
Ein Log-Log-Diagramm ist ein Diagramm, das sowohl auf der x-Achse als auch auf der y-Achse logarithmische Skalen verwendet.
Diese Art von Diagramm ist nützlich, um zwei Variablen zu visualisieren, wenn …
Oft möchte man die Gleichung finden, die am besten zu einer Kurve in R passt.
Das folgende Schritt-für-Schritt-Beispiel erklärt, wie man in R mit der Funktion poly() Kurven an Daten anpasst und wie man bestimmt, welche Kurve am besten zu den Daten passt.
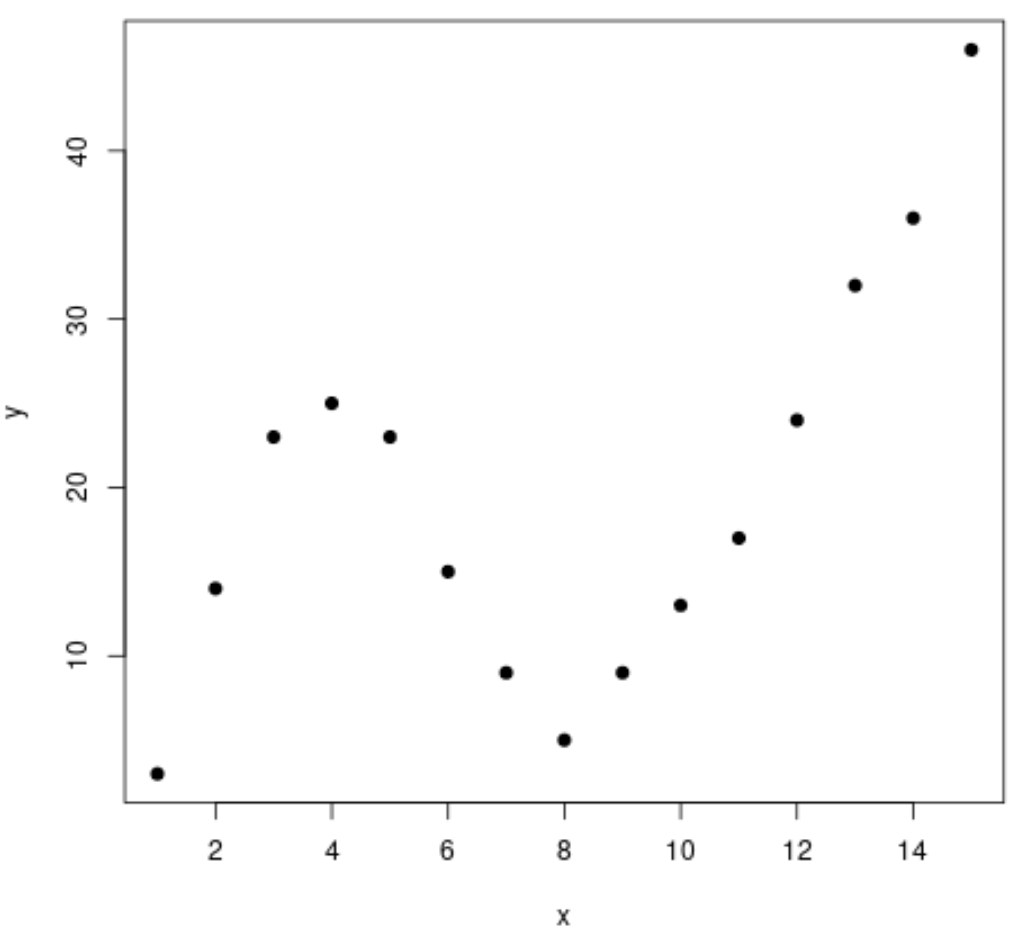
Zunächst erstellen wir einen synthetischen Datensatz und dann ein Streudiagramm, um die Daten zu visualisieren:
#Dataframe erstellen
df <- data.frame(x=1:15,
y=c(3, 14, 23, 25, 23, 15, 9, 5, 9, 13, 17, 24, 32, 36, 46))
#Erstellen eines Streudiagramms von x vs. y
plot(df$x, df$y, pch=19, xlab='x', ylab='y')
Als Nächstes passen wir mehrere polynomiale Regressionsmodelle an die Daten an und stellen die Kurve jedes Modells in derselben Grafik dar:
#polynomiale Regressionsmodelle bis zum 5. Grad anpassen
fit1 <- lm(y~x, data=df)
fit2 <- lm(y~poly(x,2,raw=TRUE), data=df)
fit3 <- lm(y~poly(x,3,raw=TRUE), data=df)
fit4 <- lm(y~poly(x,4,raw=TRUE), data=df)
fit5 <- lm(y~poly(x,5,raw=TRUE), data=df)
#Erstellen Sie ein Streudiagramm von x vs. y
plot(df$x, df$y, pch=19, xlab='x', ylab='y')
#X-Achsenwerte definieren
x_axis <- seq(1, 15, length=15)
#Kurve jedes Modells in das Diagramm einfügen
lines(x_axis, predict(fit1, data.frame(x=x_axis)), col='green')
lines(x_axis, predict(fit2, data.frame(x=x_axis)), col='red')
lines(x_axis, predict(fit3, data.frame(x=x_axis)), col='purple')
lines(x_axis, predict(fit4, data.frame(x=x_axis)), col='blue')
lines(x_axis, predict(fit5, data.frame(x=x_axis)), col='orange')
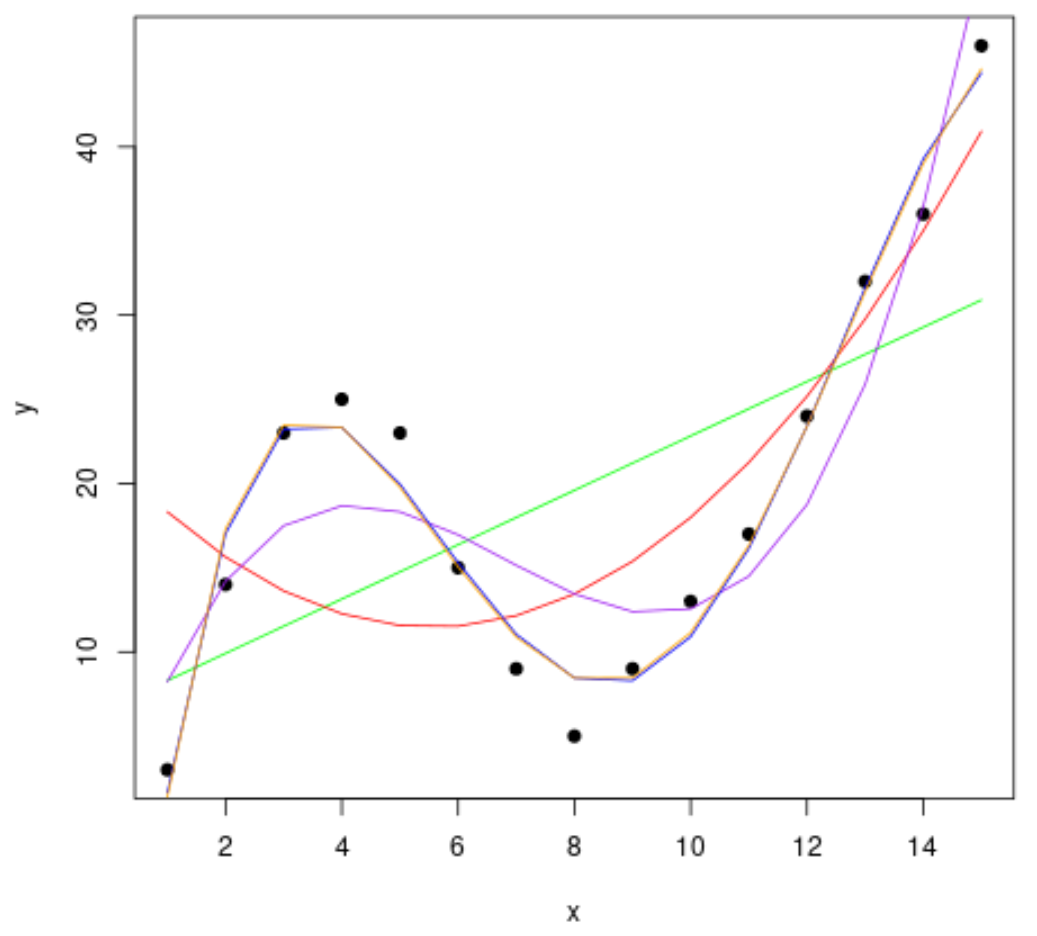
Um festzustellen, welche Kurve am besten zu den Daten passt, können wir uns das adjustierte R-Quadrat jedes Modells ansehen.
Dieser Wert gibt den Prozentsatz der Variation in der Antwortvariablen an, der durch die Prädiktorvariable(n) im Modell erklärt werden kann, bereinigt um die Anzahl der Prädiktorvariablen.
#Berechnete bereinigte R-Quadrat jedes Modells
summary(fit1)$adj.r.squared
summary(fit2)$adj.r.squared
summary(fit3)$adj.r.squared
summary(fit4)$adj.r.squared
summary(fit5)$adj.r.squared
[1] 0.3144819
[1] 0.5186706
[1] 0.7842864
[1] 0.9590276
[1] 0.9549709
Aus der Ausgabe können wir ersehen, dass das Modell mit dem höchsten bereinigten R-Quadrat das Polynom vierten Grades ist, das ein bereinigtes R-Quadrat von 0,959 hat.
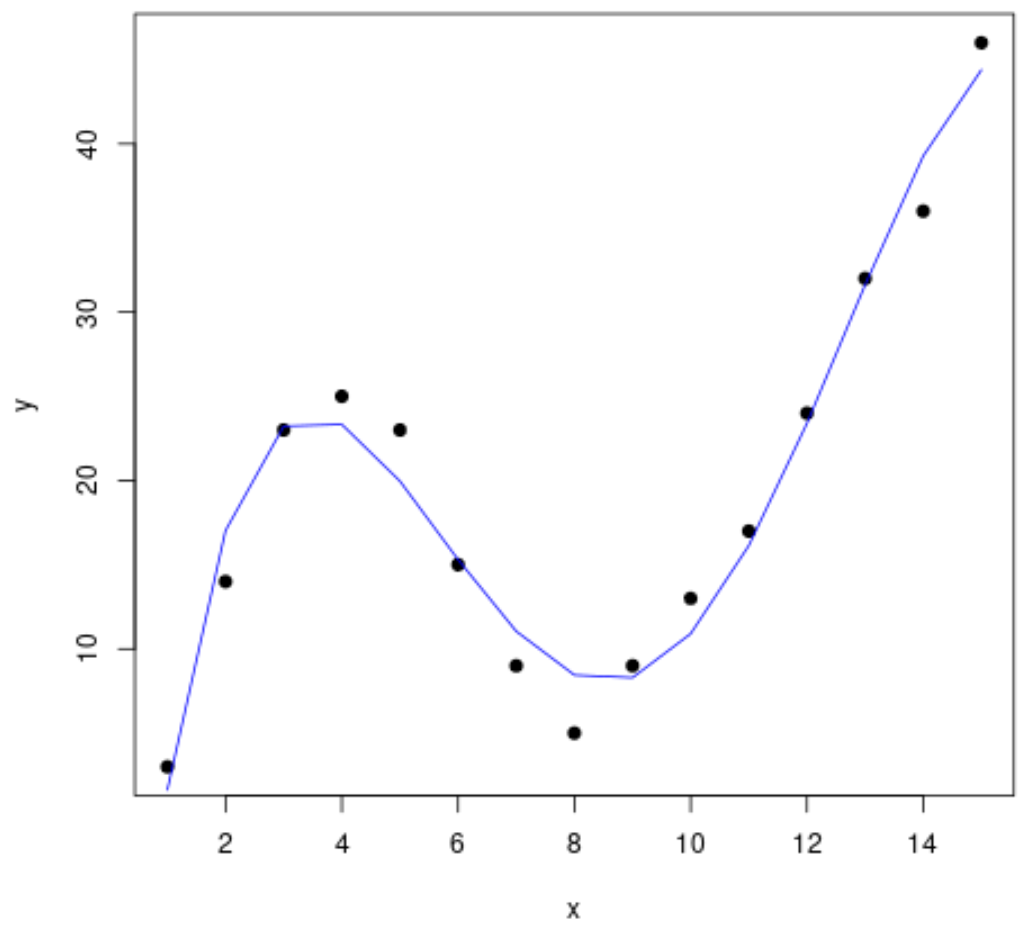
Zu guter Letzt können wir ein Streudiagramm mit der Kurve des Polynommodells vierten Grades erstellen:
#Erstellen eines Streudiagramms von x vs. y
plot(df$x, df$y, pch=19, xlab='x', ylab='y')
#X-Achsenwerte definieren
x_axis <- seq(1, 15, length=15)
#Kurve des Polynom-Modells vierten Grades hinzufügen
lines(x_axis, predict(fit4, data.frame(x=x_axis)), col='blue')
Wir können die Gleichung für diese Linie auch mit der Funktion summary() ermitteln:
summary(fit4)
Call:
lm(formula = y ~ poly(x, 4, raw = TRUE), data = df)
Residuals:
Min 1Q Median 3Q Max
-3.4490 -1.1732 0.6023 1.4899 3.0351
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -26.51615 4.94555 -5.362 0.000318 ***
poly(x, 4, raw = TRUE)1 35.82311 3.98204 8.996 4.15e-06 ***
poly(x, 4, raw = TRUE)2 -8.36486 0.96791 -8.642 5.95e-06 ***
poly(x, 4, raw = TRUE)3 0.70812 0.08954 7.908 1.30e-05 ***
poly(x, 4, raw = TRUE)4 -0.01924 0.00278 -6.922 4.08e-05 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.424 on 10 degrees of freedom
Multiple R-squared: 0.9707, Adjusted R-squared: 0.959
F-statistic: 82.92 on 4 and 10 DF, p-value: 1.257e-07
Die Gleichung der Kurve lautet wie folgt:
y = -0,0192x4 + 0,7081x3 - 8,3649x2 + 35,823x - 26,516
Wir können diese Gleichung verwenden, um den Wert der Antwortvariable auf der Grundlage der Vorhersagevariablen im Modell vorherzusagen. Wenn zum Beispiel x = 4 ist, würden wir vorhersagen, dass y = 23,34 ist:
y = -0,0192(4)4 + 0,7081(4)3 - 8,3649(4)2 + 35,823(4) - 26,516 = 23,34
Einführung in die polynomiale Regression
Polynomielle Regression in R (Schritt-für-Schritt)
Verwendung der Funktion seq in R
Ein Log-Log-Diagramm ist ein Diagramm, das sowohl auf der x-Achse als auch auf der y-Achse logarithmische Skalen verwendet.
Diese Art von Diagramm ist nützlich, um zwei Variablen zu visualisieren, wenn …
Bei der Verwendung von Klassifizierungsmodellen beim maschinellen Lernen verwenden wir häufig zwei Metriken, um die Qualität des Modells zu bewerten, nämlich Präzision und Erinnerung.
Precision: Korrigieren Sie positive Vorhersagen im …