
Ein Log-Log-Diagramm ist ein Diagramm, das sowohl auf der x-Achse als auch auf der y-Achse logarithmische Skalen verwendet.
Diese Art von Diagramm ist nützlich, um zwei Variablen zu visualisieren, wenn …
In diesem Tutorial wird erklärt, wann und wie die Jitterfunktion in R für Streudiagramme verwendet wird.
Streudiagramme eignen sich hervorragend zur Visualisierung der Beziehung zwischen zwei kontinuierlichen Variablen. Das folgende Streudiagramm hilft uns beispielsweise dabei, die Beziehung zwischen Größe und Gewicht für 100 Athleten zu visualisieren:
#Vektoren für Höhe und Gewichte definieren
weights <- runif(100, 160, 240) #100 numbers randomly distributed between 160 and 240
heights <- (weights/3) + rnorm(100) #each weight divided by 3, plus some random noise
#Dataframe mit Höhen und Gewichten erstellen
data <- as.data.frame(cbind(weights, heights))
# Die ersten sechs Zeilen des Dataframes anzeigen
head(data)
# weights heights
#1 170.8859 57.20745
#2 183.2481 62.01162
#3 235.6884 77.93126
#4 231.9864 77.12520
#5 200.8562 67.93486
#6 169.6987 57.54977
#create scatterplot of heights vs weights
plot(data$weights, data$heights, pch = 16, col = 'steelblue')
#Streudiagramm für Höhe & Gewicht erstellen
plot(data$weights, data$heights, pch = 16, col = 'steelblue')
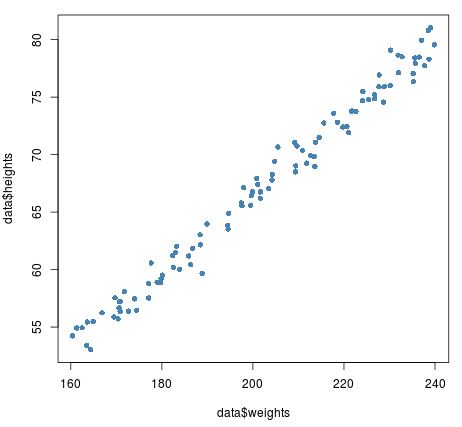
In einigen Fällen möchten wir jedoch möglicherweise die Beziehung zwischen einer kontinuierlichen Variablen und einer anderen Variablen visualisieren, die fast kontinuierlich ist.
Angenommen, wir haben den folgenden Datensatz, der die Anzahl der Spiele, die ein Basketballspieler in den ersten 10 Spielen einer Saison gestartet hat, sowie die durchschnittlichen Punkte pro Spiel anzeigt:
#Dataframe erstellen
games_started <- sample(1:10, 300, TRUE)
points_per_game <- 3*games_started + rnorm(300)
data <- as.data.frame(cbind(games_started, points_per_game))
# Die ersten sechs Zeilen des Dataframes anzeigen
head(data)
# games_started points_per_game
#1 9 25.831554
#2 9 26.673983
#3 10 29.850948
#4 4 12.024353
#5 4 11.534192
#6 1 4.383127
Punkte pro Spiel sind eine kontinuierliche Variable, aber gestartete Spiele sind eine diskrete Variable. Wenn wir versuchen, ein Streudiagramm dieser beiden Variablen zu erstellen, sieht es folgendermaßen aus:
#Streudiagramm der gestarteten Spiele gegen durchschnittliche Punkte pro Spiel erstellen
plot(data$games_started, data$points_per_game, pch = 16, col = 'steelblue')
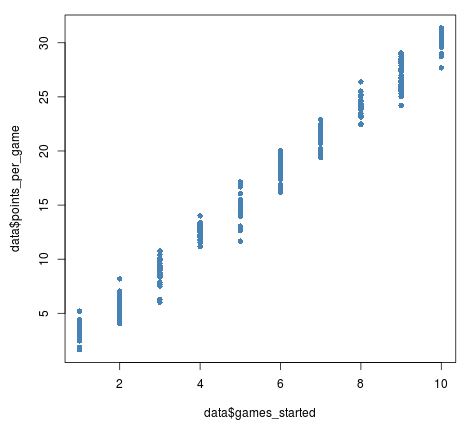
Anhand dieses Streudiagramms können wir erkennen, dass die Spiele begonnen haben und die durchschnittlichen Punkte pro Spiel eine positive Beziehung haben, aber es ist etwas schwierig, die einzelnen Punkte im Plot zu erkennen, da sich so viele von ihnen überlappen.
Mit der Jitter-Funktion können wir den gestarteten Spielen auf der x-Achse ein wenig „Rauschen“ hinzufügen, damit wir die einzelnen Punkte auf dem Plot klarer sehen können:
#Jitter zu "games_started" hinzufügen
plot(jitter(data$games_started), data$points_per_game, pch = 16, col = 'steelblue')

Wir können Jitter optional mit einem numerischen Argument versehen, um den Daten noch mehr Rauschen zu verleihen:
#Jitter zu "games_started" hinzufügen
plot(jitter(data$games_started, 2), data$points_per_game, pch = 16, col = 'steelblue')
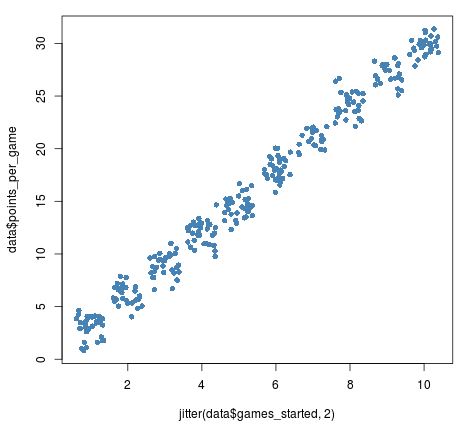
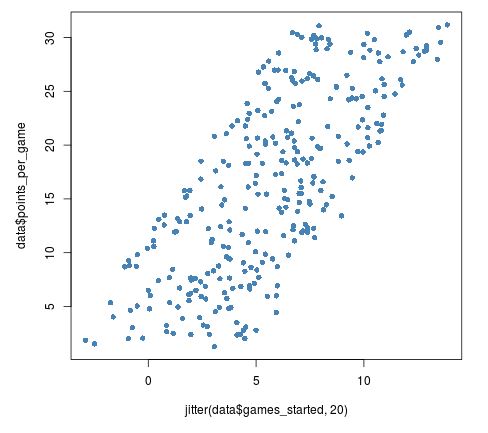
Wir sollten jedoch darauf achten, nicht zu viel Jitter hinzuzufügen, da dies die Originaldaten zu stark verzerren kann:
plot(jitter(data$games_started, 20), data$points_per_game, pch = 16, col = 'steelblue')
Jittering ist besonders nützlich, wenn eine der Ebenen der diskreten Variablen weit mehr Werte aufweist als die anderen Ebenen.
Im folgenden Datensatz gibt es beispielsweise dreihundert Basketballspieler, die zwei der ersten fünf Spiele der Saison gestartet haben, aber nur einhundert Spieler, die 1, 3, 4 oder 5 Spiele gestartet haben:
games_started <- sample(1:5, 100, TRUE)
points_per_game <- 3*games_started + rnorm(100)
data <- as.data.frame(cbind(games_started, points_per_game))
games_twos <- rep(2, 200)
points_twos <- 3*games_twos + rnorm(200)
data_twos <- as.data.frame(cbind(games_twos, points_twos))
names(data_twos) <- c('games_started', 'points_per_game')
all_data <- rbind(data, data_twos)
Wenn wir uns die Anzahl der gespielten Spiele im Vergleich zu den durchschnittlichen Punkten pro Spiel vorstellen, können wir feststellen, dass es mehr Spieler gibt, die 2 Spiele gespielt haben, aber es ist schwer genau zu sagen, wie viele 2 Spiele gespielt haben:
plot(all_data$games_started, all_data$points_per_game, pch = 16, col = 'steelblue')
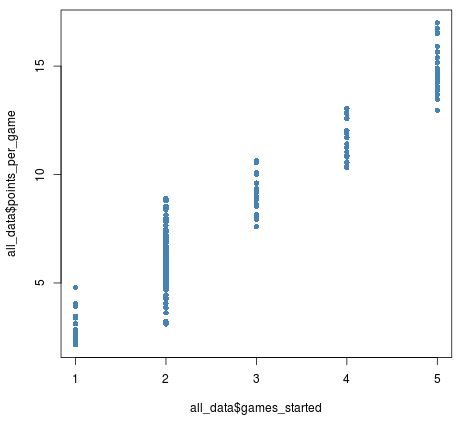
Sobald wir der Variablen games_started Jitter hinzufügen, können wir sehen, wie viele weitere Spieler es gibt, die 2 Spiele gestartet haben:
plot(jitter(all_data$games_started), all_data$points_per_game,
pch = 16, col = 'steelblue')
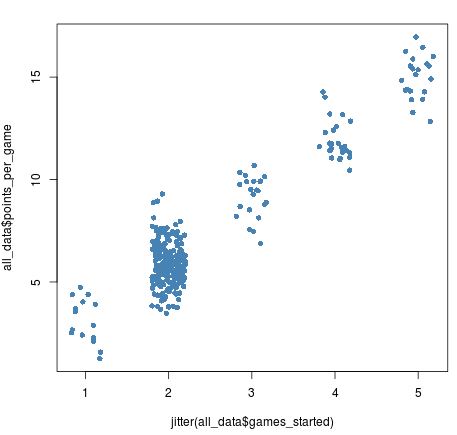
Wenn Sie die Menge an Jitter ein wenig erhöhen, wird dieser Unterschied noch deutlicher:
plot(jitter(all_data$games_started, 1.5), all_data$points_per_game,
pch = 16, col = 'steelblue')
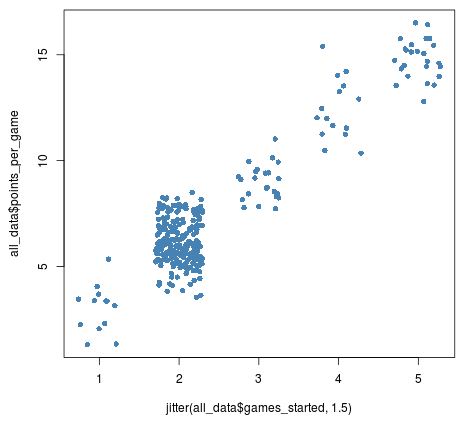
Wie bereits erwähnt, fügt Jittering Daten zufälliges Rauschen hinzu, was von Vorteil sein kann, wenn wir Daten in einem Streudiagramm visualisieren möchten. Mit der Jitter-Funktion können wir ein besseres Bild der tatsächlichen zugrunde liegenden Beziehung zwischen zwei Variablen in einem Datensatz erhalten.
Wenn Sie jedoch eine statistische Analyse wie die Regression verwenden, ist es nicht sinnvoll, Variablen in einem Datensatz zufälliges Rauschen hinzuzufügen, da dies die Ergebnisse einer Analyse beeinflussen würde. Jitter soll daher nur zur Datenvisualisierung verwendet werden, nicht zur Datenanalyse.
Ein Log-Log-Diagramm ist ein Diagramm, das sowohl auf der x-Achse als auch auf der y-Achse logarithmische Skalen verwendet.
Diese Art von Diagramm ist nützlich, um zwei Variablen zu visualisieren, wenn …
Bei der Verwendung von Klassifizierungsmodellen beim maschinellen Lernen verwenden wir häufig zwei Metriken, um die Qualität des Modells zu bewerten, nämlich Präzision und Erinnerung.
Precision: Korrigieren Sie positive Vorhersagen im …