
Eine statistische Hypothese ist eine Annahme über einen Populationsparameter. Zum Beispiel können wir annehmen, dass die durchschnittliche Körpergröße eines Mannes in einem bestimmten Landkreis 68 Zoll beträgt. Die Annahme über …
„Die statistische Signifikanz ist das am wenigsten interessante an den Ergebnissen. Sie sollten die Ergebnisse in Größenordnungen beschreiben – eine Behandlung wirkt sich nicht nur auf Menschen aus, sondern auch auf sie. “ –Gene V. Glass
In der Statistik verwenden wir häufig p-Werte, um festzustellen, ob zwischen zwei Gruppen ein statistisch signifikanter Unterschied besteht.
Angenommen, wir möchten wissen, ob zwei unterschiedliche Lerntechniken zu unterschiedlichen Testergebnissen führen. Wir haben also eine Gruppe von 20 Studenten, die eine Lerntechnik verwenden, um sich auf einen Test vorzubereiten, während eine andere Gruppe von 20 Studenten eine andere Lerntechnik verwendet. Wir lassen dann jeden Schüler den gleichen Test machen.
Nach Durchführung eines t-Tests mit zwei Stichproben für einen Mittelwertunterschied stellen wir fest, dass der p-Wert des Tests 0,001 beträgt. Wenn wir ein Signifikanzniveau von 0,05 verwenden, bedeutet dies, dass zwischen den mittleren Testergebnissen der beiden Gruppen ein statistisch signifikanter Unterschied besteht. Das Studium der Technik wirkt sich somit auf die Testergebnisse aus.
Der p-Wert sagt zwar aus, dass das Studium der Technik einen Einfluss auf die Testergebnisse hat, er sagt uns jedoch nicht, wie groß der Einfluss ist. Um dies zu verstehen, müssen wir die Effektgröße kennen.
Was ist die Effektgröße?
Eine Effektgröße ist eine Möglichkeit, den Unterschied zwischen zwei Gruppen zu quantifizieren.
Während ein p-Wert uns sagen kann, ob es einen statistisch signifikanten Unterschied zwischen zwei Gruppen gibt oder nicht, kann eine Effektgröße uns sagen, wie groß dieser Unterschied tatsächlich ist. In der Praxis sind Effektgrößen viel interessanter und nützlicher zu wissen als p-Werte.
Abhängig von der Art der Analyse gibt es drei Möglichkeiten, die Effektgröße zu messen:
1. Standardisierte mittlere Differenz
Wenn Sie die mittlere Differenz zwischen zwei Gruppen untersuchen möchten, können Sie die Effektgröße über eine standardisierte mittlere Differenz berechnen. Die beliebteste Formel ist Cohens d, die wie folgt berechnet wird:
Cohen’s d = (x1 – x2) / s
wobei x1 und x2 das Stichprobenmittelwerte der Gruppe 1 bzw. der Gruppe 2 sind und s die Standardabweichung der Population ist, aus der die beiden Gruppen entnommen wurden.
Mit dieser Formel ist die Effektgröße leicht zu interpretieren:
- Ein d von 1 zeigt an, dass sich die beiden Gruppenmittelwerte um eine Standardabweichung unterscheiden.
- Ein d von 2 bedeutet, dass sich die Gruppenmittelwerte um zwei Standardabweichungen unterscheiden.
- Ein d von 2,5 zeigt an, dass sich die beiden Mittelwerte um 2,5 Standardabweichungen usw. unterscheiden.
Eine andere Möglichkeit, die Effektgröße zu interpretieren, ist wie folgt: Eine Effektgröße von 0,3 bedeutet, dass die Punktzahl der durchschnittlichen Person in Gruppe 2 0,3 Standardabweichungen über der durchschnittlichen Person in Gruppe 1 liegt und somit die Punktzahl von 62% derjenigen in Gruppe 1 übersteigt.
Die folgende Tabelle zeigt verschiedene Effektgrößen und ihre entsprechenden Perzentile:
| Effektgröße | Prozentsatz der Gruppe *2*, die in Gruppe *1* unterdurchschnittlich wäre |
|---|---|
| 0.0 | 50% |
| 0.2 | 58% |
| 0.4 | 66% |
| 0.6 | 73% |
| 0.8 | 79% |
| 1.0 | 84% |
| 1.2 | 88% |
| 1.4 | 92% |
| 1.6 | 95% |
| 1.8 | 96% |
| 2.0 | 98% |
| 2.5 | 99% |
| 3.0 | 99.9% |
Je größer die Effektgröße ist, desto größer ist der Unterschied zwischen dem durchschnittlichen Individuum in jeder Gruppe.
Im Allgemeinen wird ein d von 0,2 oder kleiner als kleine Effektgröße angesehen, ein d von etwa 0,5 als mittlere Effektgröße und ein d von 0,8 oder größer als große Effektgröße. Wenn sich die Mittelwerte zweier Gruppen nicht um mindestens 0,2 Standardabweichungen unterscheiden, ist der Unterschied trivial, selbst wenn der p-Wert statistisch signifikant ist.
2. Korrelationskoeffizient
Wenn Sie die quantitative Beziehung zwischen zwei Variablen untersuchen möchten, können Sie die Effektgröße am häufigsten über den Pearson-Korrelationskoeffizienten berechnen. Dies ist ein Maß für die lineare Assoziation zwischen zwei Variablen X und Y. Es hat einen Wert zwischen -1 und 1, wobei:
- -1 zeigt eine vollkommen negative lineare Korrelation zwischen zwei Variablen an
- 0 zeigt keine lineare Korrelation zwischen zwei Variablen an
- 1 zeigt eine vollkommen positive lineare Korrelation zwischen zwei Variablen an
Die Formel zur Berechnung des Pearson-Korrelationskoeffizienten ist recht komplex, kann aber hier für Interessierte gefunden werden.
Je weiter der Korrelationskoeffizient von Null entfernt ist, desto stärker ist die lineare Beziehung zwischen zwei Variablen. Dies kann auch durch Erstellen eines einfachen Streudiagramms der Werte für die Variablen X und Y gesehen werden.
Das folgende Streudiagramm zeigt beispielsweise die Werte von zwei Variablen mit einem Korrelationskoeffizienten von r = 0,94. Dieser Wert ist weit von Null entfernt, was darauf hinweist, dass eine starke positive Beziehung zwischen den beiden Variablen besteht.
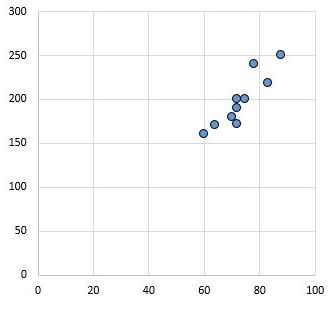
Umgekehrt zeigt das folgende Streudiagramm die Werte von zwei Variablen mit einem Korrelationskoeffizienten von r = 0,03. Dieser Wert liegt nahe bei Null, was darauf hinweist, dass zwischen den beiden Variablen praktisch keine Beziehung besteht.
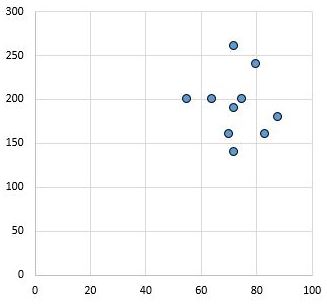
Im Allgemeinen wird die Effektgröße als gering angesehen, wenn der Wert des Pearson-Korrelationskoeffizienten r etwa 0,1 beträgt, mittel, wenn r etwa 0,3 beträgt, und groß, wenn r 0,5 oder mehr beträgt.
3. Quotenverhältnis
Wenn Sie daran interessiert sind, die Erfolgsaussichten in einer Behandlungsgruppe im Verhältnis zu den Erfolgsaussichten in einer Kontrollgruppe zu untersuchen, ist die beliebteste Methode zur Berechnung der Effektgröße das Quotenverhältnis.
Angenommen, wir haben die folgende Tabelle:
| Effektgröße | \# Erfolge | \# Fehler |
|---|---|---|
| Behandlungsgruppe | A | B |
| Kontrollgruppe | C | D |
Das Quotenverhältnis würde wie folgt berechnet:
Quotenverhältnis = (AD) / (BC)
Je weiter das Quotenverhältnis von 1 entfernt ist, desto höher ist die Wahrscheinlichkeit, dass die Behandlung tatsächlich wirkt.
Die Vorteile der Verwendung von Effektgrößen gegenüber P-Werten
Effektgrößen haben gegenüber p-Werten mehrere Vorteile:
- Eine Effektgröße hilft uns, eine bessere Vorstellung davon zu bekommen, wie groß der Unterschied zwischen zwei Gruppen ist oder wie stark die Assoziation zwischen zwei Gruppen ist. Ein p-Wert kann uns nur sagen, ob es einen signifikanten Unterschied oder eine signifikante Assoziation gibt oder nicht.
- Im Gegensatz zu p-Werten können Effektgrößen verwendet werden, um die Ergebnisse verschiedener Studien, die in verschiedenen Umgebungen durchgeführt wurden, quantitativ zu vergleichen. Aus diesem Grund werden in Metaanalysen häufig Effektgrößen verwendet.
- P-Werte können durch große Stichproben beeinflusst werden. Je größer die Stichprobe ist, desto größer ist die statistische Aussagekraft eines Hypothesentests, mit dem auch kleine Effekte erkannt werden können. Dies kann trotz kleiner Effektgrößen, die möglicherweise keine praktische Bedeutung haben, zu niedrigen p-Werten führen.
Ein einfaches Beispiel kann dies verdeutlichen: Angenommen, wir möchten wissen, ob zwei Lerntechniken zu unterschiedlichen Testergebnissen führen. Wir haben eine Gruppe von 20 Studenten, die eine Lerntechnik anwenden, während eine andere Gruppe von 20 Studenten eine andere Lerntechnik verwendet. Wir lassen dann jeden Schüler den gleichen Test machen.
Die mittlere Punktzahl für Gruppe 1 beträgt 90,65 und die mittlere Punktzahl für Gruppe 2 beträgt 90,75. Die Standardabweichung für Probe 1 beträgt 2,77 und die Standardabweichung für Probe 2 beträgt 2,78. Wenn wir einen unabhängigen t-Test mit zwei Stichproben durchführen, stellt sich heraus, dass die Teststatistik -0,113 und der entsprechende p-Wert 0,91 beträgt. Der Unterschied zwischen den mittleren Testergebnissen ist statistisch nicht signifikant.
Überlegen Sie jedoch, ob die Stichprobengrößen der beiden Stichproben beide 200 waren, die Mittelwerte und die Standardabweichungen jedoch exakt gleich blieben. In diesem Fall würde ein unabhängiger t-Test mit zwei Stichproben ergeben, dass die Teststatistik -1,97 beträgt und der entsprechende p-Wert knapp unter 0,05 liegt. Der Unterschied zwischen den mittleren Testergebnissen ist statistisch signifikant.
Der Grund dafür, dass große Stichproben zu statistisch signifikanten Schlussfolgerungen führen können, liegt in der Formel zur Berechnung der Teststatistik t:
Teststatistik t = [ (x1 – x2) – d ] / (√s21 / n1 + s22 / n2)
Beachten Sie, dass wenn n1 und n2 Beachten Sie, dass wenn n1 und n2 klein sind, der gesamte Nenner der Teststatistik t klein ist. Und wenn wir durch eine kleine Zahl teilen, erhalten wir eine große Zahl. Dies bedeutet, dass die Teststatistik t groß und der entsprechende p-Wert klein ist, was zu statistisch signifikanten Ergebnissen führt.
Das könnte Sie auch interessieren:
Eine einfache Erklärung der statistischen vs. praktischen Signifikanz
Bayes-Faktor: Definition + Interpretation
Wenn wir einen Hypothesentest durchführen, erhalten wir normalerweise einen p-Wert, den wir mit einem alpha-Level vergleichen, um zu entscheiden, ob wir die Nullhypothese ablehnen oder nicht ablehnen sollen.
Zum Beispiel …