Der Antilog einer Zahl ist der Kehrwert des Logarithmus einer Zahl.
Wenn man also den Logarithmus einer Zahl berechnet, kann man den Antilogarithmus verwenden, um die ursprüngliche Zahl zurückzubekommen.
Angenommen …
Der beste Weg, um einen Datensatz zu verstehen, besteht darin, deskriptive Statistiken für die Variablen innerhalb des Datensatzes zu berechnen. Es gibt drei gängige Formen der deskriptiven Statistik:
In diesem Lernprogramm wird erläutert, wie beschreibende Statistiken für Variablen in SPSS berechnet werden.
Angenommen, wir haben den folgenden Datensatz, der vier Variablen für 20 Schüler einer bestimmten Klasse enthält:
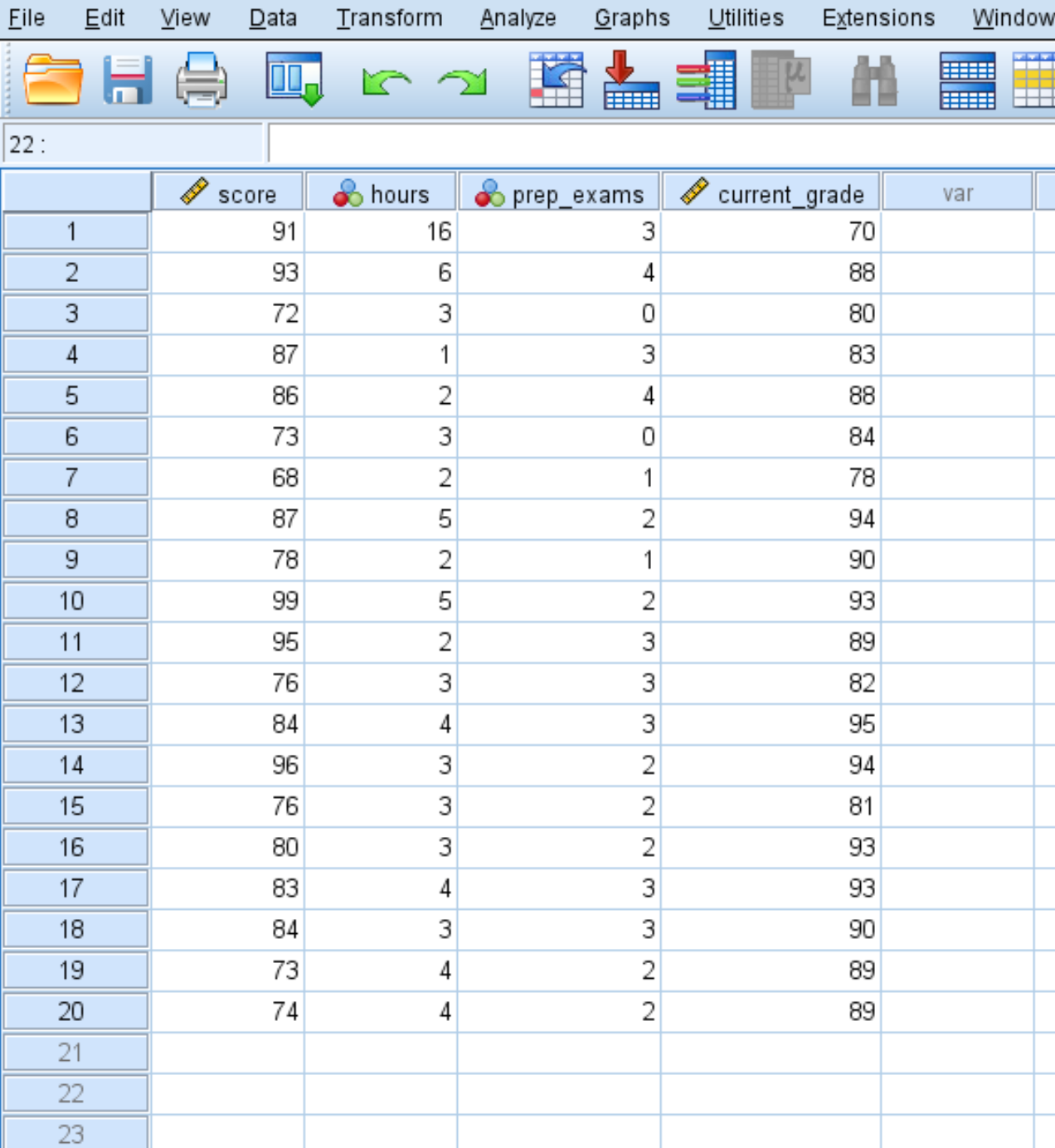
So berechnen Sie beschreibende Statistiken für jede dieser vier Variablen:
Um zusammenfassende Statistiken für jede Variable zu berechnen, klicken Sie auf die Registerkarte Analysieren, dann auf Beschreibende Statistiken und dann auf Beschreiben:
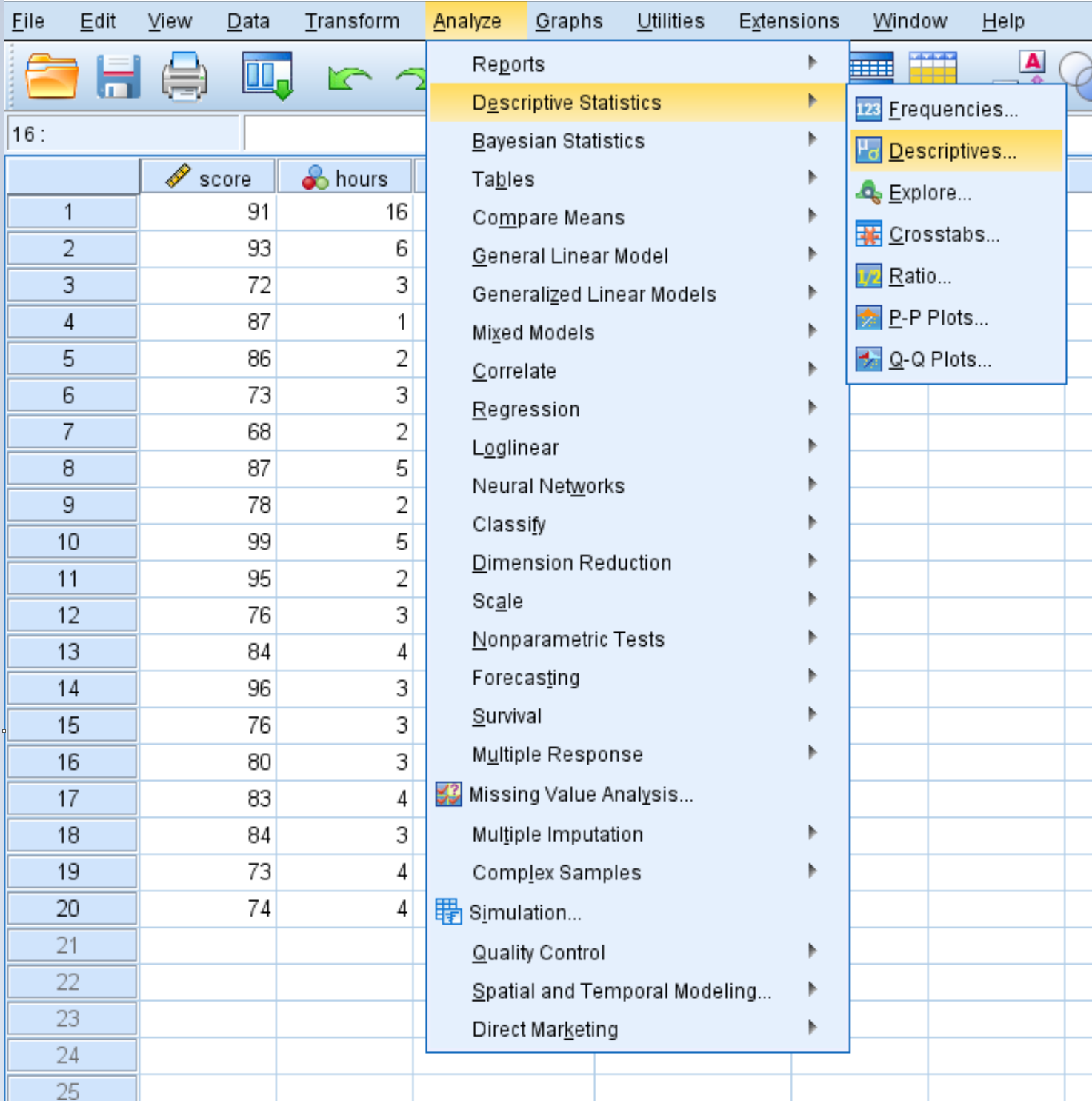
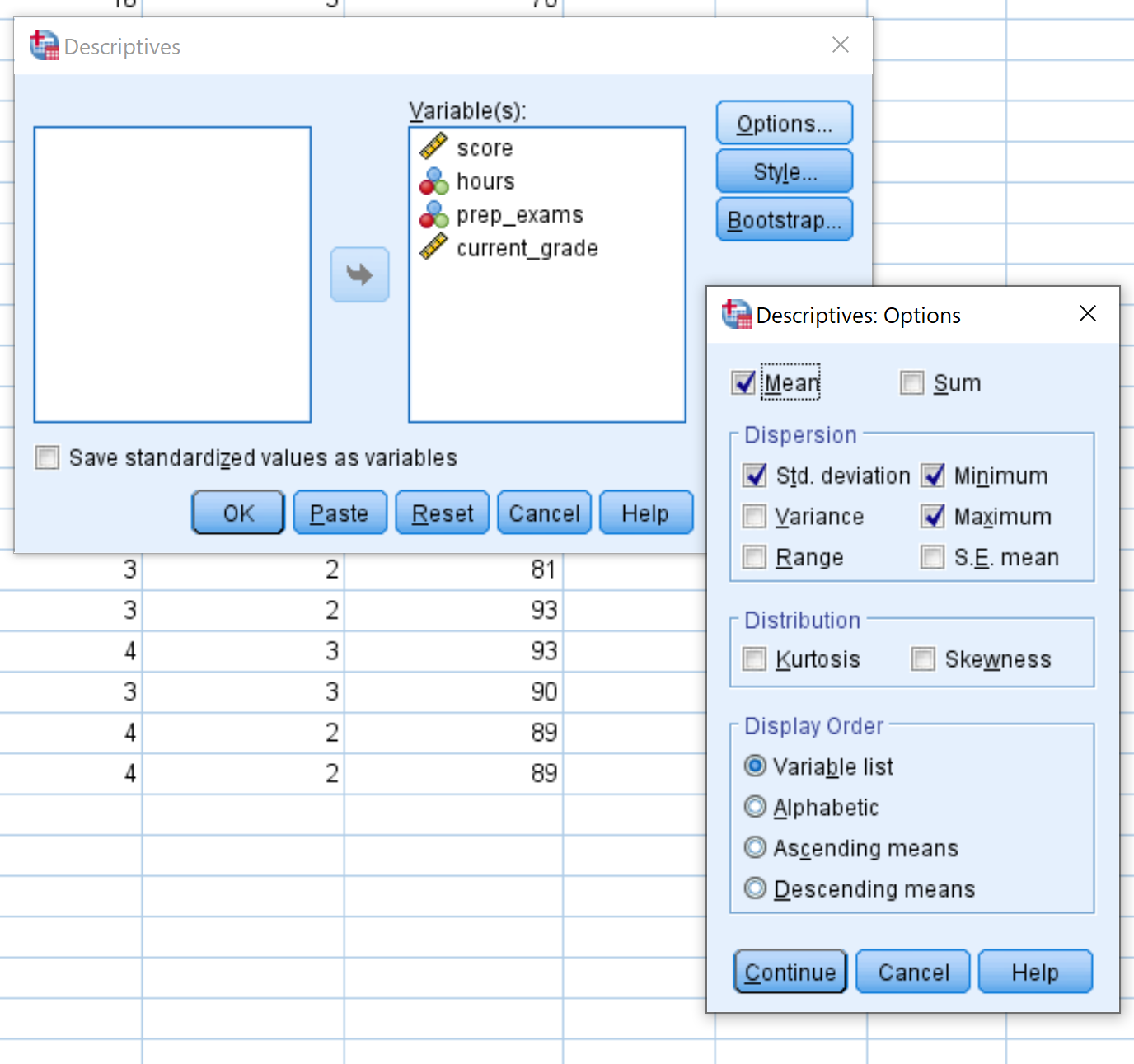
Ziehen Sie im neuen Fenster, das angezeigt wird, jede der vier Variablen in das Feld mit der Bezeichnung Variable (n). Wenn Sie möchten, können Sie auf die Schaltfläche Optionen klicken und die spezifischen beschreibenden Statistiken auswählen, die SPSS berechnen soll. Klicken Sie dann auf Weiter. Klicken Sie dann auf OK.
Sobald Sie auf OK klicken, wird eine Tabelle angezeigt, in der die folgenden beschreibenden Statistiken für jede Variable angezeigt werden:
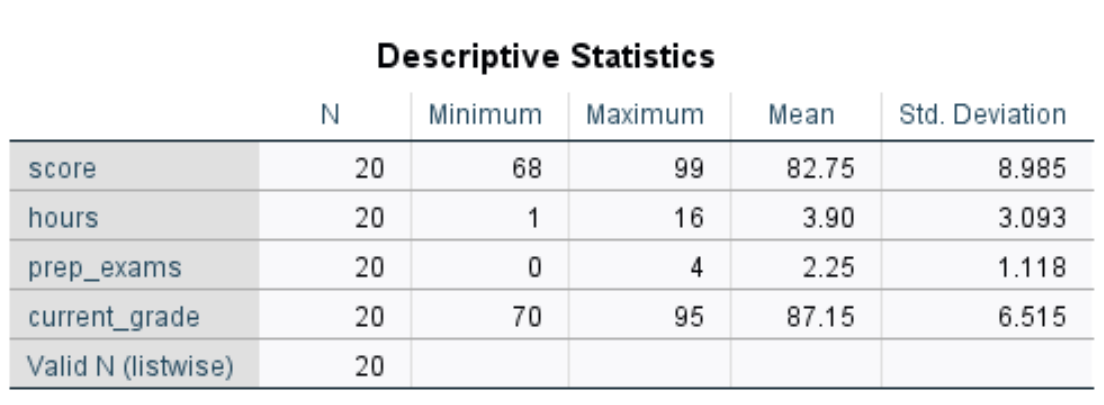
So interpretieren Sie die Zahlen in dieser Tabelle für die variable Punktzahl:
Diese Tabelle ermöglicht es uns, den Bereich jeder Variablen (unter Verwendung des Minimums und des Maximums), die zentrale Position jeder Variablen (unter Verwendung des Mittelwerts) und die Verteilung der Werte für jede Variable (unter Verwendung der Standardabweichung) schnell zu verstehen.
Um eine Häufigkeitstabelle für jede Variable zu erstellen, klicken Sie auf die Registerkarte Analysieren, dann auf Beschreibende Statistik und dann auf Häufigkeiten.
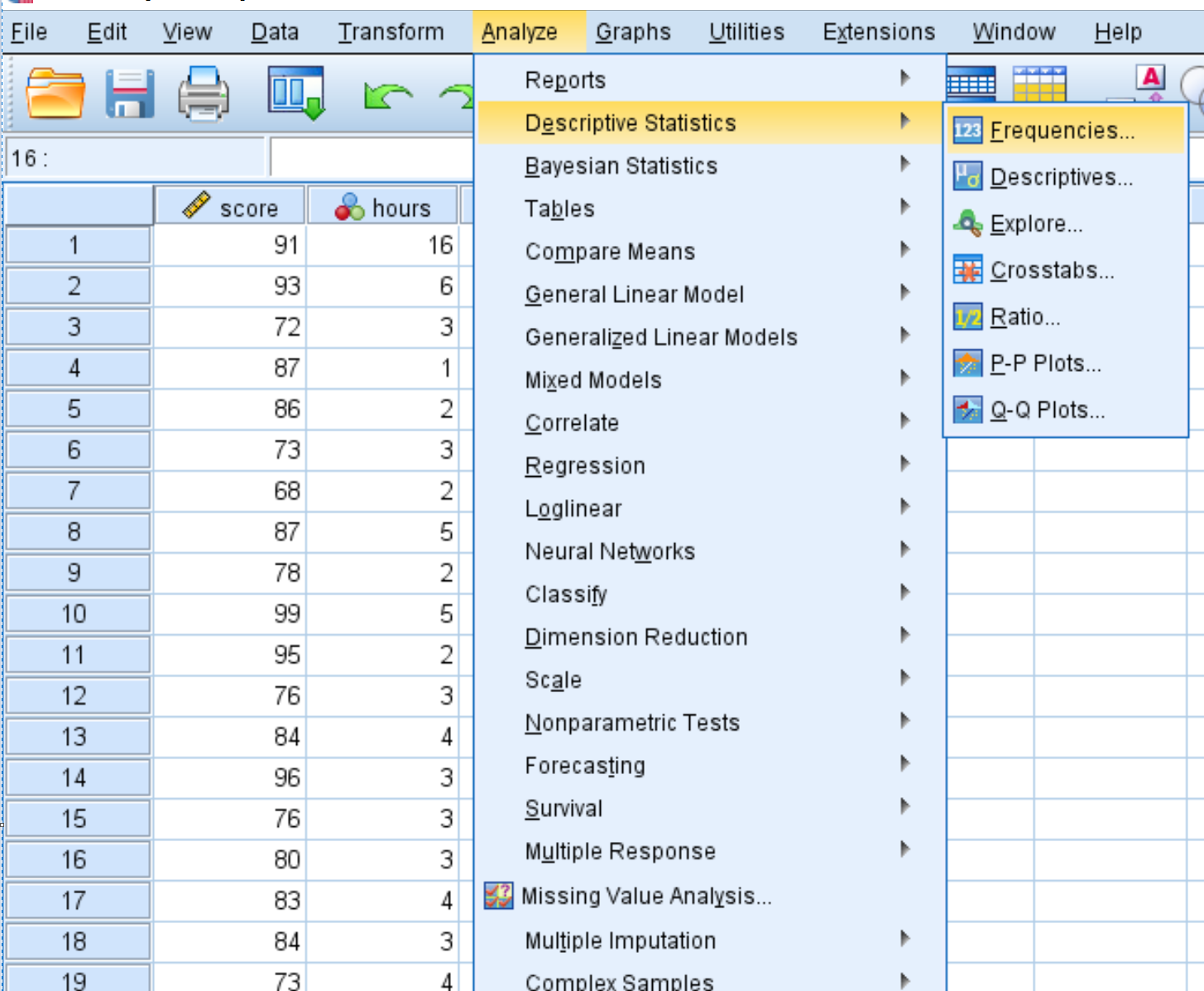
Ziehen Sie im neuen Fenster, das angezeigt wird, jede Variable in das Feld mit der Bezeichnung Variable (n). Klicken Sie dann auf OK.
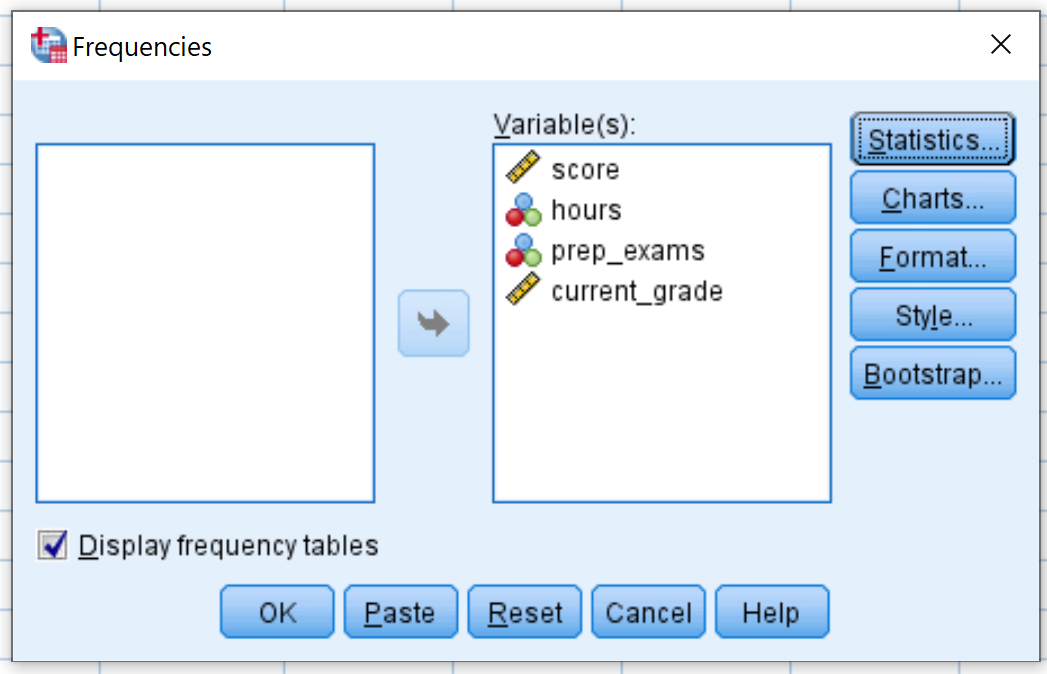
Eine Häufigkeitstabelle für jede Variable wird angezeigt. Hier ist zum Beispiel die für die variablen Stunden:
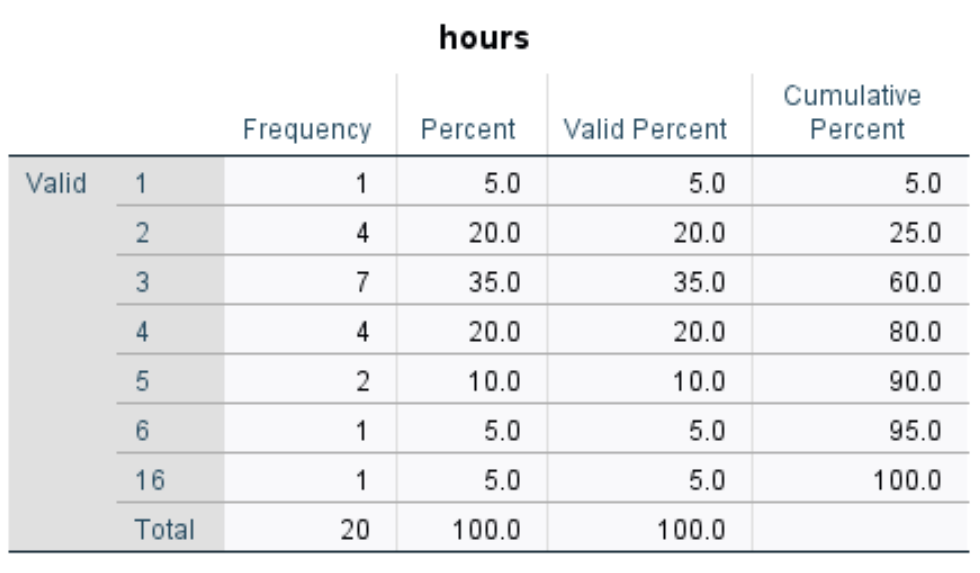
Die Tabelle kann folgendermaßen interpretiert werden:
Diese Tabelle gibt uns eine gute Vorstellung von der Verteilung der Datenwerte für jede Variable.
Diagramme helfen uns auch dabei, die Verteilung der Datenwerte für jede Variable in einem Datensatz zu verstehen. Eines der beliebtesten Diagramme hierfür ist ein Histogramm.
Um ein Histogramm für eine bestimmte Variable in einem Dataset zu erstellen, klicken Sie auf die Registerkarte Diagramme und dann auf Diagramm-Generator.
Wählen Sie im neuen Fenster, das angezeigt wird, im Bereich „Auswählen aus“ die Option Histogramm. Ziehen Sie dann die erste Histogrammoption in das Hauptbearbeitungsfenster. Ziehen Sie dann Ihre interessierende Variable auf die x-Achse. Für dieses Beispiel verwenden wir die Punktzahl. Klicken Sie dann auf OK.
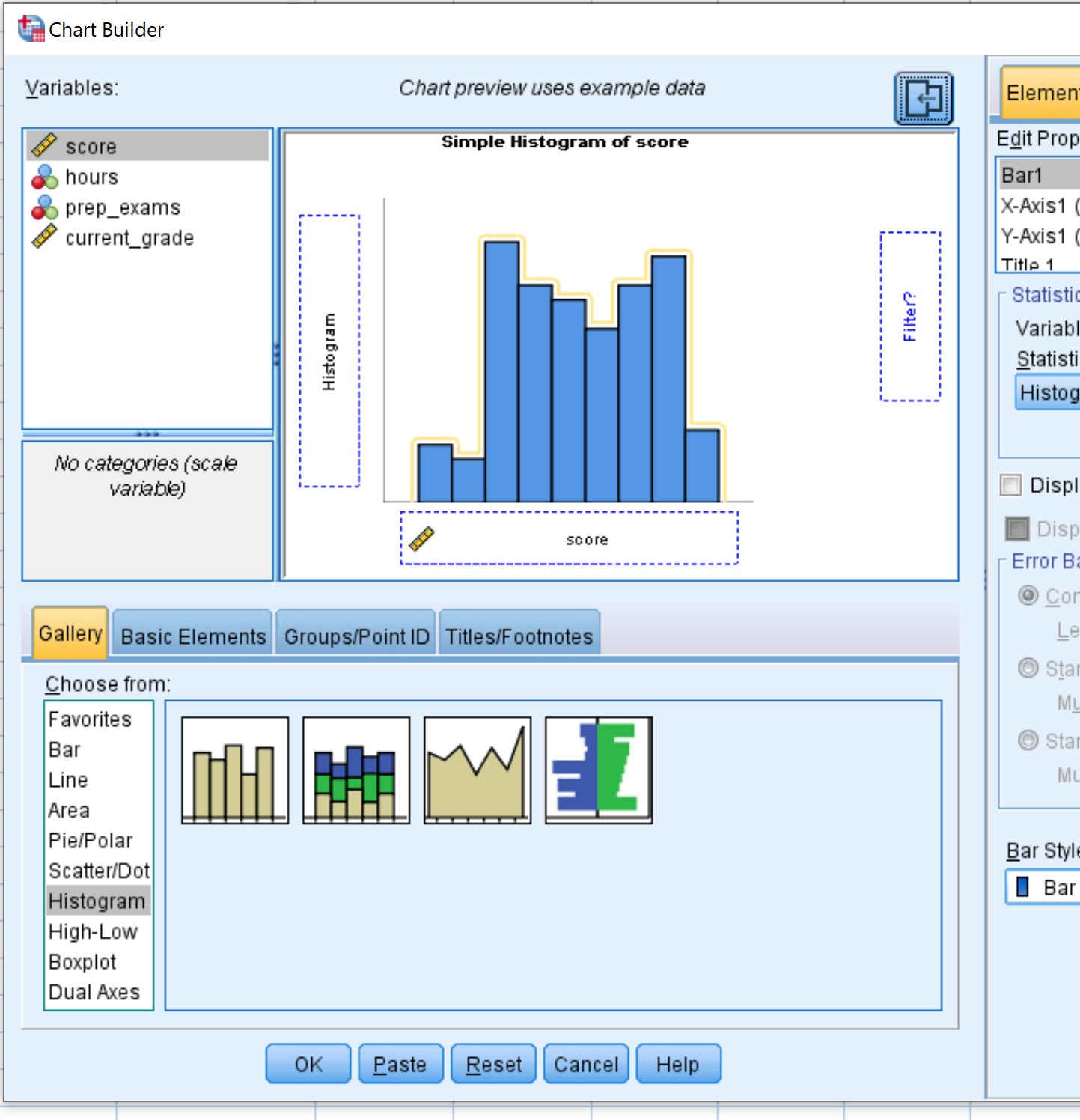
Sobald Sie auf OK klicken, wird ein Histogramm angezeigt, das die Verteilung der Werte für die Variablenbewertung anzeigt:
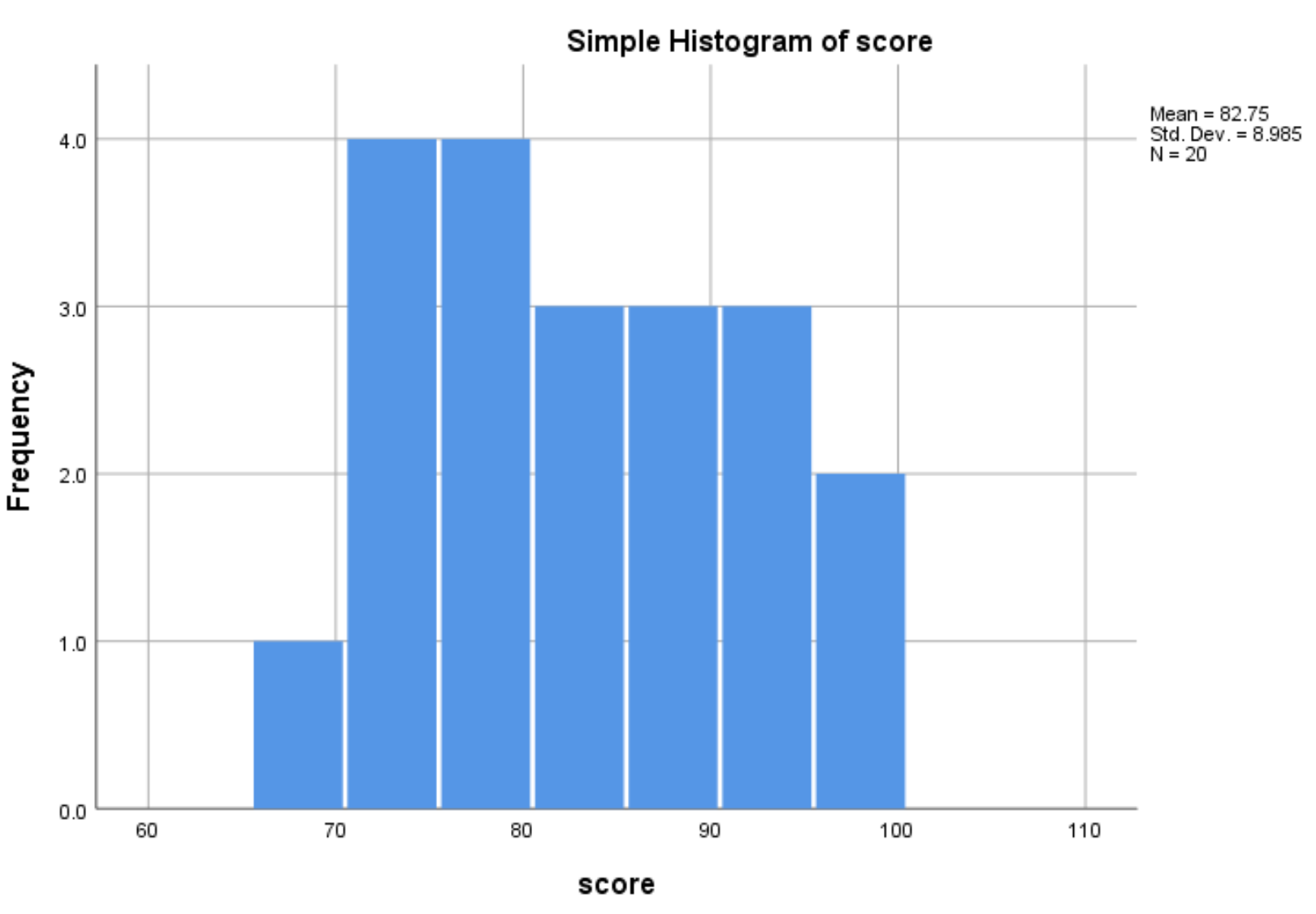
Aus dem Histogramm können wir ersehen, dass der Bereich der Prüfungsergebnisse zwischen 65 und 100 variiert, wobei die meisten Ergebnisse zwischen 70 und 90 liegen.
Wir können diesen Vorgang wiederholen, um auch für jede der anderen Variablen im Datensatz ein Histogramm zu erstellen.
"Statistik in Excel leicht gemacht" ist eine Sammlung von 16 Excel-Tabellen, die integrierte Formeln enthalten, um die wichtigsten statistischen Tests und Funktionen durchzuführen.

Der Antilog einer Zahl ist der Kehrwert des Logarithmus einer Zahl.
Wenn man also den Logarithmus einer Zahl berechnet, kann man den Antilogarithmus verwenden, um die ursprüngliche Zahl zurückzubekommen.
Angenommen …
Logistische Regression ist eine statistische Methode, die wir zur Anpassung eines Regressionsmodells verwenden, wenn die Antwortvariable binär ist. Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz passt …