
Sie können die folgende Formel verwenden, um eine Median-IF-Funktion in Google Tabellen auszuführen:
=MEDIAN(IF(GROUP_RANGE=VALUE, MEDIAN_RANGE))
Diese Formel findet den Mittelwert aller Zellen in einem bestimmten Bereich, die …
Bootstrapping ist eine Methode, mit der der Standardfehler einer Statistik geschätzt und ein Konfidenzintervall für die Statistik erstellt werden kann.
Der grundlegende Prozess für das Bootstrapping ist wie folgt:
Wir können Bootstrapping in R durchführen, indem wir die folgenden Funktionen aus der boot-Bibliothek verwenden:
1. Generieren Sie Bootstrap-Beispiele.
boot(data, statistic, r,…)
wo:
2. Generieren Sie ein Bootstrap-Konfidenzintervall.
boot.ci(bootobject, conf, type)
wo:
Die folgenden Beispiele zeigen, wie diese Funktionen in der Praxis eingesetzt werden.
Der folgende Code zeigt, wie der Standardfehler für dasR-Quadrat eines einfachen linearen Regressionsmodells berechnet wird:
set.seed(0)
library(boot)
# Definieren der Funktion zur Berechnung des R-Quadrats
rsq_function <- function(formula, data, indices) {
d <- data[indices,] #allows boot to select sample
fit <- lm(formula, data=d) #fit regression model
return(summary(fit)$r.square) #return R-squared of model
}
# Bootstrapping mit 2000 Replikationen durchführen
reps <- boot(data=mtcars, statistic=rsq_function, R=2000, formula=mpg~disp)
# Ergebnisse des Boostrappings anzeigen
reps
ORDINARY NONPARAMETRIC BOOTSTRAP
Call:
boot(data = mtcars, statistic = rsq_function, R = 2000, formula = mpg ~
disp)
Bootstrap Statistics :
original bias std. error
t1* 0.7183433 0.002164339 0.06513426
Aus den Ergebnissen können wir sehen:
Wir können auch schnell die Verteilung der Bootstrap-Beispiele anzeigen:
plot(reps)

Wir können auch den folgenden Code verwenden, um das 95%-Konfidenzintervall für das geschätzte R-Quadrat des Modells zu berechnen:
calculate adjusted bootstrap percentile (BCa) interval
#Angepasstes Bootstrap Percentil (BCa) Intervall berechnen
boot.ci(reps, type="bca")
CALL:
boot.ci(boot.out = reps, type = "bca")
Intervals:
Level BCa
95% ( 0.5350, 0.8188 )
Calculations and Intervals on Original Scale
Aus der Ausgabe können wir ersehen, dass das 95% Bootstrap-Konfidenzintervall für die wahren R-Quadrat-Werte (.5350, .8188) beträgt.
Der folgende Code zeigt, wie der Standardfehler für jeden Koeffizienten in einem multiplen linearen Regressionsmodell berechnet wird:
set.seed(0)
library(boot)
#Funktion zur Berechnung angepasster Regressionskoeffizienten definieren
coef_function <- function(formula, data, indices) {
d <- data[indices,] #allows boot to select sample
fit <- lm(formula, data=d) #fit regression model
return(coef(fit)) #return coefficient estimates of model
}
#Bootstrapping mit 2000 Replikationen durchführen
reps <- boot(data=mtcars, statistic=coef_function, R=2000, formula=mpg~disp)
#Ergebnisse des Boostrappings anzeigen
reps
ORDINARY NONPARAMETRIC BOOTSTRAP
Call:
boot(data = mtcars, statistic = coef_function, R = 2000, formula = mpg ~
disp)
Bootstrap Statistics :
original bias std. error
t1* 29.59985476 -5.058601e-02 1.49354577
t2* -0.04121512 6.549384e-05 0.00527082
Aus den Ergebnissen können wir sehen:
Wir können auch schnell die Verteilung der Bootstrap-Beispiele anzeigen:
plot(reps, index=1) #intercept of model
plot(reps, index=2) #disp predictor variable
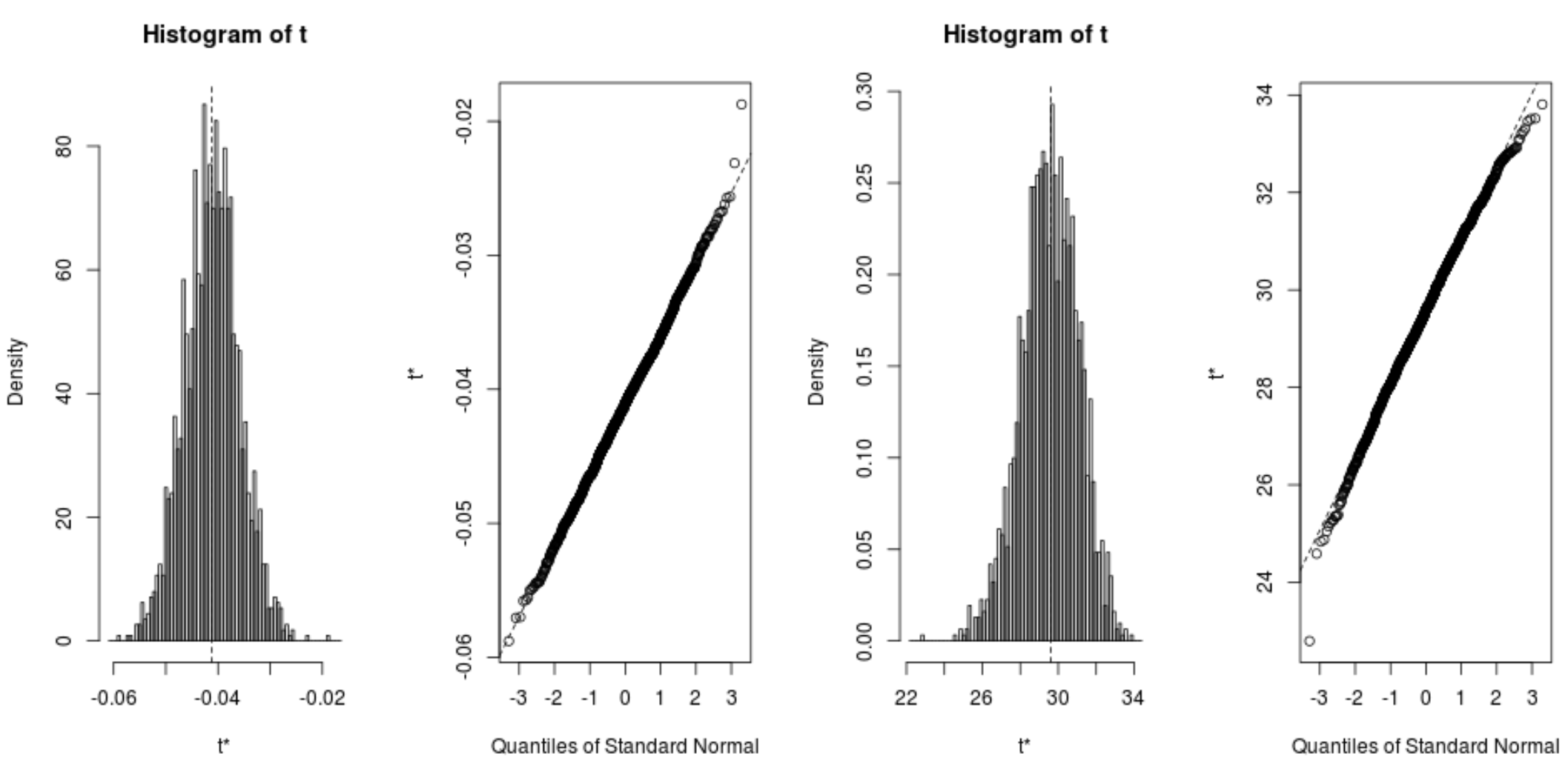
Wir können auch den folgenden Code verwenden, um die 95%-Konfidenzintervalle für jeden Koeffizienten zu berechnen:
#Angepasstes Bootstrap Percentil (BCa) Intervall berechnen
boot.ci(reps, type="bca", index=1) #intercept of model
boot.ci(reps, type="bca", index=2) #disp predictor variable
CALL:
boot.ci(boot.out = reps, type = "bca", index = 1)
Intervals:
Level BCa
95% (26.78, 32.66 )
Calculations and Intervals on Original Scale
BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
Based on 2000 bootstrap replicates
CALL:
boot.ci(boot.out = reps, type = "bca", index = 2)
Intervals:
Level BCa
95% (-0.0520, -0.0312 )
Calculations and Intervals on Original Scale
Aus der Ausgabe können wir ersehen, dass die 95% Bootstrap-Konfidenzintervalle für die Modellkoeffizienten wie folgt sind:
So führen Sie eine einfache lineare Regression in R durch
So führen Sie eine mehrfache lineare Regression in R durch
Einführung in Konfidenzintervalle
Sie können die folgende Formel verwenden, um eine Median-IF-Funktion in Google Tabellen auszuführen:
=MEDIAN(IF(GROUP_RANGE=VALUE, MEDIAN_RANGE))
Diese Formel findet den Mittelwert aller Zellen in einem bestimmten Bereich, die …
Die prozentuale Änderung der Werte zwischen einer Periode und einer anderen Periode wird wie folgt berechnet:
Prozentuale Änderung = (Wert 2 – Wert 1 ) / Wert 1 * 100
Angenommen, ein Unternehmen macht in …