
Bei der Interpolation wird ein unbekannter Wert einer Funktion zwischen zwei bekannten Werten geschätzt.
Wenn zwei bekannte Werte (x 1 , y 1 ) und (x 2 , y 2 ) gegeben sind, können …
Um die Leistung eines Modells in einem Datensatz zu bewerten, müssen wir messen, wie gut die Modellvorhersagen mit den beobachteten Daten übereinstimmen.
Für Regressionsmodelle ist die am häufigsten verwendete Metrik der mittlere quadratische Fehler (MSE), der wie folgt berechnet wird:
MSE = (1 / n) * Σ (y i - f (x i )) 2
wo:
Je näher die Modellvorhersagen an den Beobachtungen liegen, desto kleiner wird der MSE.
Wir kümmern uns jedoch nur um Test-MSE - der MSE, wenn unser Modell auf unbekannte Daten angewendet wird. Dies liegt daran, dass wir uns nur darum kümmern, wie das Modell mit unbekannt Daten und nicht mit vorhandenen Daten funktioniert.
Zum Beispiel ist es schön, wenn ein Modell, das Börsenkurse vorhersagt, einen niedrigen MSE für historische Daten aufweist, aber wir möchten das Modell wirklich verwenden können, um zukünftige Daten genau vorherzusagen.
Es stellt sich heraus, dass die Test-MSE immer in zwei Teile zerlegt werden kann:
(1) Die Varianz: Bezieht sich auf den Betrag, um den sich unsere Funktion f ändern würde, wenn wir sie unter Verwendung eines anderen Trainingssatzes schätzen würden.
(2) Die Verzerrung: Bezieht sich auf den Fehler, der durch die Annäherung eines realen Problems, das äußerst kompliziert sein kann, durch ein viel einfacheres Modell entsteht.
In mathematischen Begriffen geschrieben:
Test MSE = Var ( f̂ ( x 0 )) + [Bias ( f̂ ( x 0 ))] 2 + Var (ε)
Test MSE = Varianz + Verzerrung 2 + Irreduzibler Fehler
Der dritte Term, der irreduzible Fehler, ist der Fehler, der von keinem Modell reduziert werden kann, nur weil in der Beziehung zwischen dem Datensatz erklärender Variablen und der Antwortvariablen immer ein gewisses Rauschen vorhanden ist.
Modelle mit hoher Verzerrung weisen tendenziell eine geringe Varianz auf. Beispielsweise weisen lineare Regressionsmodelle tendenziell eine hohe Verzerrung (unter der Annahme einer einfachen linearen Beziehung zwischen erklärenden Variablen und Antwortvariablen) und eine geringe Varianz auf (Modellschätzungen ändern sich von einer Stichprobe zur nächsten nicht wesentlich).
Modelle mit geringer Verzerrung weisen jedoch tendenziell eine hohe Varianz auf. Beispielsweise neigen komplexe nichtlineare Modelle dazu, eine geringe Verzerrung (setzt keine bestimmte Beziehung zwischen erklärenden Variablen und Antwortvariablen voraus) mit hoher Varianz zu haben (Modellschätzungen können sich von einer Trainingsstichprobe zur nächsten stark ändern).
Der Bias-Varianz-Kompromiss bezieht sich auf den Kompromiss, der stattfindet, wenn wir uns dafür entscheiden, die Bias zu verringern, die typischerweise die Varianz erhöht, oder die Varianz zu verringern, die typischerweise die Bias erhöht.
Das folgende Diagramm bietet eine Möglichkeit, diesen Kompromiss zu visualisieren:
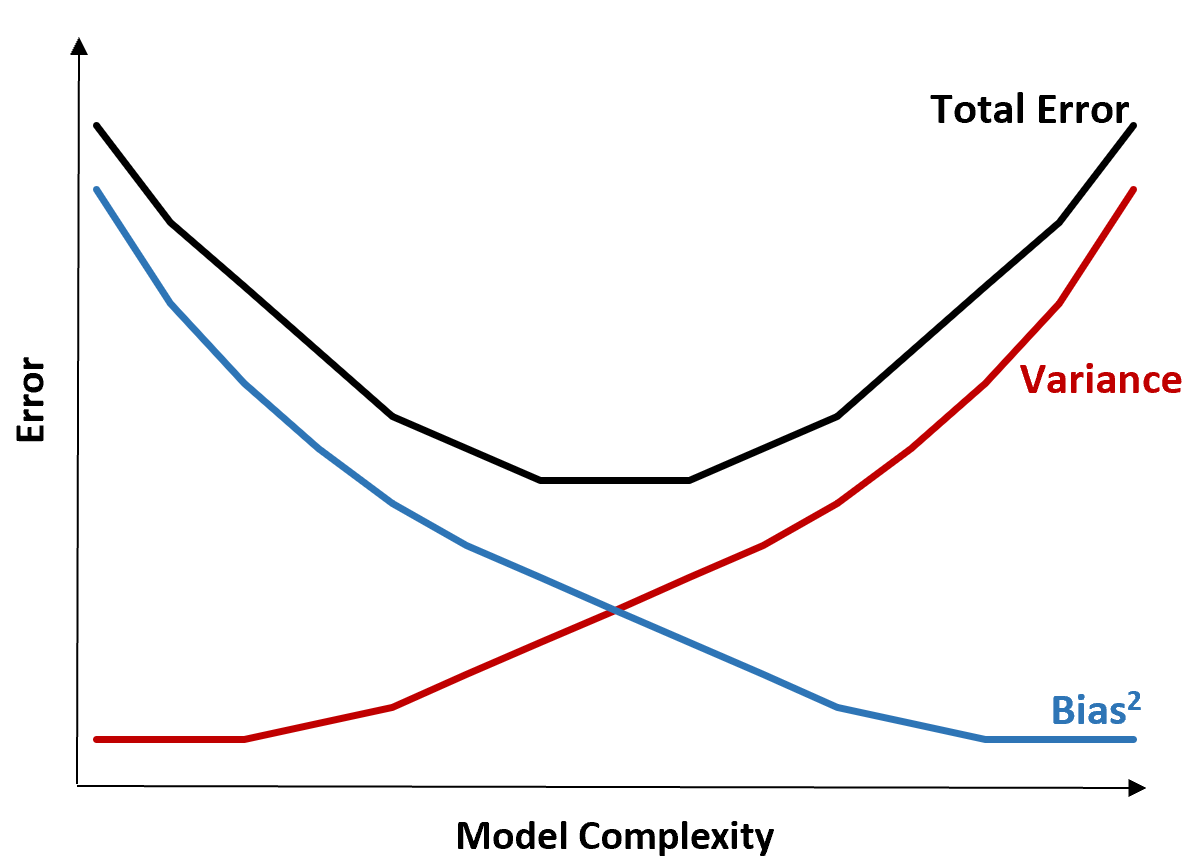
Der Gesamtfehler nimmt mit zunehmender Komplexität eines Modells ab, jedoch nur bis zu einem bestimmten Punkt. Ab einem bestimmten Punkt nimmt die Varianz zu und der Gesamtfehler nimmt ebenfalls zu.
In der Praxis geht es uns nur darum, den Gesamtfehler eines Modells zu minimieren, nicht unbedingt um die Varianz oder Verzerrung. Es stellt sich heraus, dass der Weg zur Minimierung des Gesamtfehlers darin besteht, das richtige Gleichgewicht zwischen Varianz und Bias zu finden.
Mit anderen Worten, wir wollen ein Modell, das komplex genug ist, um die wahre Beziehung zwischen den erklärenden Variablen und der Antwortvariablen zu erfassen, aber nicht übermäßig komplex, so dass Muster gefunden werden, die nicht wirklich existieren.
Wenn ein Modell zu komplex ist, passt es sich an die Daten an. Dies geschieht, weil es zu schwierig ist, Muster in den Trainingsdaten zu finden, die nur zufällig verursacht werden. Diese Art von Modell ist bei unbekannten Daten wahrscheinlich schlecht.
Wenn ein Modell jedoch zu einfach ist, werden die Daten nicht ausreichend berücksichtigt. Dies geschieht, weil davon ausgegangen wird, dass die wahre Beziehung zwischen den erklärenden Variablen und der Antwortvariablen einfacher ist als sie es tatsächlich ist.
Die Möglichkeit, optimale Modelle für das maschinelle Lernen auszuwählen, besteht darin, das Gleichgewicht zwischen Verzerrung und Varianz so zu finden, dass der Testfehler des Modells für zukünftige unbekannte Daten minimiert werden kann.
In der Praxis besteht die häufigste Methode zur Minimierung der Test-MSE in der Kreuzvalidierung.
Bei der Interpolation wird ein unbekannter Wert einer Funktion zwischen zwei bekannten Werten geschätzt.
Wenn zwei bekannte Werte (x 1 , y 1 ) und (x 2 , y 2 ) gegeben sind, können …
Gelegentlich möchten Sie möglicherweise die 10 wichtigsten Werte in einer Liste in Excel finden. Glücklicherweise ist dies mit der Funktion KGRÖSSTE(), die die folgende Syntax verwendet, einfach zu bewerkstelligen:
KGRÖSSTE …