
Ein Mann-Kendall-Trendtest wird verwendet, um festzustellen, ob in Zeitreihendaten ein Trend vorhanden ist oder nicht. Es ist ein nichtparametrischer Test, was bedeutet, dass keine zugrunde liegende Annahme über die Normalität …
Ein Chow-Test wird verwendet, um zu testen, ob die Koeffizienten in zwei verschiedenen Regressionsmodellen auf verschiedenen Datensätzen gleich sind.
Dieser Test wird typischerweise im Bereich der Ökonometrie mit Zeitreihendaten verwendet, um festzustellen, ob an irgendeiner Stelle ein Strukturbruch in den Daten vorliegt.
Das folgende Schritt-für-Schritt-Beispiel zeigt, wie Sie einen Chow-Test in Python durchführen.
Schritt 1: Erstellen Sie die Daten
Zuerst erstellen wir einige gefälschte Daten:
import pandas as pd
#Dataframe erstellen
df = pd.DataFrame({'x': [1, 1, 2, 3, 4, 4, 5, 5, 6, 7, 7, 8, 8, 9, 10, 10,
11, 12, 12, 13, 14, 15, 15, 16, 17, 18, 18, 19, 20, 20],
'y': [3, 5, 6, 10, 13, 15, 17, 14, 20, 23, 25, 27, 30, 30, 31,
33, 32, 32, 30, 32, 34, 34, 37, 35, 34, 36, 34, 37, 38, 3
#erste fünf Zeilen von DataFrame anzeigen
df.head()
x y
0 1 3
1 1 5
2 2 6
3 3 10
4 4 13
Schritt 2: Visualisieren Sie die Daten
Als Nächstes erstellen wir ein einfaches Streudiagramm, um die Daten zu visualisieren:
import matplotlib.pyplot as plt
#Streudiagramm erstellen
plt.plot(df.x, df.y, 'o')
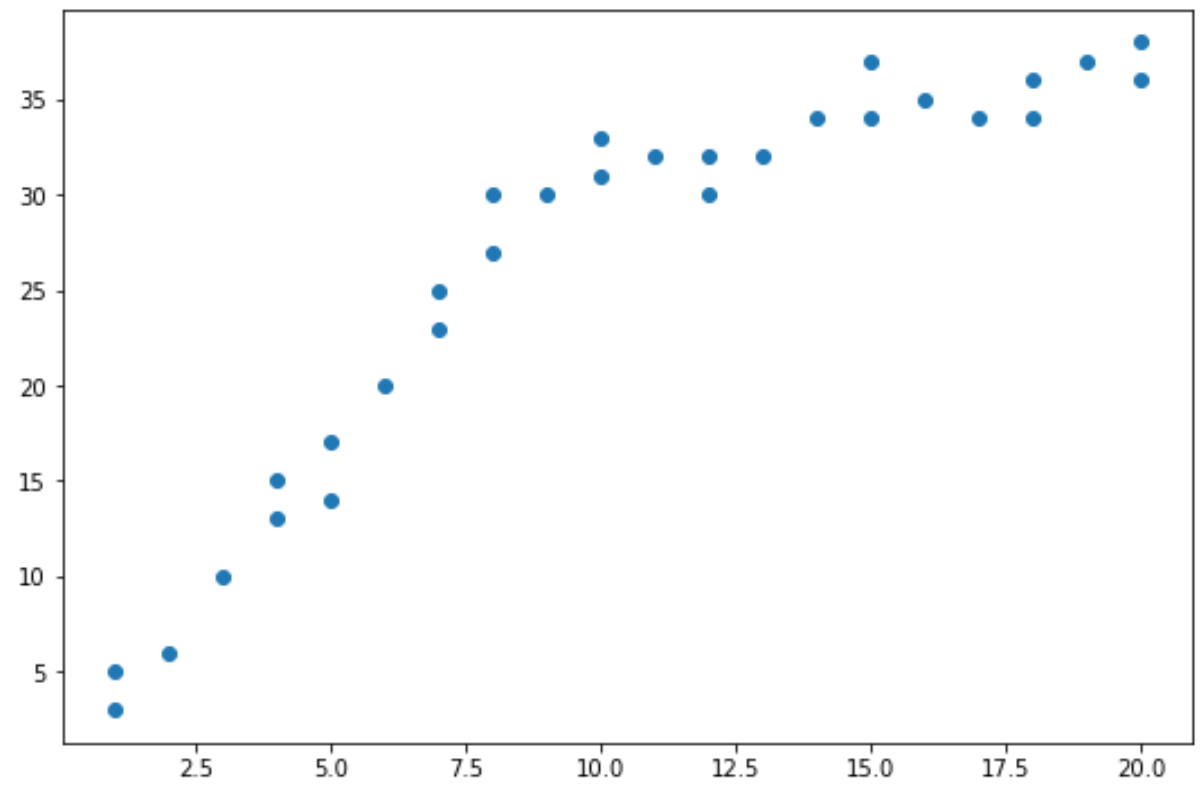
Aus dem Streudiagramm können wir sehen, dass sich das Muster in den Daten bei x = 10 zu ändern scheint.
Daher können wir den Chow-Test durchführen, um festzustellen, ob es bei x = 10 einen strukturellen Bruchpunkt in den Daten gibt.
Schritt 3: Führen Sie den Chow-Test durch
Wir können die chowtest-Funktion aus dem chowtest- Paket in Python verwenden, um einen Chow-Test durchzuführen.
Zuerst müssen wir dieses Paket mit pip installieren:
pip install chowtest
Als nächstes können wir die folgende Syntax verwenden, um den Chow-Test durchzuführen:
from chow_test import chowtest
chowtest(y=df[['y']], X=df[['x']],
last_index_in_model_1=15,
first_index_in_model_2=16,
significance_level=.05)
***********************************************************************************
Reject the null hypothesis of equality of regression coefficients in the 2 periods.
***********************************************************************************
Chow Statistic: 118.14097335479373 p value: 0.0
***********************************************************************************
(118.14097335479373, 1.1102230246251565e-16)
So bedeuten die einzelnen Argumente in der Funktion chowtest():
- y: Die Antwortvariable im DataFrame
- x: Die Prädiktorvariable im DataFrame
- last_index_in_model_1: Der Indexwert für den letzten Punkt vor dem Strukturbruch
- first_index_in_model_2: Der Indexwert für den ersten Punkt nach dem Strukturbruch
- significance_level: Das für den Hypothesentest zu verwendende Signifikanzniveau
Aus der Ausgabe des Tests können wir sehen:
- F test statistic: 118,14
- p-value: <.0000
Da der p-Wert kleiner als 0,05 ist, können wir die Nullhypothese des Tests ablehnen. Dies bedeutet, dass wir genügend Beweise haben, um zu sagen, dass in den Daten eine strukturelle Bruchstelle vorhanden ist.
Mit anderen Worten, zwei Regressionslinien passen das Muster in den Daten besser an als eine einzelne Regressionslinie.
Zusätzliche Ressourcen
Die folgenden Tutorials erklären, wie Sie andere gängige Tests in Python durchführen:
So führen Sie einen Granger-Kausalitätstest in Python durch
So führen Sie einen Breusch-Pagan-Test in Python durch
Eine Erklärung von P-Werten und der statistischen Signifikanz
Das könnte Sie auch interessieren:
So führen Sie einen Mann-Kendall-Trendtest in Python durch
So führen Sie einen Granger-Kausalitätstest in Python durch
Der Granger-Kausalitätstest wird verwendet, um festzustellen, ob eine Zeitreihe für die Vorhersage einer anderen nützlich ist oder nicht.
Dieser Test verwendet die folgenden Null- und Alternativhypothesen:
Nullhypothese (H 0 ): Die …