
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Eine der Hauptannahmen der linearen Regression ist, dass die Residuen normal verteilt sind.
Eine Möglichkeit, diese Annahme visuell zu überprüfen, besteht darin, ein Histogramm der Residuen zu erstellen und zu beobachten, ob die Verteilung einer „Glockenform“ folgt, die an die Normalverteilung erinnert.
Dieses Tutorial enthält ein schrittweises Beispiel für die Erstellung eines Histogramms von Residuen für ein Regressionsmodell in R
Lassen Sie uns zunächst einige synthetische Daten erstellen, mit denen Sie arbeiten können:
#Machen Sie dieses Beispiel reproduzierbar
set.seed(0)
#Daten erstellen
x1 <- rnorm(n=100, 2, 1)
x2 <- rnorm(100, 4, 3)
y <- rnorm(100, 2, 3)
data <- data.frame(x1, x2, y)
# Die ersten sechs Zeilen anzeigen
head(data)
x1 x2 y
1 3.262954 6.3455776 -1.1371530
2 1.673767 1.6696701 -0.6886338
3 3.329799 2.1520303 5.8081615
4 3.272429 4.1397409 3.7815228
5 2.414641 0.6088427 4.3269030
6 0.460050 5.7301563 6.6721111
Als nächstes passen wir ein multiples lineares Regressionsmodell an die Daten an:
#mehrere lineare Regressionsmodelle anpassen
model <- lm(y ~ x1 + x2, data=data)
Zuletzt verwenden wir das ggplot-Visualisierungspaket, um ein Histogramm der Residuen aus dem Modell zu erstellen:
#ggplot2 laden
library(ggplot2)
#Histogramm der Residuen erstellen
ggplot(data = data, aes(x = model$residuals)) +
geom_histogram(fill = 'steelblue', color = 'black') +
labs(title = 'Histogram of Residuals', x = 'Residuals', y = 'Frequency')

Beachten Sie, dass wir mithilfe des bin-Arguments auch die Anzahl der Bins angeben können, in die die Residuen eingefügt werden sollen.
Je weniger Bins vorhanden sind, desto breiter sind die Balken im Histogramm. Zum Beispiel könnten wir 20 Bins angeben:
# Histogramm der Residuen erstellen
ggplot(data = data, aes(x = model$residuals)) +
geom_histogram(bins = 20, fill = 'steelblue', color = 'black') +
labs(title = 'Histogram of Residuals', x = 'Residuals', y = 'Frequency')
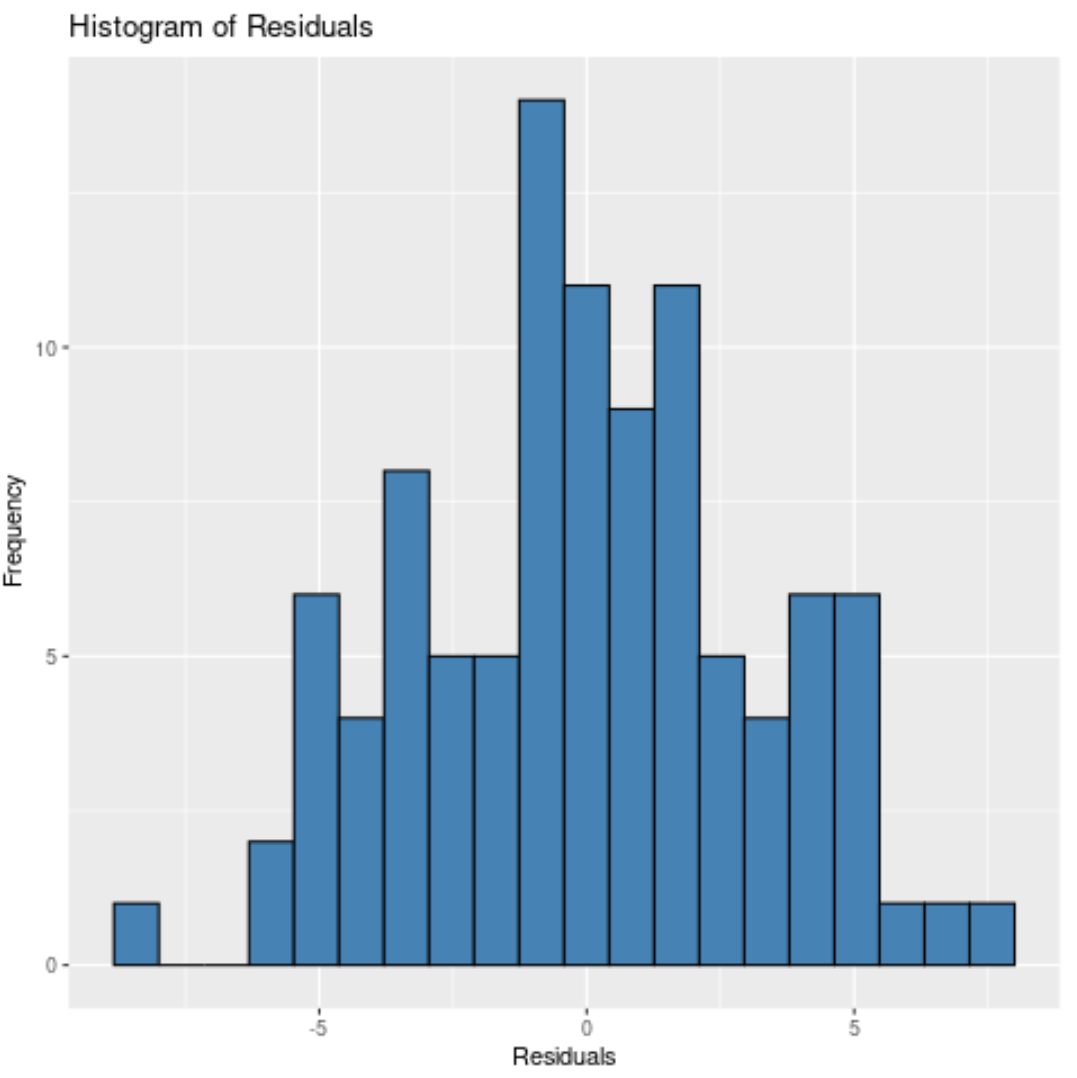
Oder wir könnten 10 Bins angeben:
#Histogramm der Residuen erstellen
ggplot(data = data, aes(x = model$residuals)) +
geom_histogram(bins = 10, fill = 'steelblue', color = 'black') +
labs(title = 'Histogram of Residuals', x = 'Residuals', y = 'Frequency')
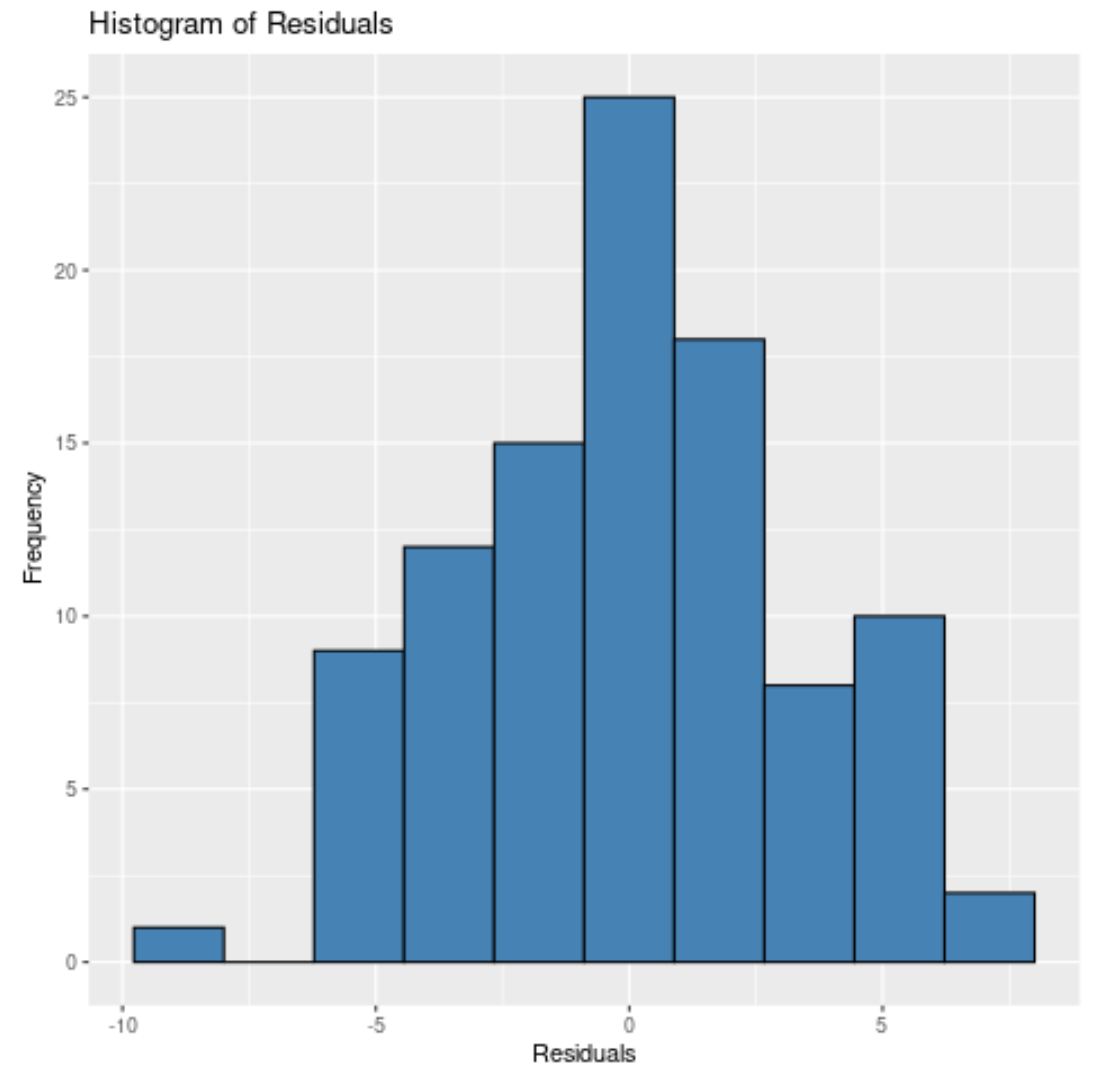
Unabhängig davon, wie viele Bins wir angeben, können wir sehen, dass die Residuen ungefähr normal verteilt sind.
Wir könnten auch einen formalen statistischen Test wie Shapiro-Wilk, Kolmogorov-Smirnov oder Jarque-Bera durchführen, um die Normalität zu testen.
Beachten Sie jedoch, dass diese Tests empfindlich auf große Stichproben reagieren - das heißt, sie schließen häufig, dass die Residuen bei großen Stichproben nicht normal sind.
Aus diesem Grund ist es oft einfacher, die Normalität zu beurteilen, indem ein Histogramm der Residuen erstellt wird.
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …