
Der einfachste Weg, Arrays in Python zu verketten, ist die Verwendung der Funktion numpy.concatenate, die die folgende Syntax verwendet:
numpy.concatenate((a1, a2, ….), axis = 0)
wo:
- a1, a2 …: Die …
Mit der Funktion rnorm(), die die folgende Syntax verwendet, können Sie schnell eine Normalverteilung in R generieren:
rnorm(n, mean=0, sd=1)
wo:
Dieses Tutorial zeigt ein Beispiel für die Verwendung dieser Funktion zum Generieren einer Normalverteilung in R.
Verwandt: Ein Leitfaden für dnorm, pnorm, qnorm und rnorm in R
Der folgende Code zeigt, wie eine Normalverteilung in R generiert wird:
#Machen Sie dieses Beispiel reproduzierbar
set.seed (1)
# Probe von 200 Beobachtungen generieren. das der Normalverteilung folgt mit Mittelwert = 10 und sd = 3
data <- rnorm(200, mean=10, sd=3)
# Die ersten 6 Beobachtungen in der Stichprobe anzeigen
head(data)
[1] 8.120639 10.550930 7.493114 14.785842 10.988523 7.538595
Wir können schnell den Mittelwert und die Standardabweichung dieser Verteilung finden:
# Mittelwert der Stichprobe finden
mean(data)
[1] 10.10662
# Standardabweichung der Probe finden
sd(data)
[1] 2.787292
Wir können auch ein schnelles Histogramm erstellen, um die Verteilung der Datenwerte zu visualisieren:
hist(data, col='steelblue')
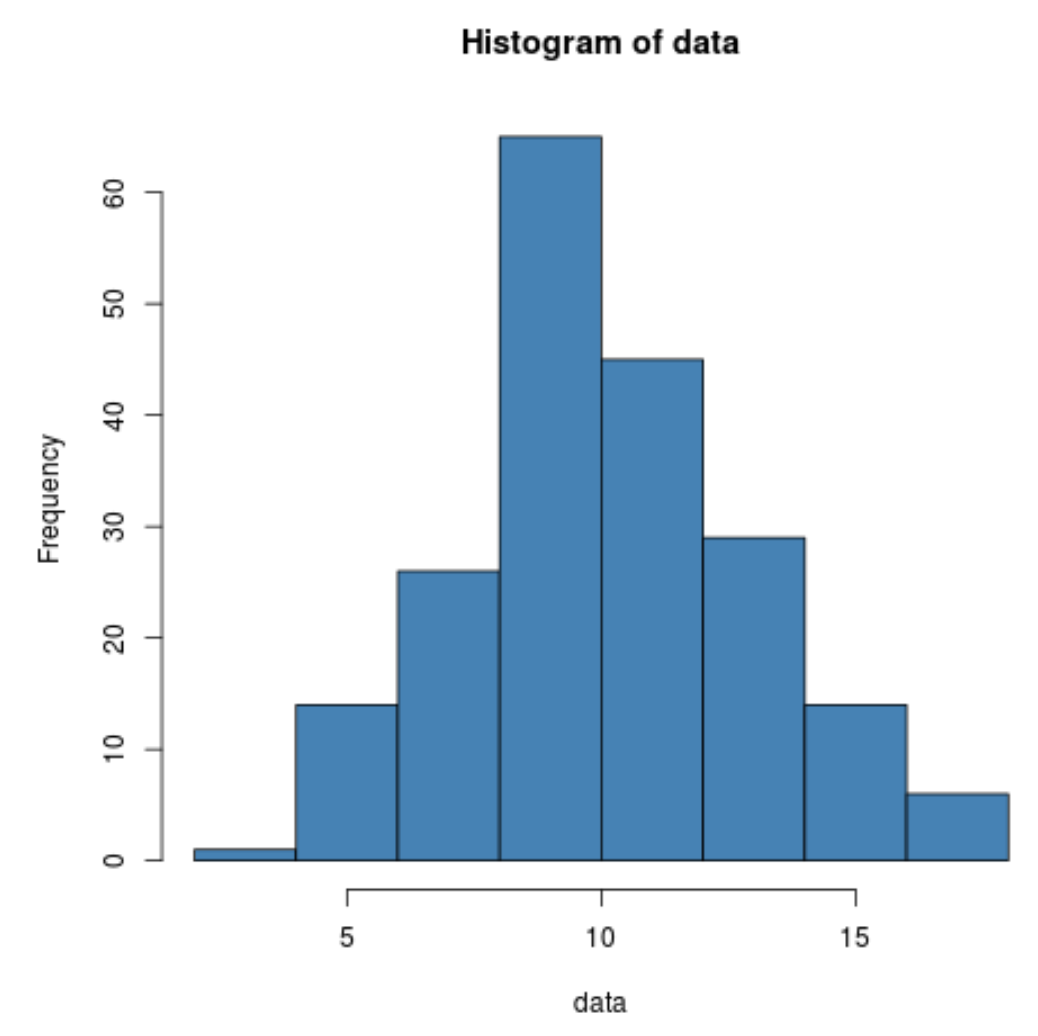
Wir können sogar einen Shapiro-Wilk-Test durchführen, um festzustellen, ob der Datensatz aus einer normalen Population stammt:
shapiro.test(data)
Shapiro-Wilk normality test
data: data
W = 0.99274, p-value = 0.4272
Der p-Wert des Tests beträgt 0,4272. Da dieser Wert nicht kleiner als 0,05 ist, können wir davon ausgehen, dass die Beispieldaten aus einer Population stammen, die normal verteilt ist.
Dieses Ergebnis sollte nicht überraschen, da wir die Daten mit der Funktion rnorm() generiert haben, die natürlich eine zufällige Stichprobe von Daten generiert, die aus einer Normalverteilung stammen.
So zeichnen Sie eine Normalverteilung in R
Ein Leitfaden für dnorm, pnorm, qnorm und rnorm in R
So führen Sie einen Shapiro-Wilk-Test auf Normalität in R durch
Der einfachste Weg, Arrays in Python zu verketten, ist die Verwendung der Funktion numpy.concatenate, die die folgende Syntax verwendet:
numpy.concatenate((a1, a2, ….), axis = 0)
wo:
Häufig möchten Sie möglicherweise nur die Anzahl der Zeilen in einem pandas-DataFrame zählen, die bestimmte Kriterien erfüllen.
Glücklicherweise ist dies mit der folgenden grundlegenden Syntax einfach zu bewerkstelligen:
sum(df …