
Eine einfaktorielle ANOVA wird verwendet, um zu bestimmen, ob es einen statistisch signifikanten Unterschied zwischen den Mittelwerten von drei oder mehr unabhängigen Gruppen gibt oder nicht.
Das folgende Beispiel bietet …
Eine einfaktorielle ANOVA wird verwendet, um zu bestimmen, ob unterschiedliche Niveaus einer erklärenden Variablen zu statistisch unterschiedlichen Ergebnissen in einer Antwortvariablen führen oder nicht.
Zum Beispiel könnten wir daran interessiert sein zu verstehen, ob drei Bildungsstufen (Schulabschluss, Bachelor-Abschluss, Master-Abschluss) zu statistisch unterschiedlichen Jahreseinkommen führen oder nicht. In diesem Fall haben wir eine erklärende Variable und eine Antwortvariable.
Eine MANOVA ist eine Erweiterung der einfaktoriellen ANOVA, in der es mehr als eine Antwortvariable gibt. Zum Beispiel könnten wir daran interessiert sein zu verstehen, ob das Bildungsniveau zu unterschiedlichen Jahreseinkommen und unterschiedlichen Beträgen an Studentendarlehensschulden führt oder nicht. In diesem Fall haben wir eine erklärende Variable und zwei Antwortvariablen:
Da wir mehr als eine Antwortvariable haben, wäre es in diesem Fall angebracht, eine MANOVA zu verwenden.
Als nächstes erklären wir, wie eine MANOVA in Stata durchgeführt wird.
Um zu veranschaulichen, wie eine MANOVA in Stata durchgeführt wird, verwenden wir den folgenden Datensatz, der die folgenden drei Variablen für 24 Personen enthält:
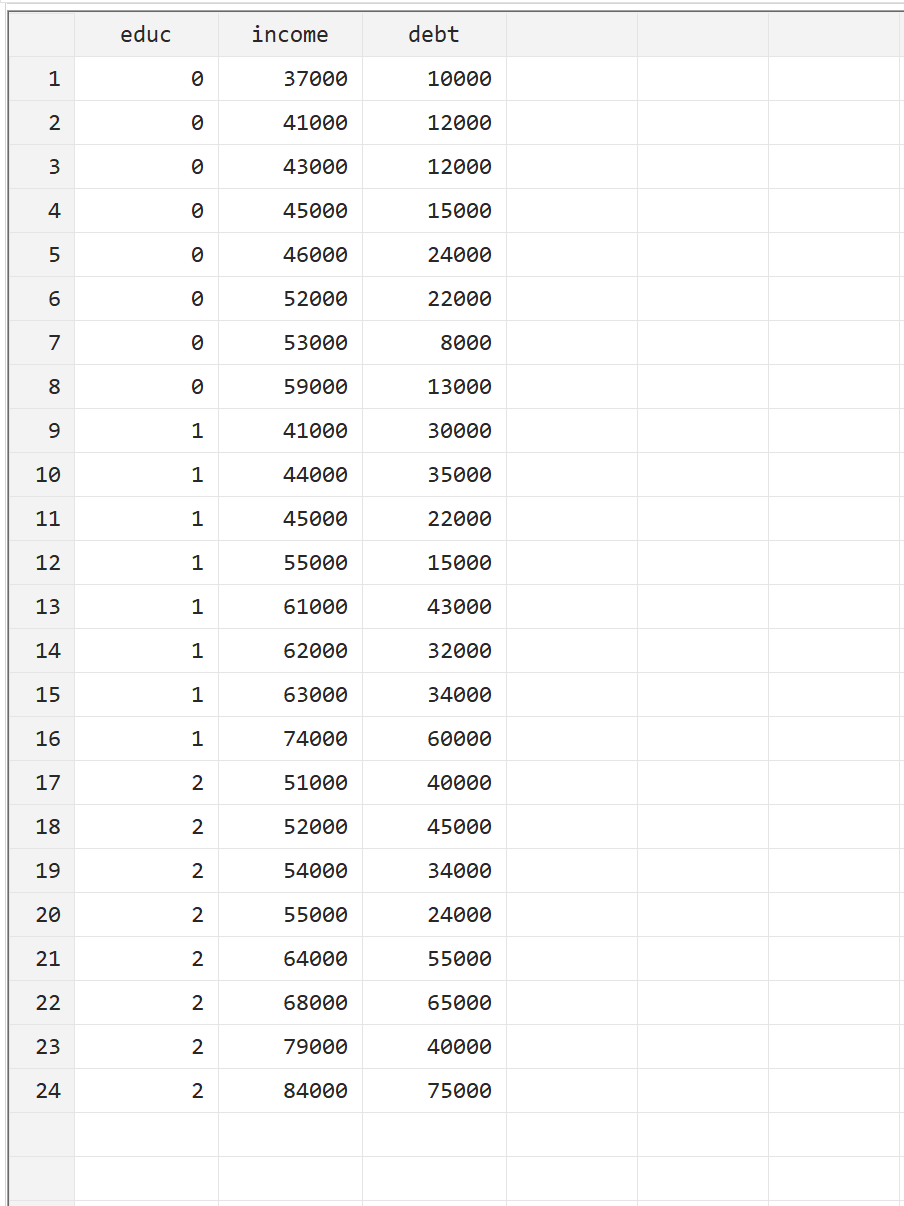
Sie können dieses Beispiel replizieren, indem Sie die Daten manuell selbst eingeben, indem Sie in der oberen Menüleiste zu Daten> Dateneditor> Dateneditor (Bearbeiten) gehen.
Um die MANOVA unter Verwendung von Bildung als erklärende Variable und Einkommen und Schulden als Antwortvariablen durchzuführen, können wir den folgenden Befehl verwenden:
manova income debt = educ

Stata erstellt vier eindeutige Teststatistiken zusammen mit den entsprechenden p-Werten:
Wilks‘ Lambda: F-Statistik = 5,02, P-Wert = 0,0023.
Pillai’s Trace: F-Statistik = 4,07, P-Wert = 0,0071.
Lawley-Hotelling trace: F-Statistik = 5,94, P-Wert = 0,0008.
Roy’s largest root: F-Statistik = 13,10, P-Wert = 0,0002.
Eine ausführliche Erläuterung der Berechnung der einzelnen Teststatistiken finden Sie in diesem Artikel des Penn State Eberly College of Science.
Der p-Wert für jede Teststatistik beträgt weniger als 0,05, sodass die Nullhypothese unabhängig von der verwendeten abgelehnt wird. Dies bedeutet, dass wir genügend Beweise dafür haben, dass das Bildungsniveau zu statistisch signifikanten Unterschieden beim Jahreseinkommen und der Gesamtverschuldung der Studenten führt.
Hinweis zu p-Werten: Der Buchstabe neben dem p-Wert in der Ausgabetabelle gibt an, wie die F-Statistik berechnet wurde (e = genaue Berechnung, a = ungefähre Berechnung, u = Obergrenze).
Eine einfaktorielle ANOVA wird verwendet, um zu bestimmen, ob es einen statistisch signifikanten Unterschied zwischen den Mittelwerten von drei oder mehr unabhängigen Gruppen gibt oder nicht.
Das folgende Beispiel bietet …
Eine geschachtelte ANOVA ist eine Art ANOVA („Varianzanalyse“), bei der mindestens ein Faktor in einem anderen Faktor verschachtelt ist.
Nehmen wir zum Beispiel an, ein Forscher möchte wissen, ob drei …