
Um die Leistung eines Modells in einem Datensatz zu bewerten, müssen wir messen, wie gut die vom Modell gemachten Vorhersagen mit den beobachteten Daten übereinstimmen.
Die gebräuchlichste Methode, um dies …
Im Bereich des maschinellen Lernens erstellen wir häufig Modelle, um genaue Vorhersagen über bestimmte Phänomene zu treffen.
Angenommen, wir möchten ein Regressionsmodell erstellen, das die für das Lernen aufgewendeten Stunden der Prädiktorvariablen verwendet, um die Punktzahl der Antwortvariablen für Schüler der High School vorherzusagen.
Um dieses Modell zu erstellen, sammeln wir Daten über die Stunden des Studiums und die entsprechende Punktzahl für Hunderte von Schülern in einem bestimmten Schulbezirk.
Dann werden wir diese Daten verwenden, um ein Modell zu trainieren, das Vorhersagen über die Punktzahl treffen kann, die ein bestimmter Schüler auf der Grundlage seiner gesamten Lernstunden erhält.
Um zu beurteilen, wie nützlich das Modell ist, können wir messen, wie gut die Modellvorhersagen mit den beobachteten Daten übereinstimmen. Eine der am häufigsten verwendeten Metriken ist der mittlere quadratische Fehler (MSE), der wie folgt berechnet wird:
MSE = (1 / n) * Σ (y i - f (x i )) 2
wo:
Je näher die Modellvorhersagen an den Beobachtungen liegen, desto kleiner wird die MSE.
Einer der größten Fehler beim maschinellen Lernen ist jedoch die Optimierung von Modellen, um den Trainings-MSE zu reduzieren - d.h.wie genau die Modellvorhersagen mit den Daten übereinstimmen, die wir zum Trainieren des Modells verwendet haben.
Wenn sich ein Modell zu sehr auf die Reduzierung der Trainings-MSE konzentriert, ist es oft zu schwierig, Muster in den Trainingsdaten zu finden, die nur zufällig verursacht werden. Wenn das Modell dann auf unbekannte Daten angewendet wird, ist die Leistung schlecht.
Dieses Phänomen ist als Überanpassung bekannt. Dies tritt auf, wenn wir ein Modell zu eng an die Trainingsdaten anpassen und so ein Modell erstellen, das für Vorhersagen über neue Daten nicht nützlich ist.
Um die Überanpassung zu verstehen, kehren wir zum Beispiel der Erstellung eines Regressionsmodells zurück, bei dem anhand der Lernstunden die Punktzahl vorhergesagt wird.
Angenommen, wir sammeln Daten für 100 Schüler in einem bestimmten Schulbezirk und erstellen ein schnelles Streudiagramm, um die Beziehung zwischen den beiden Variablen zu visualisieren:
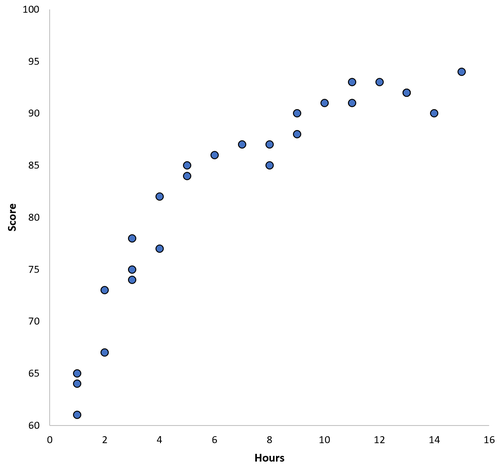
Die Beziehung zwischen den beiden Variablen scheint quadratisch zu sein. Nehmen wir also an, wir passen das folgende quadratische Regressionsmodell an:
Punktzahl = 60,1 + 5,4 * (Stunden) - 0,2 * (Stunden) 2
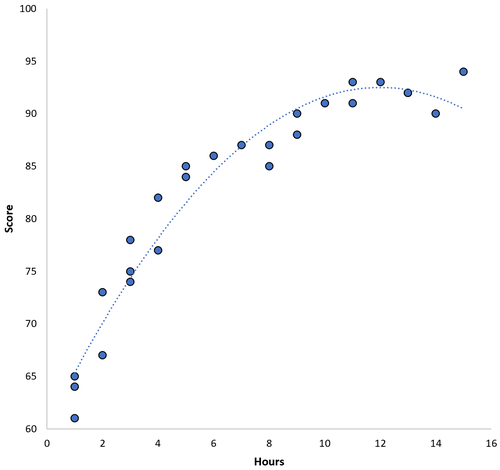
Dieses Modell hat einen mittleren Trainingsfehler (MSE) von 3,45. Das heißt, die mittlere quadratische Differenz zwischen den vom Modell gemachten Vorhersagen und den tatsächlichen Werten beträgt 3,45.
Wir könnten diesen Trainings-MSE jedoch reduzieren, indem wir ein Polynommodell höherer Ordnung anpassen. Angenommen, wir passen das folgende Modell an:
Punktzahl = 64,3 - 7,1 * (Stunden) + 8,1 * (Stunden) 2 - 2,1 * (Stunden) 3 + 0,2 * (Stunden) 4 - 0,1 * (Stunden) 5 + 0,2 (Stunden) 6
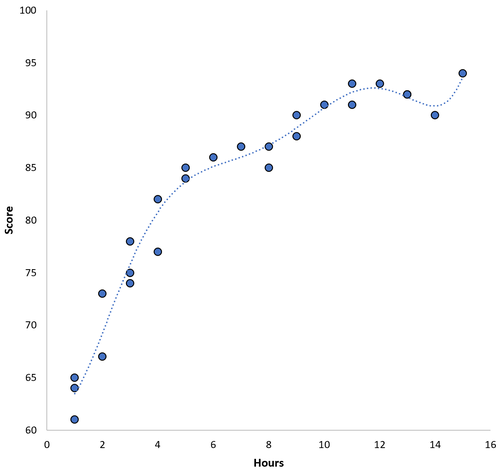
Beachten Sie, wie die Regressionslinie die tatsächlichen Daten viel enger umschließt als die vorherige Regressionslinie.
Dieses Modell hat einen mittleren Trainingsfehler (MSE) von nur 0,89. Das heißt, die mittlere quadratische Differenz zwischen den vom Modell gemachten Vorhersagen und den tatsächlichen Werten beträgt 0,89.
Dieser Trainings-MSE ist viel kleiner als die des Vorgängermodells.
Der Trainings-MSE ist uns jedoch nicht wirklich wichtig - d.h.wie genau die Modellvorhersagen mit den Daten übereinstimmen, die wir zum Trainieren des Modells verwendet haben. Stattdessen kümmern wir uns hauptsächlich um den Test-MSE - den MSE, wenn unser Modell auf unbekannte Daten angewendet wird.
Wenn wir das Polynom-Regressionsmodell höherer Ordnung oben auf einen unbekannten Datensatz anwenden würden, würde es wahrscheinlich schlechter abschneiden als das einfachere quadratische Regressionsmodell. Das heißt, es würde einen höheren Test-MSE erzeugen, was genau das ist, was wir nicht wollen.
Der einfachste Weg, eine Überanpassung zu erkennen, ist die Durchführung einer Kreuzvalidierung. Die am häufigsten verwendete Methode ist als k-fache Kreuzvalidierung bekannt und funktioniert wie folgt:
Schritt 1: Teilen Sie einen Datensatz nach dem Zufallsprinzip in k Gruppen oder „Falten“ von ungefähr gleicher Größe.
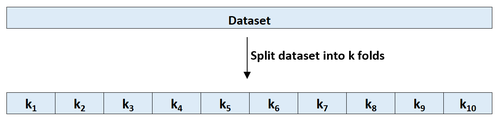
Schritt 2: Wählen Sie eine der Falten als Holdout-Set. Bringen Sie das Modell an den verbleibenden k-1-Falten an. Berechnen Sie den Test-MSE anhand der Beobachtungen in der herausgehaltenen Falte.
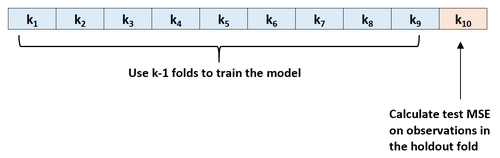
Schritt 3: Wiederholen Sie diesen Vorgang k-mal, wobei Sie jedes Mal einen anderen Datensatz als Holdout-Satz verwenden.
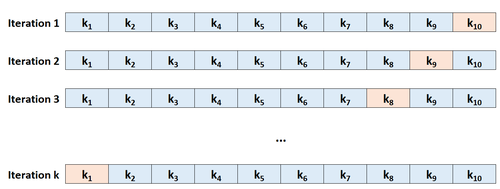
Schritt 4: Berechnen Sie den Gesamttest-MSE als Durchschnitt der k-Test-MSEs.
Test MSE = (1 / k) * ΣMSE i
wo:
Dieser Test-MSE gibt uns eine gute Vorstellung davon, wie sich ein bestimmtes Modell auf unbekannte Daten auswirkt.
In der Praxis können wir mehrere verschiedene Modelle anpassen und für jedes Modell eine k-fache Kreuzvalidierung durchführen, um den Test-MSE herauszufinden. Dann können wir das Modell mit dem niedrigsten Test-MSE als das beste Modell für zukünftige Vorhersagen auswählen.
Dies stellt sicher, dass wir ein Modell auswählen, das bei zukünftigen Daten wahrscheinlich die beste Leistung erbringt, im Gegensatz zu einem Modell, das lediglich den Trainings-MSE minimiert und historische Daten gut „anpasst“.
Was ist der Bias-Varianz-Kompromiss beim maschinellen Lernen?
Eine Einführung in die K-Fold-Kreuzvalidierung
Regression vs. Klassifikationsmodelle im maschinellen Lernen
Um die Leistung eines Modells in einem Datensatz zu bewerten, müssen wir messen, wie gut die vom Modell gemachten Vorhersagen mit den beobachteten Daten übereinstimmen.
Die gebräuchlichste Methode, um dies …
Um die Leistung eines Modells in einem Datensatz zu bewerten, müssen wir messen, wie gut die vom Modell gemachten Vorhersagen mit den beobachteten Daten übereinstimmen.
Die gebräuchlichste Methode, um dies …