
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Wenn wir die Beziehung zwischen einer einzelnen Prädiktorvariablen und einer Antwortvariablen verstehen wollen, verwenden wir häufig eine einfache lineare Regression.
Wenn wir jedoch die Beziehung zwischen mehreren Prädiktorvariablen und einer Antwortvariablen verstehen möchten, können wir stattdessen multiple lineare Regressionen verwenden.
Wenn wir p Prädiktorvariablen haben, hat ein multiples lineares Regressionsmodell die Form:
Y = β 0 + β 1 X 1 + β 2 X 2 +… + β p X p + ε
wo:
Die Werte für β 0 , β 1 , B 2 ,…, β p werden nach der Methode der kleinsten Quadrate ausgewählt, die die Summe der quadratischen Residuen (RSS) minimiert:
RSS = Σ (y i - ŷ i ) 2
wo:
Die Methode zur Ermittlung dieser Koeffizientenschätzungen basiert auf der Matrixalgebra, auf die hier nicht näher eingegangen wird. Glücklicherweise kann jede statistische Software diese Koeffizienten für Sie berechnen.
Angenommen, wir passen ein Modell mit mehreren linearen Regressionen an, indem wir die untersuchten Stunden der Prädiktorvariablen und die vorbereitenden Prüfungen sowie die Prüfungsergebnisse der Antwortvariablen verwenden.
Der folgende Screenshot zeigt, wie die Ausgabe der multiplen linearen Regression für dieses Modell aussehen könnte:
Hinweis: Der folgende Screenshot zeigt multiple lineare Regressionsausgaben für Excel. Die in der Ausgabe angezeigten Zahlen sind jedoch typisch für die Regressionsausgaben, die Sie mit einer statistischen Software sehen.
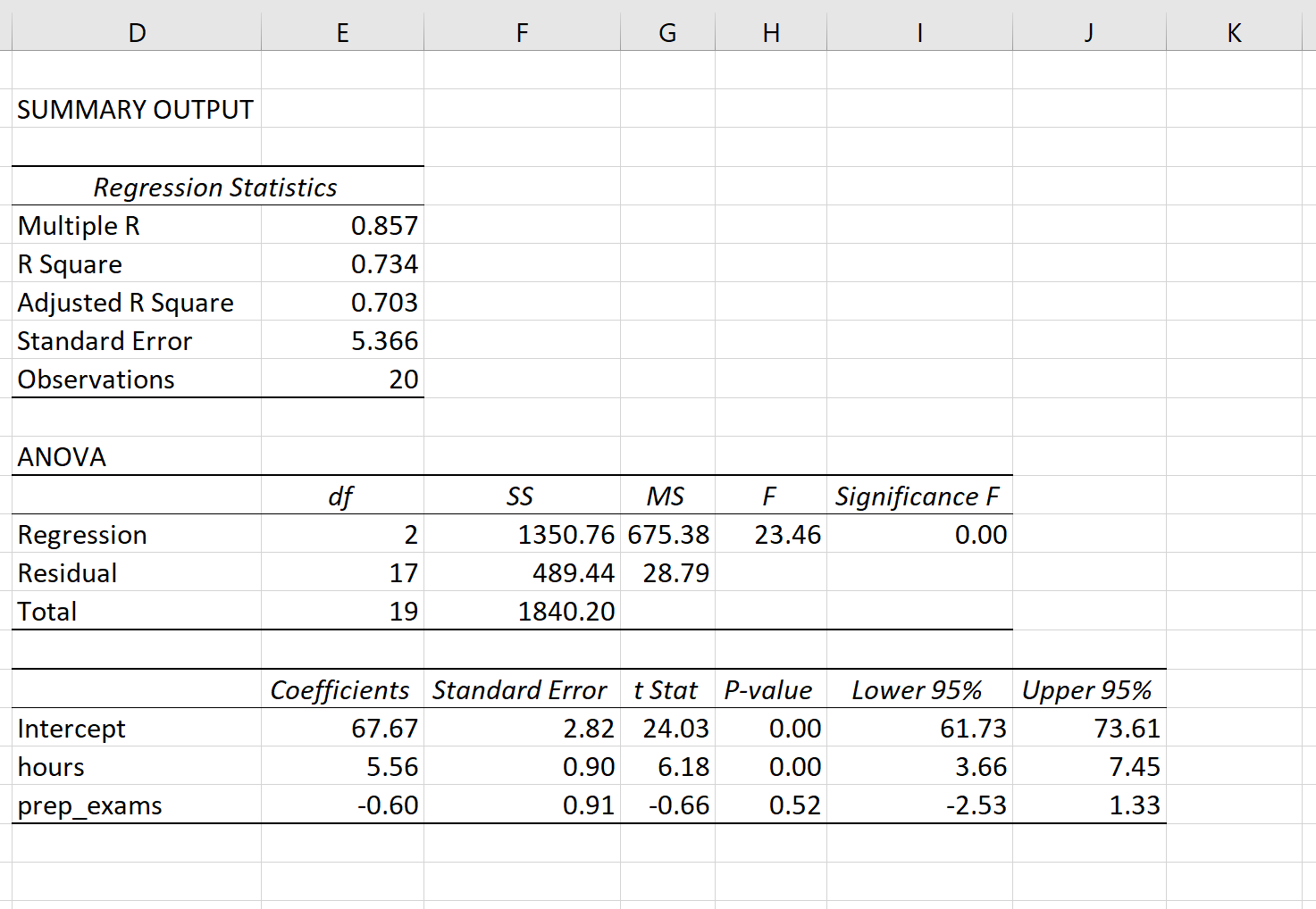
Aus den Modellausgaben ermöglichen die Koeffizienten die Bildung eines geschätzten multiplen linearen Regressionsmodells:
Prüfungsergebnis = 67,67 + 5,56 * (Stunden) - 0,60 * (Vorbereitungsprüfungen)
Die Interpretation der Koeffizienten erfolgt wie folgt:
Wir können dieses Modell auch verwenden, um die erwartete Prüfungspunktzahl zu ermitteln, die ein Schüler auf der Grundlage seiner gesamten Stunden und der vorbereiteten Prüfungen erhält. Zum Beispiel wird von einem Studenten, der 4 Stunden studiert und 1 Vorbereitungsprüfung ablegt, erwartet, dass er bei der Prüfung 89,31 Punkte erzielt:
Prüfungsergebnis = 67,67 + 5,56 * (4) -0,60 * (1) = 89,31
So interpretieren Sie das Residuum der Modellausgabe:
Es gibt zwei Zahlen, die häufig verwendet werden, um zu bewerten, wie gut ein multiples lineares Regressionsmodell zu einem Datensatz passt:
1. R-Quadrat: Dies ist der Anteil der Varianz in der Antwortvariablen, der durch die Prädiktorvariablen erklärt werden kann.
Der Wert für R-Quadrat kann im Bereich von 0 bis 1 liegen. Ein Wert von 0 zeigt an, dass die Antwortvariable überhaupt nicht durch die Prädiktorvariable erklärt werden kann. Ein Wert von 1 gibt an, dass die Antwortvariable durch die Prädiktorvariable fehlerfrei perfekt erklärt werden kann.
Je höher das R-Quadrat eines Modells ist, desto besser kann das Modell die Daten anpassen.
2. Standardfehler: Dies ist der durchschnittliche Abstand, um den die beobachteten Werte von der Regressionslinie fallen. Je kleiner der Standardfehler ist, desto besser kann ein Modell die Daten anpassen.
Wenn wir Vorhersagen mithilfe eines Regressionsmodells treffen möchten, kann der Standardfehler der Regression eine nützlichere Metrik sein als das R-Quadrat, da er uns eine Vorstellung davon gibt, wie genau unsere Vorhersagen in Einheiten sein werden.
In den folgenden Artikeln finden Sie eine vollständige Erläuterung der Vor- und Nachteile der Verwendung von R-Quadrat im Vergleich zum Standardfehler zur Beurteilung der Modellanpassung:
Es gibt vier Hauptannahmen, die die multiple lineare Regression für die Daten macht:
1. Lineare Beziehung: Es besteht eine lineare Beziehung zwischen der unabhängigen Variablen x und der abhängigen Variablen y.
2. Unabhängigkeit: Die Residuen sind unabhängig. Insbesondere gibt es keine Korrelation zwischen aufeinanderfolgenden Residuen in Zeitreihendaten.
3. Homoskedastizität: Die Residuen weisen auf jeder Ebene von x eine konstante Varianz auf.
4. Normalität: Die Residuen des Modells sind normalverteilt.
Eine vollständige Erklärung zum Testen dieser Annahmen finden Sie in diesem Artikel.
Die folgenden Tutorials enthalten schrittweise Beispiele für die Durchführung einer multiplen linearen Regression mit unterschiedlicher Statistiksoftware/Programmen:
So führen Sie eine mehrfache lineare Regression in R durch
Durchführen einer mehrfachen linearen Regression in Python
Durchführen einer mehrfachen linearen Regression in Excel
Durchführen einer mehrfachen linearen Regression in SPSS
Durchführen einer mehrfachen linearen Regression in Stata
So führen Sie eine lineare Regression in Google Tabellen durch
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …