
In der Statistik wird die Gamma-Verteilung häufig verwendet, um Wahrscheinlichkeiten in Bezug auf Wartezeiten zu modellieren.
Die folgenden Beispiele zeigen, wie Sie die Funktion scipy.stats.gamma() verwenden, um eine …
Die Student t-Verteilung ist eine der am häufigsten verwendeten Verteilungen in der Statistik. In diesem Tutorial wird erklärt, wie Sie mit der Student t-Verteilung in R mithilfe der Funktionen dt(), qt(), pt() und rt() arbeiten.
Die Funktion dt gibt den Wert der Wahrscheinlichkeitsdichtefunktion (PDF) der Student t-Verteilung bei einer bestimmten Zufallsvariablen x und Freiheitsgraden df zurück. Die Syntax für die Verwendung von dt lautet wie folgt:
dt(x, df)
Der folgende Code zeigt einige Beispiele für dt in Aktion:
#Finden Sie den Wert der Student t-Verteilung PDF bei x = 0 mit 20 Freiheitsgraden
dt(x = 0, df = 20)
# [1] 0,3939886
# Standardmäßig geht R davon aus, dass das erste Argument x und das zweite Argument df ist
dt(0, 20)
# [1] 0,3939886
#Finden Sie den Wert der Student t-Verteilung pdf bei x = 1 mit 30 Freiheitsgraden
dt(1, 30)
# [1] 0,2379933
Wenn Sie versuchen, Fragen zur Wahrscheinlichkeit mithilfe der Student t-Verteilung zu lösen, verwenden Sie normalerweise pt anstelle von dt. Eine nützliche Anwendung von dt ist jedoch das Erstellen eines Student t-Verteilungsdiagramms in R Der folgende Code veranschaulicht, wie dies getan wird:
#Erstellen Sie eine Folge von 100 gleich beabstandeten Zahlen zwischen -4 und 4
x <- seq(-4, 4, length=100)
#Erstellen Sie einen Wertevektor, der die Höhe der Wahrscheinlichkeitsverteilung anzeigt
#für jeden Wert in x mit 20 Freiheitsgraden
y <- dt(x = x, df = 20)
#Plotte x und y als Streudiagramm mit verbundenen Linien (Typ = "l") und füge
# eine x-Achse mit benutzerdefinierten Beschriftungen hinzu
plot(x,y, type = "l", lwd = 2, axes = FALSE, xlab = "", ylab = "")
axis(1, at = -3:3, labels = c("-3s", "-2s", "-1s", "mean", "1s", "2s", "3s"))
Dies erzeugt das folgende Diagramm:

Die Funktion pt gibt den Wert der kumulativen Dichtefunktion (cdf) der Student t-Verteilung bei einer bestimmten Zufallsvariablen x und Freiheitsgraden df zurück. Die Syntax für die Verwendung von pnorm lautet wie folgt:
pt(x, df)
Einfach ausgedrückt, gibt pt den Bereich links von einem bestimmten Wert x in der Student t-Verteilung zurück. Wenn Sie sich für den Bereich rechts von einem bestimmten Wert x interessieren, können Sie einfach das Argument lower.tail = FALSE hinzufügen
pt(x, df, lower.tail = FALSE)
Das folgende Beispiel zeigt, wie einige Wahrscheinlichkeitsfragen mit pt gelöst werden.
Beispiel 1: Suchen Sie den Bereich links von einer t-Statistik mit einem Wert von -0,785 und 14 Freiheitsgraden.
pt(-0,785, 14)
# [1] 0,2227675
Beispiel 2: Finden Sie den Bereich rechts von einer t-Statistik mit einem Wert von -0,785 und 14 Freiheitsgraden.
#Die folgenden Ansätze führen zu gleichwertigen Ergebnissen
# 1 - Bereich links
1 - pt(-0.785, 14)
# [1] 0,7772325
#Bereich rechts
pt(-0,785, 14, lower.tail = FALSE)
# [1] 0,7772325
Beispiel 3: Ermitteln Sie die Gesamtfläche in einer Student t-Verteilung mit 14 Freiheitsgraden, die links von -0,785 oder rechts von 0,785 liegt.
pt(-0.785, 14) + pt(0.785, 14, lower.tail = FALSE)
# [1] 0,4455351
Die Funktion qt gibt den Wert der inversen kumulativen Dichtefunktion (CDF) der Student t-Verteilung bei einer bestimmten Zufallsvariablen x und Freiheitsgraden df zurück. Die Syntax für die Verwendung von qt lautet wie folgt:
qt(x, df)
Einfach ausgedrückt, können Sie qt verwenden, um herauszufinden, wie hoch der t-Score des p-ten Quantils der Student t-Verteilung ist.
Der folgende Code zeigt einige Beispiele für qt in Aktion:
#Finden Sie den t-Score des 99. Quantils der Student t-Verteilung mit df = 20
qt(.99, df = 20)
# [1] [1] 2.527977
#Finden Sie den t-Score des 95. Quantils der Student t-Verteilung mit df = 20
qt(.95, df = 20)
# [1] 1.724718
#Finden Sie den t-Score des 90. Quantils der Student t-Verteilung mit df = 20
qt(.9, df = 20)
# [1] 1.325341
Beachten Sie, dass die von qt gefundenen kritischen Werte mit den in der t-Verteilungstabelle gefundenen kritischen Werten sowie den kritischen Werten übereinstimmen.
Die Funktion rt erzeugt einen Vektor von Zufallsvariablen, die einer Student t-Verteilung folgen, wenn eine Vektorlänge n und Freiheitsgrade df gegeben sind. Die Syntax für die Verwendung von rt lautet wie folgt:
rt(n, df)
Der folgende Code zeigt einige Beispiele für rt in Aktion:
#Generieren Sie einen Vektor mit 5 Zufallsvariablen, die einer Student t-Verteilung folgen
#mit df = 20
rt(n = 5, df = 20)
# [1] -1,7422445 0,9560782 0,6635823 1,2122289 -0,7052825
#generieren Sie einen Vektor mit 1000 Zufallsvariablen, die einer Student t-Verteilung folgen mit df = 40
narrowDistribution <- rt(1000, 40)
#Generieren Sie einen Vektor mit 1000 Zufallsvariablen, die einer Student t-Verteilung folgen mit df = 5
wideDistribution <- rt(1000, 5)
#Generieren Sie zwei Histogramme, um diese beiden Verteilungen nebeneinander anzuzeigen, und geben Sie 50 Balken im Histogramm an
par(mfrow=c(1, 2)) #eine Zeile, zwei Spalten
hist(narrowDistribution, breaks=50, xlim = c(-6, 4))
hist(wideDistribution, breaks=50, xlim = c(-6, 4))
Dies erzeugt die folgenden Histogramme:
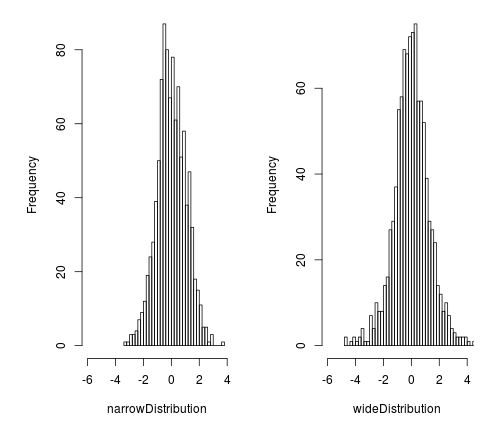
Beachten Sie, dass die weite Verteilung im Vergleich zur engen Verteilung stärker verteilt ist. Dies liegt daran, dass wir die Freiheitsgrade in der breiten Verteilung mit 5 gegenüber 40 in der engen Verteilung angegeben haben. Je weniger Freiheitsgrade vorhanden sind, desto breiter wird die Verteilung der Schüler sein.
Weiterführende Literatur:
Ein Leitfaden zu dbinom, pbinom, qbinom und rbinom in R
In der Statistik wird die Gamma-Verteilung häufig verwendet, um Wahrscheinlichkeiten in Bezug auf Wartezeiten zu modellieren.
Die folgenden Beispiele zeigen, wie Sie die Funktion scipy.stats.gamma() verwenden, um eine …
Eine Gleichverteilung ist eine Wahrscheinlichkeitsverteilung, bei der jeder Wert zwischen einem Intervall von a bis b mit gleicher Wahrscheinlichkeit gewählt wird.
Die Wahrscheinlichkeit, dass wir auf einem Intervall von a …