
Eine einfaktorielle ANOVA wird verwendet, um zu bestimmen, ob es einen statistisch signifikanten Unterschied zwischen den Mittelwerten von drei oder mehr unabhängigen Gruppen gibt oder nicht.
Das folgende Beispiel bietet …
In diesem Tutorial wird erklärt, wie eine einfaktorielle ANOVA in R durchgeführt wird.
Eine einfaktorielle ANOVA („Varianzanalyse“) wird verwendet, um zu bestimmen, ob zwischen den Mitteln von drei oder mehr unabhängigen Gruppen ein statistisch signifikanter Unterschied besteht oder nicht.
Diese Art von Test wird als einfaktorielle ANOVA bezeichnet, da wir analysieren, wie sich eine Prädiktorvariable auf eine Antwortvariable auswirkt. Wenn wir stattdessen daran interessiert wären, wie sich zwei Prädiktorvariablen auf eine Antwortvariable auswirken, könnten wir eine zweifaktorielle ANOVA durchführen.
Das folgende Beispiel zeigt, wie eine einfaktorielle ANOVA in R durchgeführt wird.
Angenommen, wir möchten feststellen, ob drei verschiedene Trainingsprogramme den Gewichtsverlust unterschiedlich beeinflussen. Die Prädiktorvariable, die wir untersuchen, ist das Trainingsprogramm und die Antwortvariable ist der Gewichtsverlust, gemessen in Pfund. Wir können eine einfaktorielle ANOVA durchführen, um festzustellen, ob es einen statistisch signifikanten Unterschied zwischen dem resultierenden Gewichtsverlust aus den drei Programmen gibt.
Wir rekrutieren 90 Personen, um an einem Experiment teilzunehmen, bei dem wir zufällig 30 Personen zuweisen, die einen Monat lang entweder Programm A, Programm B oder Programm C folgen.
Der folgende Code erstellt das Dataframe, mit dem wir arbeiten werden:
#Beispiel reproduzierbar machen
set.seed(0)
#Dataframe erstellen
data <- data.frame(program = rep(c("A", "B", "C"), each = 30),
weight_loss = c(runif(30, 0, 3),
runif(30, 0, 5),
runif(30, 1, 7)))
#Ersten sechs Reihen des Dataframes anzeigen
head(data)
program weight_loss
1 A 2.6900916
2 A 0.7965260
3 A 1.1163717
4 A 1.7185601
5 A 2.7246234
6 A 0.6050458
Die erste Spalte im Dataframe zeigt das Programm, an dem die Person einen Monat lang teilgenommen hat, und die zweite Spalte zeigt den Gesamtgewichtsverlust, den diese Person am Ende des Programms erlebt hat, gemessen in Pfund.
Bevor wir überhaupt das einfaktorielle ANOVA-Modell anpassen, können wir die Daten besser verstehen, indem wir den Mittelwert und die Standardabweichung des Gewichtsverlusts für jedes der drei Programme mithilfe des dplyr-Pakets ermitteln:
#dplyr Package laden
library(dplyr)
#Mittelwert, Standardabweichen finden
data %>%
group_by(program) %>%
summarise(mean = mean(weight_loss),
sd = sd(weight_loss))
A tibble: 3 x 3
program mean sd
1 A 1.58 0.905
2 B 2.56 1.24
3 C 4.13 1.57
Wir können auch ein Boxplot für jedes der drei Programme erstellen, um die Verteilung des Gewichtsverlusts für jedes Programm zu visualisieren:
#Boxplots erstellen
boxplot(weight_loss ~ program,
data = data,
main = "Weight Loss Distribution by Program",
xlab = "Program",
ylab = "Weight Loss",
col = "steelblue",
border = "black")
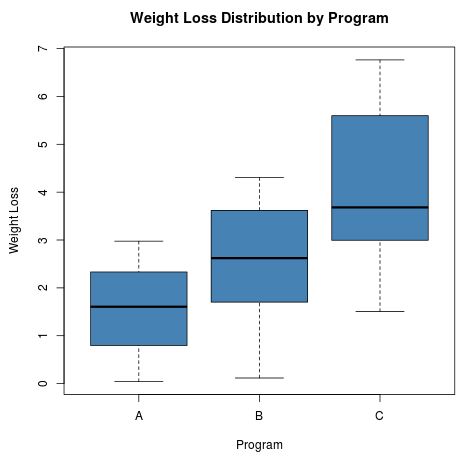
Nur aus diesen Boxplots können wir erkennen, dass der mittlere Gewichtsverlust für die Teilnehmer an Programm C am höchsten und der mittlere Gewichtsverlust für die Teilnehmer an Programm A am niedrigsten ist. Wir können auch sehen, dass die Standardabweichung (die „Länge“ der Boxplot) zur Gewichtsreduktion ist in Programm C im Vergleich zu den beiden anderen Programmen deutlich höher.
Als Nächstes passen wir das einfaktorielle ANOVA-Modell an unsere Daten an, um festzustellen, ob diese visuellen Unterschiede tatsächlich statistisch signifikant sind.
Die allgemeine Syntax zum Anpassen eines einfaktorielle ANOVA-Modells in R lautet wie folgt:
aov(response variable ~ predictor_variable, data = dataset)
In unserem Beispiel können wir den folgenden Code verwenden, um das einfaktorielle ANOVA-Modell anzupassen, wobei weight_loss als Antwortvariable und program als Prädiktorvariable verwendet werden. Wir können dann die Funktion summary() verwenden, um die Ausgabe unseres Modells anzuzeigen:
#Einfaktorielle ANOVA anpassen
model <- aov(weight_loss ~ program, data = data)
#Model Output anzeigen
summary(model)
Df Sum Sq Mean Sq F value Pr(>F)
program 2 98.93 49.46 30.83 7.55e-11 ***
Residuals 87 139.57 1.60
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Aus der Modellausgabe können wir ersehen, dass das Prädiktorvariablenprogramm auf dem .05-Signifikanzniveau statistisch signifikant ist. Mit anderen Worten, es gibt einen statistisch signifikanten Unterschied zwischen dem mittleren Gewichtsverlust, der sich aus den drei Programmen ergibt.
Bevor wir fortfahren, sollten wir überprüfen, ob die Annahmen unseres Modells erfüllt sind, damit unsere Ergebnisse aus dem Modell zuverlässig sind. Insbesondere geht eine einfaktorielle ANOVA davon aus, dass:
1. Unabhängigkeit – Die Beobachtungen in jeder Gruppe müssen unabhängig voneinander sein. Da wir ein randomisiertes Design verwendet haben (d. H. Wir haben die Teilnehmer zufällig den Übungsprogrammen zugewiesen), sollte diese Annahme erfüllt sein, damit wir uns darüber keine Sorgen machen müssen.
2. Normalverteilung – Die abhängige Variable sollte für jede Ebene der Prädiktorvariablen ungefähr normal verteilt sein.
3. Gleiche Varianz – Die Varianzen für jede Gruppe sind gleich oder ungefähr gleich.
Eine Möglichkeit, die Annahmen von Normalverteilung und gleicher Varianz zu überprüfen, besteht darin, die Funktion plot() zu verwenden, das vier Modellprüfungsdiagramme erzeugt. Insbesondere interessieren uns die folgenden zwei Plots am meisten:
Der folgende Code kann verwendet werden, um diese Modellprüfungsdiagramme zu erstellen:
plot(model)
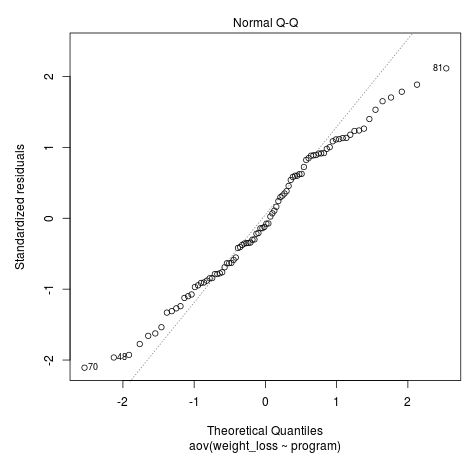
Das obige Q-Q-Diagramm ermöglicht es uns, die Annahme einer Normalverteilung zu überprüfen. Idealerweise fallen die standardisierten Residuen entlang der geraden diagonalen Linie im Diagramm. In der obigen Darstellung können wir jedoch sehen, dass die Residuen ziemlich stark von der Linie zum Anfang und zum Ende hin abweichen. Dies ist ein Hinweis darauf, dass unsere Annahme der Normalverteilung möglicherweise verletzt wird.
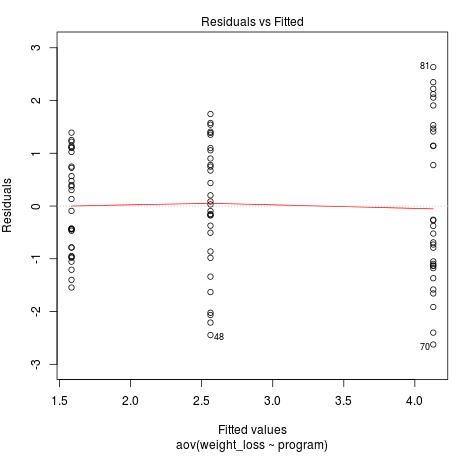
Das obige Diagramm Residuen vs. Angepasst ermöglicht es uns, unsere Annahme gleicher Varianzen zu überprüfen. Idealerweise möchten wir, dass die Residuen für jede Ebene der angepassten Werte gleichmäßig verteilt werden. Wir können sehen, dass die Residuen für die höheren angepassten Werte viel weiter verteilt sind, was ein Hinweis darauf ist, dass unsere Annahme gleicher Varianzen möglicherweise verletzt wird.
Um formell auf gleiche Abweichungen zu testen, könnten wir Levene’s Test mit dem car Paket durchführen:
#Car Package laden
library(car)
#Levene's Test durchführen
leveneTest(weight_loss ~ program, data = data)
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 2 4.1716 0.01862 *
87
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Der p-Wert des Tests beträgt 0,01862. Wenn wir ein Signifikanzniveau von 0,05 verwenden, würden wir die Nullhypothese ablehnen, dass die Varianzen über die drei Programme hinweg gleich sind. Wenn wir jedoch ein Signifikanzniveau von 0,01 verwenden, würden wir die Nullhypothese nicht ablehnen.
Obwohl wir versuchen könnten, die Daten zu transformieren, um sicherzustellen, dass unsere Annahmen von Normalverteilung und Varianzgleichheit erfüllt werden, werden wir uns derzeit keine allzu großen Sorgen machen.
Sobald wir überprüft haben, ob die Modellannahmen erfüllt sind (oder vernünftigerweise erfüllt sind), können wir einen Post-hoc-Test durchführen, um genau zu bestimmen, welche Behandlungsgruppen sich voneinander unterscheiden.
Für unseren Post-Hoc-Test verwenden wir die Funktion TukeyHSD(), um den Tukey-Test für mehrere Vergleiche durchzuführen:
#Turkey Test für meherer Vergleiche durchführen
TukeyHSD(model, conf.level=.95)
Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = weight_loss ~ program, data = data)
$program
diff lwr upr p adj
B-A 0.9777414 0.1979466 1.757536 0.0100545
C-A 2.5454024 1.7656076 3.325197 0.0000000
C-B 1.5676610 0.7878662 2.347456 0.0000199
Der p-Wert gibt an, ob zwischen den einzelnen Programmen ein statistisch signifikanter Unterschied besteht oder nicht. Wir können der Ausgabe entnehmen, dass es einen statistisch signifikanten Unterschied zwischen dem mittleren Gewichtsverlust jedes Programms bei einem Signifikanzniveau von 0,05 gibt.
Wir können auch die 95%-Konfidenzintervalle visualisieren, die sich aus dem Tukey-Test ergeben, indem wir die Funktion plot(TukeyHSD()) in R verwenden:
#Konfidenzintervall für jeden Vergleich erstellen
plot(TukeyHSD(model, conf.level=.95), las = 2)
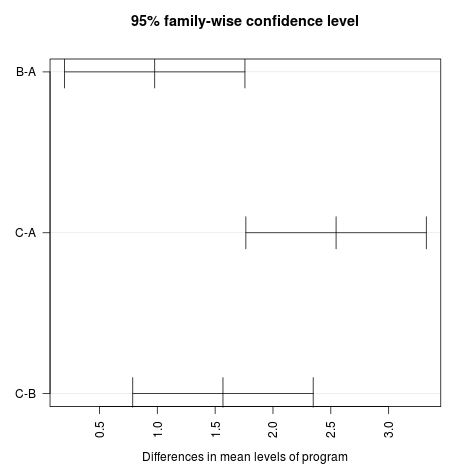
Die Ergebnisse der Konfidenzintervalle stimmen mit den Ergebnissen der Hypothesentests überein.
Insbesondere können wir sehen, dass keines der Konfidenzintervalle für den mittleren Gewichtsverlust zwischen Programmen den Wert Null enthält, was darauf hinweist, dass zwischen allen drei Programmen ein statistisch signifikanter Unterschied im mittleren Verlust besteht. Dies steht im Einklang mit der Tatsache, dass alle p-Werte aus unseren Hypothesentests unter 0,05 liegen.
Zuletzt können wir die Ergebnisse der einfaktorielle ANOVA so berichten, dass die Ergebnisse zusammengefasst werden:
Eine einfaktorielle ANOVA wurde durchgeführt, um die Auswirkungen des Trainingsprogramms auf den Gewichtsverlust (gemessen in Pfund) zu untersuchen. Es gab einen statistisch signifikanten Unterschied zwischen den Auswirkungen der drei Programme auf den Gewichtsverlust (F(2,87) = 30,83, p = 7,55e-11). Tukeys HSD-Post-hoc-Tests wurden durchgeführt.
Der mittlere Gewichtsverlust für Teilnehmer an Programm C ist signifikant höher als der mittlere Gewichtsverlust für Teilnehmer an Programm B(p <0,0001).
Der mittlere Gewichtsverlust für Teilnehmer an Programm C ist signifikant höher als der mittlere Gewichtsverlust für Teilnehmer an Programm A(p <0,0001).
Darüber hinaus ist der mittlere Gewichtsverlust für Teilnehmer an Programm B signifikant höher als der mittlere Gewichtsverlust für Teilnehmer an Programm A(p = 0,01).
Weiterführende Literatur: Einfaktorielle ANOVA: Definition, Formel und Beispiel
Eine einfaktorielle ANOVA wird verwendet, um zu bestimmen, ob es einen statistisch signifikanten Unterschied zwischen den Mittelwerten von drei oder mehr unabhängigen Gruppen gibt oder nicht.
Das folgende Beispiel bietet …
Eine geschachtelte ANOVA ist eine Art ANOVA („Varianzanalyse“), bei der mindestens ein Faktor in einem anderen Faktor verschachtelt ist.
Nehmen wir zum Beispiel an, ein Forscher möchte wissen, ob drei …