
Ein Log-Log-Diagramm ist ein Diagramm, das sowohl auf der x-Achse als auch auf der y-Achse logarithmische Skalen verwendet.
Diese Art von Diagramm ist nützlich, um zwei Variablen zu visualisieren, wenn …
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist. Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz passt, können wir uns die folgenden zwei Metriken ansehen:
Eine Möglichkeit, diese beiden Metriken zu visualisieren, besteht darin, eine ROC-Kurve zu erstellen, die für „Receiver Operating Characteristic“-Kurve steht. Dies ist ein Diagramm, das die Sensitivität und Spezifität eines logistischen Regressionsmodells darstellt.
Das folgende Schritt-für-Schritt-Beispiel zeigt, wie Sie eine ROC-Kurve in Python erstellen und interpretieren.
Zuerst importieren wir die Pakete, die für die Durchführung der logistischen Regression in Python erforderlich sind:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
import matplotlib.pyplot as plt
Als Nächstes importieren wir einen Datensatz und passen ein logistisches Regressionsmodell daran an:
#Datensatz aus CSV-Datei auf Github importieren
url = "https://raw.githubusercontent.com/Statology/Python-Guides/main/default.csv"
data = pd.read_csv(url)
#definieren Sie die Prädiktorvariablen und die Antwortvariable
X = data[['student', 'balance', 'income']]
y = data['default']
#den Datensatz in Trainings- (70 %) und Testsätze (30 %) aufteilen
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=0)
#instanziiere das Modell
log_regression = LogisticRegression()
#passen Sie das Modell mithilfe der Trainingsdaten an
log_regression.fit(X_train,y_train)
Als Nächstes berechnen wir die Richtig-Positiv-Rate und die Falsch-Positiv-Rate und erstellen eine ROC-Kurve mit dem Matplotlib-Datenvisualisierungspaket:
#Metriken definieren
y_pred_proba = log_regression.predict_proba(X_test)[::,1]
fpr, tpr, _ = metrics.roc_curve(y_test, y_pred_proba)
# ROC-Kurve erstellen
plt.plot(fpr,tpr)
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
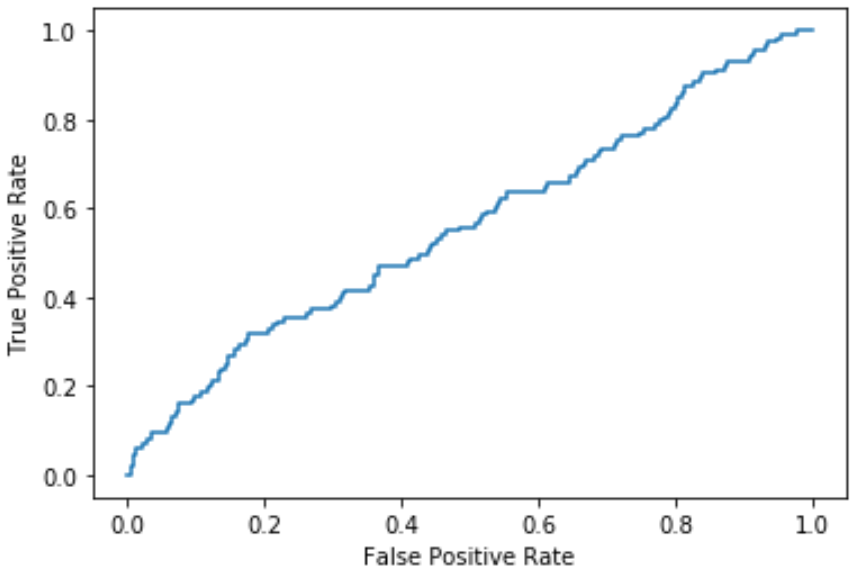
Je mehr die Kurve die linke obere Ecke des Diagramms umschließt, desto besser kann das Modell die Daten in Kategorien einteilen.
Wie wir aus dem Diagramm oben sehen können, leistet dieses logistische Regressionsmodell ziemlich schlechte Arbeit bei der Klassifizierung der Daten in Kategorien.
Um dies zu quantifizieren, können wir die AUC – Fläche unter der Kurve – berechnen, die uns sagt, wie viel des Plots sich unter der Kurve befindet.
Je näher AUC an 1 liegt, desto besser ist das Modell. Ein Modell mit einer AUC von 0,5 ist nicht besser als ein Modell, das zufällige Klassifizierungen vornimmt.
Wir können den folgenden Code verwenden, um die AUC des Modells zu berechnen und sie in der unteren rechten Ecke des ROC-Diagramms anzuzeigen:
#Metriken definieren
y_pred_proba = log_regression.predict_proba(X_test)[::,1]
fpr, tpr, _ = metrics.roc_curve(y_test, y_pred_proba)
auc = metrics.roc_auc_score(y_test, y_pred_proba)
# ROC-Kurve erstellen
plt.plot(fpr,tpr,label="AUC="+str(auc))
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.legend(loc=4)
plt.show()
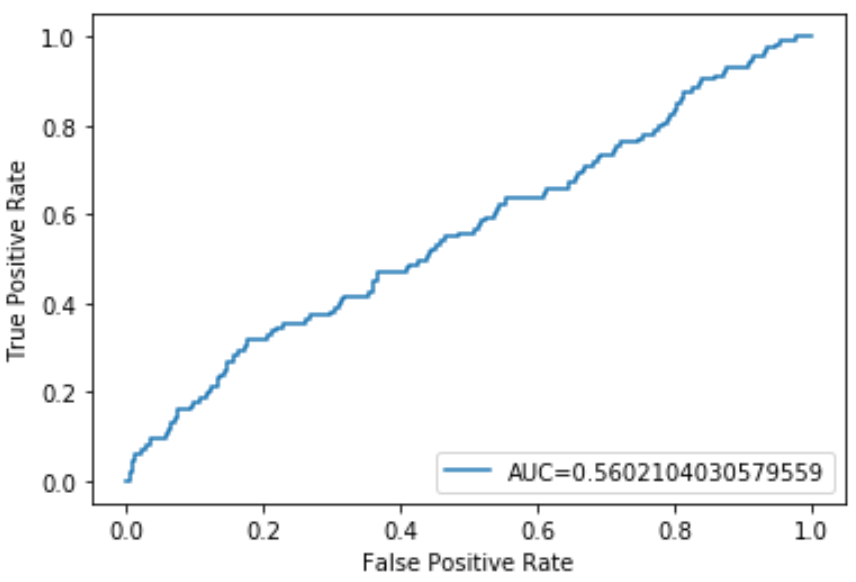
Die AUC für dieses logistische Regressionsmodell beträgt 0,5602. Da dies nahe bei 0,5 liegt, bestätigt dies, dass das Modell Daten schlecht klassifiziert.
Ein Log-Log-Diagramm ist ein Diagramm, das sowohl auf der x-Achse als auch auf der y-Achse logarithmische Skalen verwendet.
Diese Art von Diagramm ist nützlich, um zwei Variablen zu visualisieren, wenn …
Bei der Verwendung von Klassifizierungsmodellen beim maschinellen Lernen verwenden wir häufig zwei Metriken, um die Qualität des Modells zu bewerten, nämlich Präzision und Erinnerung.
Precision: Korrigieren Sie positive Vorhersagen im …