, um eine …
Eine Gleichverteilung ist eine Wahrscheinlichkeitsverteilung, bei der jeder Wert zwischen einem Intervall von a bis b mit gleicher Wahrscheinlichkeit gewählt wird.
Die Wahrscheinlichkeit, dass wir auf einem Intervall von a …