
Eine einfaktorielle ANOVA wird verwendet, um zu bestimmen, ob es einen statistisch signifikanten Unterschied zwischen den Mittelwerten von drei oder mehr unabhängigen Gruppen gibt oder nicht.
Das folgende Beispiel bietet …
Eine einfaktorielle ANOVA ist ein statistischer Test, mit dem festgestellt wird, ob zwischen den Mittelwerten von drei oder mehr unabhängigen Gruppen ein signifikanter Unterschied besteht oder nicht.
Hier ist ein Beispiel dafür, wann wir eine einfaktorielle ANOVA verwenden könnten:
Sie teilen eine Klasse von 90 Schülern nach dem Zufallsprinzip in drei Gruppen zu je 30 Personen auf. Jede Gruppe verwendet einen Monat lang eine andere Lerntechnik, um sich auf eine Prüfung vorzubereiten. Am Ende des Monats legen alle Schüler die gleiche Prüfung ab.
Sie möchten wissen, ob sich die Lerntechnik auf die Prüfungsergebnisse auswirkt, und führen eine einfaktorielle ANOVA durch, um festzustellen, ob zwischen den Durchschnittswerten der drei Gruppen ein statistisch signifikanter Unterschied besteht.
Bevor wir eine einfaktorielle ANOVA durchführen können, müssen wir zunächst überprüfen, ob drei Annahmen erfüllt sind.
1. Normalverteilung – Jede Stichprobe wurde aus einer normalverteilten Population gezogen.
2. Gleiche Varianzen – Die Varianzen der Populationen, aus denen die Proben stammen, sind gleich.
3. Unabhängigkeit – Die Beobachtungen in jeder Gruppe sind unabhängig voneinander und die Beobachtungen innerhalb der Gruppen wurden durch eine Zufallsstichprobe erhalten.
Wenn diese Annahmen nicht erfüllt sind, können die Ergebnisse unserer einfaktorielle ANOVA unzuverlässig sein.
In diesem Beitrag erklären wir, wie Sie diese Annahmen überprüfen und was zu tun ist, wenn eine der Annahmen verletzt wird.
ANOVA geht davon aus, dass jede Stichprobe aus einer normalverteilten Population stammt.
Um diese Annahme zu überprüfen, können wir zwei Ansätze verwenden:
Angenommen, wir rekrutieren 90 Personen, um an einem Gewichtsverlust-Experiment teilzunehmen, bei dem wir zufällig 30 Personen zuweisen, die einen Monat lang entweder Programm A, Programm B oder Programm C folgen. Um festzustellen, ob sich das Programm auf den Gewichtsverlust auswirkt, möchten wir eine einfaktorielle ANOVA durchführen. Der folgende Code zeigt, wie die Annahme der Normalverteilung mithilfe von Histogrammen, Q-Q-Plots und einem Shapiro-Wilk-Test überprüft wird.
1. ANOVA-Modell montieren.
#Machen Sie dieses Beispiel reproduzierbar
set.seed (0)
#Dataframe erstellen
data <- data.frame(program = rep(c("A", "B", "C"), each = 30), weight_loss = c(runif(30, 0, 3), runif(30, 0, 5), runif (30, 1, 7)))
#Passen Sie das einfaktorielle ANOVA-Modell an
model <- aov(weight_loss ~ program, data = data)
2. Erstellen Sie ein Histogramm der Antwortwerte.
#Histogramm erstellen
hist(data$weight_loss)
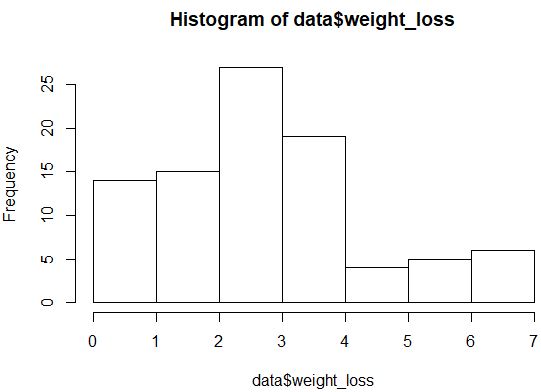
Die Verteilung sieht nicht sehr normal verteilt aus (z. B. hat sie keine Glockenform), aber wir können auch ein Q-Q-Diagramm erstellen, um einen weiteren Blick auf die Verteilung zu erhalten.
3. Erstellen Sie ein Q-Q-Diagramm der Residuen
#Erstellen Sie ein Q-Q-Diagramm, um diesen Datensatz mit einer theoretischen Normalverteilung zu vergleichen
qqnorm(model$residuals) #gerade diagonale Linie zum Plot hinzufügen
qqline(model$residuals)

Wenn die Datenpunkte in einem Q-Q-Diagramm entlang einer geraden diagonalen Linie fallen, folgt der Datensatz im Allgemeinen wahrscheinlich einer Normalverteilung. In diesem Fall können wir feststellen, dass es eine merkliche Abweichung von der Linie entlang der Endenden gibt, die möglicherweise darauf hinweist, dass die Daten nicht normal verteilt sind.
4. Führen Sie einen Shapiro-Wilk-Test auf Normalverteilung durch.
#Shapiro-Wilk-Test auf Normalverteilung durchführen
shapiro.test(data$weight_loss)
#Shapiro-Wilk normality test
#
#data: data$weight_loss
#W = 0.9587, p-value = 0.005999
Der Shapiro-Wilk-Test testet die Nullhypothese, dass die Proben aus einer Normalverteilung stammen, gegenüber der alternativen Hypothese, dass die Proben nicht aus einer Normalverteilung stammen. In diesem Fall beträgt der p-Wert des Tests 0,005999, was weniger als der Alpha-Wert von 0,05 ist. Dies deutet darauf hin, dass die Proben keine Normalverteilung aufweisen.
Im Allgemeinen wird eine einfaktorielle ANOVA als ziemlich robust gegen Verstöße gegen die Annahme der Normalverteilung angesehen, solange die Stichprobengrößen ausreichend groß sind.
Wenn Sie extrem große Stichproben haben, zeigen statistische Tests wie der Shapiro-Wilk-Test fast immer an, dass Ihre Daten nicht normal sind. Aus diesem Grund ist es häufig am besten, Ihre Daten mithilfe von Diagrammen wie Histogrammen und Q-Q-Plots visuell zu überprüfen. Durch einfaches Betrachten der Diagramme erhalten Sie eine ziemlich gute Vorstellung davon, ob die Daten normal verteilt sind oder nicht.
Wenn die Annahme der Normalverteilung schwer verletzt wird oder Sie nur besonders konservativ sein möchten, haben Sie zwei Möglichkeiten:
(1) Transformieren Sie die Antwortwerte Ihrer Daten so, dass die Verteilungen normaler verteilt sind.
(2) Führen Sie einen äquivalenten nichtparametrischen Test wie einen Kruskal-Wallis-Test durch, für den keine Annahme von Normalverteilung erforderlich ist.
ANOVA geht davon aus, dass die Varianzen der Populationen, aus denen die Proben stammen, gleich sind.
Wir können diese Annahme in R mit zwei Ansätzen überprüfen:
Der folgende Code veranschaulicht die Vorgehensweise unter Verwendung des gleichen synthetischen Gewichtsverlust-Datensatzes, den wir zuvor erstellt haben.
1. Erstellen Sie Boxplots.
#Erstellen Sie Box-Plots, die die Verteilung des Gewichtsverlusts für jede Gruppe anzeigen
boxplot(weight_loss ~ program, xlab='Program', ylab='Weight Loss', data=data)
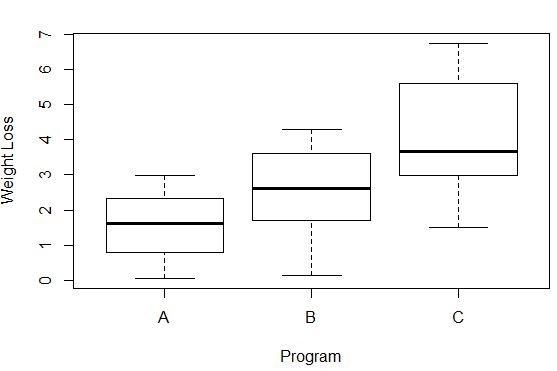
Die Varianz des Gewichtsverlusts in jeder Gruppe kann durch die Länge jedes Boxplots gesehen werden. Je länger die Box ist, desto höher ist die Varianz. Zum Beispiel können wir sehen, dass die Varianz für Teilnehmer an Programm C etwas höher ist als für Programm A und Programm B.
2. Führen Sie den Bartlett-Test durch.
#Erstellen Sie Box-Plots, die die Verteilung des Gewichtsverlusts für jede Gruppe anzeigen
bartlett.test(weight_loss ~ program, data=data)
#Bartlett test of homogeneity of variances
#
#data: weight_loss by program
#Bartlett's K-squared = 8.2713, df = 2, p-value = 0.01599
Der Bartlett-Test testet die Nullhypothese, dass die Proben gleiche Varianzen aufweisen, gegenüber der alternativen Hypothese, dass die Proben nicht gleiche Varianzen aufweisen. In diesem Fall beträgt der p-Wert des Tests 0,01599, was weniger als der alpha-Wert von 0,05 ist. Dies deutet darauf hin, dass die Proben nicht alle gleiche Varianzen aufweisen.
Im Allgemeinen wird eine einfaktorielle ANOVA als ziemlich robust gegen Verstöße gegen die Annahme gleicher Varianzen angesehen, solange jede Gruppe dieselbe Stichprobengröße hat.
Wenn jedoch die Stichprobengrößen nicht gleich sind und diese Annahme stark verletzt wird, können Sie stattdessen einen Welch-Test, einen Brown-and-Forsythe-Test oder einen Kruskal-Wallist-Test anstelle einer ANOVA durchführen.
ANOVA geht davon aus:
Es gibt keinen formalen Test, mit dem Sie überprüfen können, ob die Beobachtungen in jeder Gruppe unabhängig sind und ob sie durch eine Zufallsstichprobe erhalten wurden. Diese Annahme kann nur erfüllt werden, wenn ein randomisiertes Auswahlverfahren verwendet wurde.
Leider können Sie nur sehr wenig tun, wenn diese Annahme verletzt wird. Einfach ausgedrückt, wenn die Daten so gesammelt wurden, dass die Beobachtungen in jeder Gruppe nicht unabhängig von Beobachtungen in anderen Gruppen sind, oder wenn die Beobachtungen in jeder Gruppe nicht durch einen randomisierten Prozess erhalten wurden, sind die Ergebnisse der ANOVA unzuverlässig.
Wenn diese Annahme verletzt wird, ist es am besten, das Experiment erneut so einzurichten, dass ein zufälliges Design verwendet wird.
Weiterführende Literatur:
So führen Sie eine einfaktorielle ANOVA in R durch
So führen Sie eine einfaktorielle ANOVA in Excel durch
So führen Sie eine einfaktorielle ANOVA von Hand durch
So führen Sie eine einfaktorielle ANOVA in Stata durch
Eine einfaktorielle ANOVA wird verwendet, um zu bestimmen, ob es einen statistisch signifikanten Unterschied zwischen den Mittelwerten von drei oder mehr unabhängigen Gruppen gibt oder nicht.
Das folgende Beispiel bietet …
Eine geschachtelte ANOVA ist eine Art ANOVA („Varianzanalyse“), bei der mindestens ein Faktor in einem anderen Faktor verschachtelt ist.
Nehmen wir zum Beispiel an, ein Forscher möchte wissen, ob drei …