
Im Bereich des maschinellen Lernens erstellen wir häufig Modelle, um genaue Vorhersagen über bestimmte Phänomene zu treffen.
Angenommen, wir möchten ein Regressionsmodell erstellen, das die für das Lernen aufgewendeten Stunden …
Um die Leistung eines Modells in einem Datensatz zu bewerten, müssen wir messen, wie gut die vom Modell gemachten Vorhersagen mit den beobachteten Daten übereinstimmen.
Die gebräuchlichste Methode, um dies zu messen, ist die Verwendung des mittleren quadratischen Fehlers (MSE), der wie folgt berechnet wird:
MSE = (1 / n) * Σ (y i - f (x i )) 2
wo:
Je näher die Modellvorhersagen an den Beobachtungen liegen, desto kleiner wird der MSE.
In der Praxis verwenden wir den folgenden Prozess, um der MSE eines bestimmten Modells zu berechnen:
1. Teilen Sie einen Datensatz in einen Trainingsdatensatz und einen Testdatensatz auf.
2. Erstellen Sie das Modell nur mit Daten aus dem Trainingsdatensatz.
3. Verwenden Sie das Modell, um Vorhersagen für den Testdatensatz zu treffen und den Test-MSE zu messen.
Der Test-MSE gibt uns eine Vorstellung davon, wie gut ein Modell mit Daten funktioniert, die es zuvor noch nicht gesehen hat. Der Nachteil der Verwendung nur eines Testdatensatzes besteht jedoch darin, dass der Test-MSE stark variieren kann, je nachdem, welche Beobachtungen in den Trainings- und Testsätzen verwendet wurden.
Eine Möglichkeit, dieses Problem zu vermeiden, besteht darin, ein Modell mehrmals mit einem anderen Trainings- und Testdatensatz anzupassen und dann den Test-MSE als Durchschnitt aller Test-MSEs zu berechnen.
Diese allgemeine Methode ist als Kreuzvalidierung bekannt, und eine spezifische Form davon ist als k-fache Kreuzvalidierung bekannt.
Die K-fache Kreuzvalidierung verwendet den folgenden Ansatz, um ein Modell zu bewerten:
Schritt 1: Teilen Sie einen Datensatz nach dem Zufallsprinzip in k Gruppen oder „Faltungen“ von ungefähr gleicher Größe.
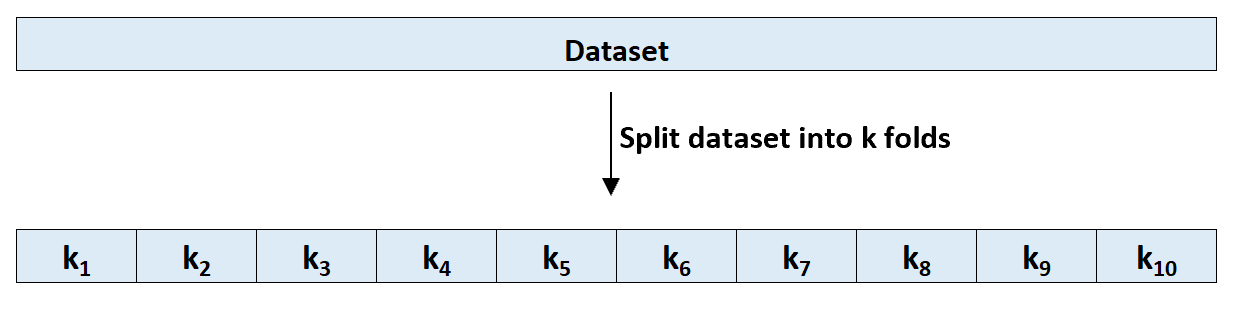
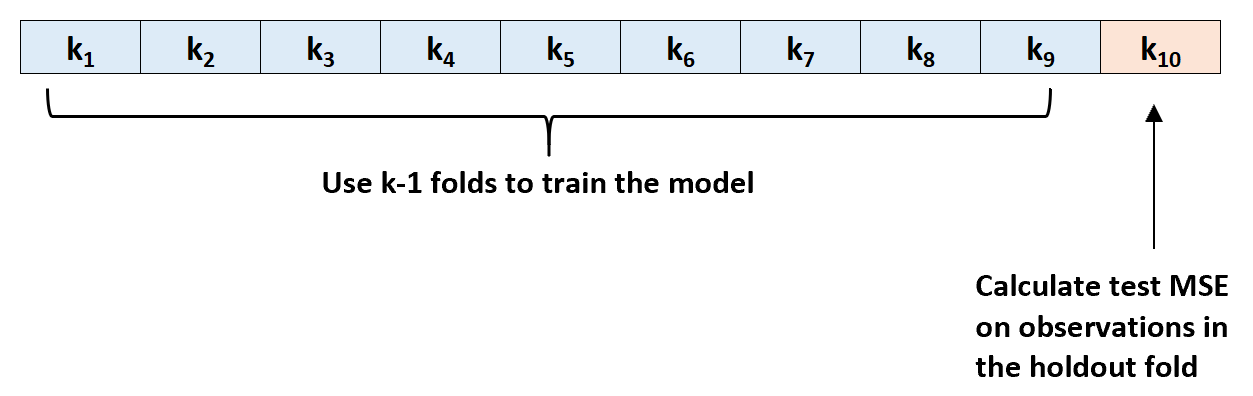
Schritt 2: Wählen Sie eine der Faltungen als Holdout-Set. Bringen Sie das Modell an den verbleibenden k-1-Faltungen an. Berechnen Sie den Test-MSE anhand der Beobachtungen in der herausgehaltenen Faltung.
Schritt 3: Wiederholen Sie diesen Vorgang k-mal, wobei Sie jedes Mal einen anderen Datensatz als Holdout-Satz verwenden.
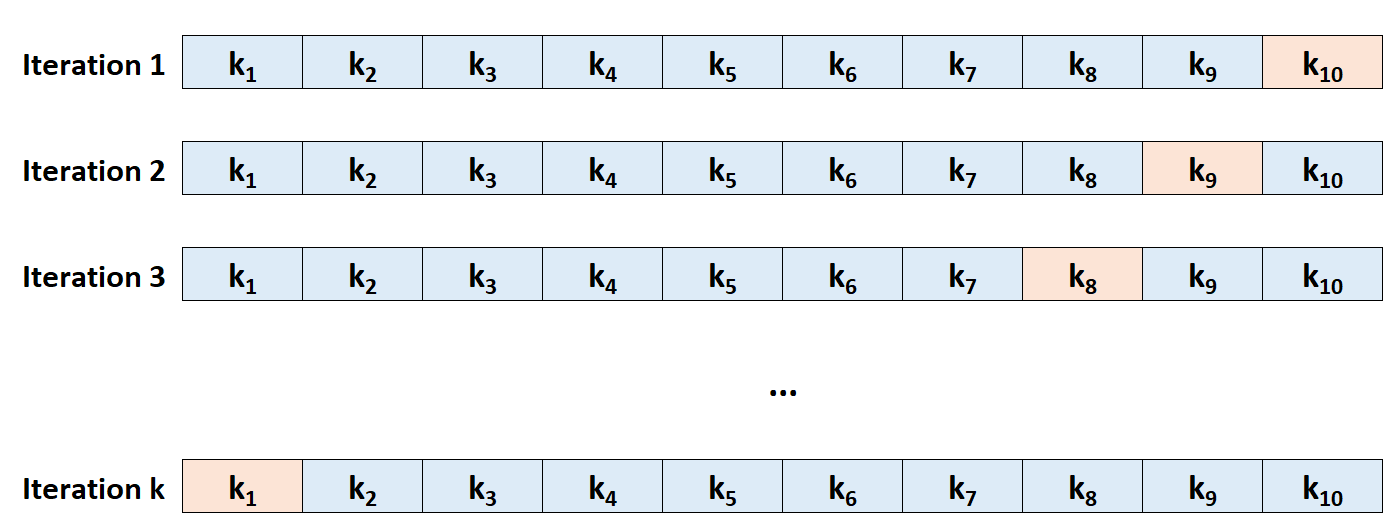
Schritt 4: Berechnen Sie den Gesamttest-MSE als Durchschnitt der k-Test-MSEs.
Test MSE = (1 / k) * ΣMSE i
wo:
Je mehr Faltungen wir bei der k-fachen Kreuzvalidierung verwenden, desto geringer ist im Allgemeinen die Abweichung der Test-MSE, aber desto höher ist die Varianz. Umgekehrt, je weniger Faltungen wir verwenden, desto höher ist die Vorspannung, aber desto geringer ist die Varianz. Dies ist ein klassisches Beispiel für den Bias-Varianz-Kompromiss beim maschinellen Lernen.
In der Praxis verwenden wir normalerweise zwischen 5 und 10 Faltungen. Wie in An Introduction to Statistical Learning erwähnt, hat sich gezeigt, dass diese Anzahl von Faltungen ein optimales Gleichgewicht zwischen Verzerrung und Varianz bietet und somit zuverlässige Schätzungen der Test-MSE liefert:
To summarize, there is a bias-variance trade-off associated with the choice of k in k-fold cross-validation.
Typically, given these considerations, one performs k-fold cross-validation using k = 5 or k = 10, as these values have been shown empirically to yield test error rate estimates that suffer neither from excessively high bias nor from very high variance.
-Seite 184, An Introduction to Statistical Learning
Wenn wir einen Datensatz in nur einen Trainingsdatensatz und einen Testdatensatz aufteilen, kann die anhand der Beobachtungen im Testdatensatz berechneten Test-MSE stark variieren, je nachdem, welche Beobachtungen in den Trainings- und Testsätzen verwendet wurden.
Durch die Verwendung der k-fachen Kreuzvalidierung können wir der Test-MSE unter Verwendung verschiedener Variationen von Trainings- und Testsätzen berechnen. Dies macht es für uns viel wahrscheinlicher, eine unvoreingenommene Schätzung der Test-MSE zu erhalten.
Die K-fache Kreuzvalidierung bietet auch einen Rechenvorteil gegenüber der einmaligen Kreuzvalidierung (LOOCV), da nur ein Modell k-mal und nicht n-mal angepasst werden muss.
Bei Modellen, deren Anpassung lange dauert, kann die k-fache Kreuzvalidierung den Test-MSE viel schneller als LOOCV berechnen. In vielen Fällen ist der von jedem Ansatz berechnete Test-MSE ziemlich ähnlich, wenn Sie eine ausreichende Anzahl von Faltungen verwenden.
Es gibt verschiedene Erweiterungen der k-fachen Kreuzvalidierung, darunter:
Wiederholte K-fache Kreuzvalidierung: Hier wird die k-fache Kreuzvalidierung einfach n-mal wiederholt. Jedes Mal, wenn die Trainings- und Testsätze gemischt werden, verringert dies die Verzerrung bei der Schätzung den Test-MSE weiter, obwohl dies länger dauert als die normale k-fache Kreuzvalidierung.
Leave-One-Out-Kreuzvalidierung: Dies ist ein Sonderfall der k-fachen Kreuzvalidierung mit k = n. Weitere Informationen zu dieser Methode finden Sie hier.
Stratifizierte K-fache Kreuzvalidierung: Dies ist eine Version der k-fachen Kreuzvalidierung, bei der der Datensatz so neu angeordnet wird, dass jede Faltung für das Ganze repräsentativ ist. Wie von Kohavi festgestellt, bietet diese Methode tendenziell einen besseren Kompromiss zwischen Verzerrung und Varianz im Vergleich zur gewöhnlichen k-fachen Kreuzvalidierung.
Im Bereich des maschinellen Lernens erstellen wir häufig Modelle, um genaue Vorhersagen über bestimmte Phänomene zu treffen.
Angenommen, wir möchten ein Regressionsmodell erstellen, das die für das Lernen aufgewendeten Stunden …
Um die Leistung eines Modells in einem Datensatz zu bewerten, müssen wir messen, wie gut die vom Modell gemachten Vorhersagen mit den beobachteten Daten übereinstimmen.
Die gebräuchlichste Methode, um dies …