
Der einfachste Weg, Arrays in Python zu verketten, ist die Verwendung der Funktion numpy.concatenate, die die folgende Syntax verwendet:
numpy.concatenate((a1, a2, ….), axis = 0)
wo:
- a1, a2 …: Die …
Bei vielen statistischen Tests wird davon ausgegangen, dass die Residuen einer Antwortvariablen normal verteilt sind.
Oft sind die Residuen jedoch nicht normal verteilt. Eine Möglichkeit, dieses Problem zu beheben, besteht darin, die Antwortvariable mithilfe einer der drei Transformationen zu transformieren:
1. Log-transformation: Transformieren Sie die Antwortvariable von y nach log(y).
2. Quadratwurzel-Transformation: Transformieren Sie die Antwortvariable von y nach √y.
3. Kubikwurzel-Transformation: Transformieren Sie die Antwortvariable von y nach y1/3.
Durch Ausführen dieser Transformationen nähert sich die Antwortvariable typischerweise der Normalverteilung an. Die folgenden Beispiele zeigen, wie diese Transformationen in R durchgeführt werden.
Der folgende Code zeigt, wie eine Log-transformation für eine Antwortvariable durchgeführt wird:
#Dataframe erstellen
df <- data.frame(y=c(1, 1, 1, 2, 2, 2, 2, 2, 2, 3, 3, 3, 6, 7, 8),
x1=c(7, 7, 8, 3, 2, 4, 4, 6, 6, 7, 5, 3, 3, 5, 8),
x2=c(3, 3, 6, 6, 8, 9, 9, 8, 8, 7, 4, 3, 3, 2, 7))
#Log-transformation durchführen
log_y <- log10(df$y)
Der folgende Code zeigt, wie Histogramme erstellt werden, um die Verteilung von y vor und nach einer Log-transformation anzuzeigen:
#Histogramm für die ursprüngliche Verteilung erstellen
hist(df$y, col='steelblue', main='Original')
#Histogramm für logarithmisch transformierte Verteilung erstellen
hist(log_y, col='coral2', main='Log Transformed')
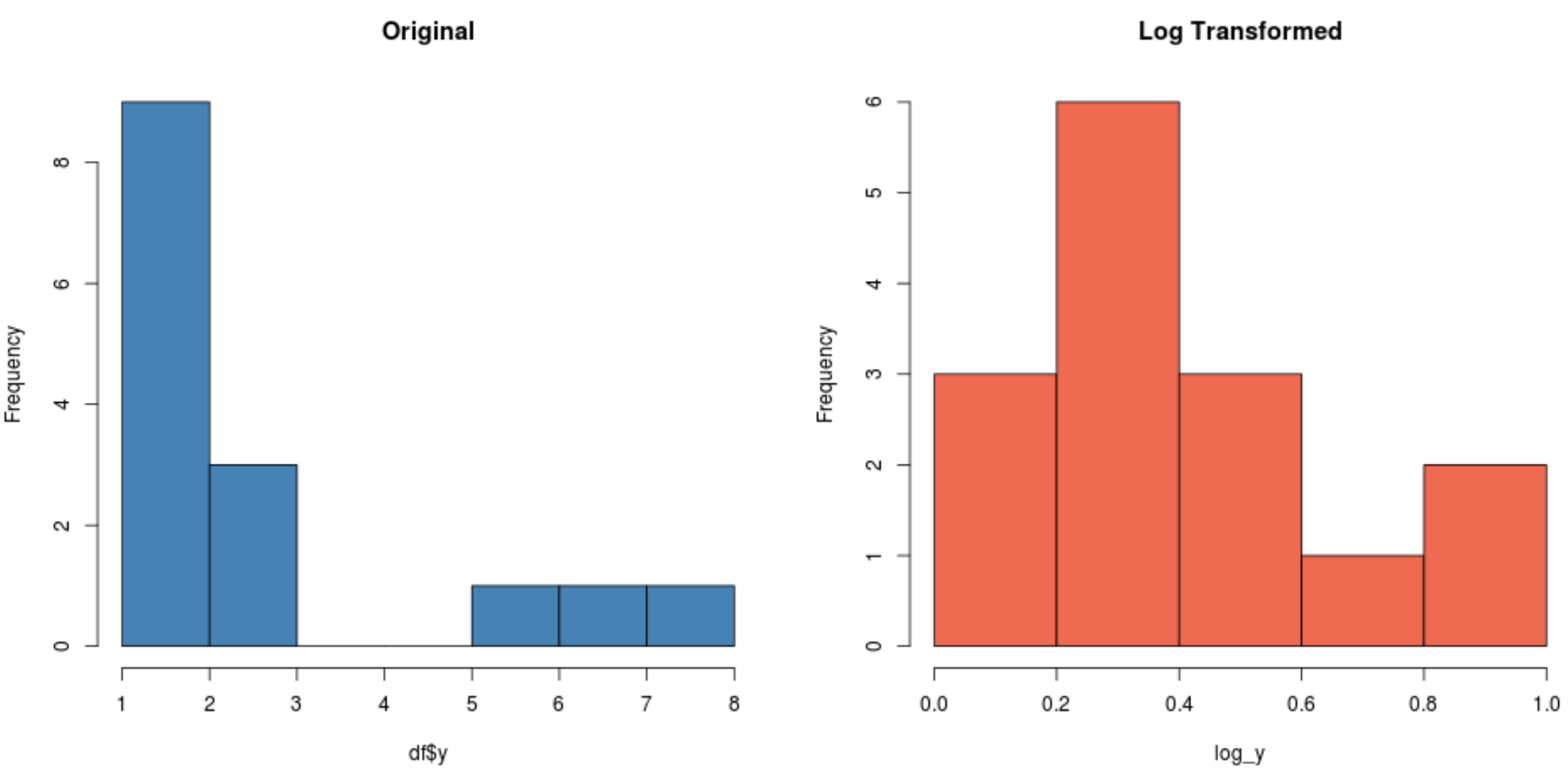
Beachten Sie, dass die logarithmisch transformierte Verteilung im Vergleich zur ursprünglichen Verteilung viel normaler ist. Es ist immer noch keine perfekte „Glockenform“, aber es ist näher an einer Normalverteilung als die ursprüngliche Verteilung.
Wenn wir für jede Verteilung einen Shapiro-Wilk-Test durchführen, werden wir feststellen, dass die ursprüngliche Verteilung die Normalitätsannahme nicht erfüllt, während die logarithmisch transformierte Verteilung dies nicht tut (bei α = 0,05):
#Shapiro-Wilk-Test an Originaldaten durchführen
shapiro.test(df$y)
Shapiro-Wilk normality test
data: df$y
W = 0.77225, p-value = 0.001655
#Shapiro-Wilk-Test für logarithmisch transformierte Daten durchführen
shapiro.test(log_y)
Shapiro-Wilk normality test
data: log_y
W = 0.89089, p-value = 0.06917
Der folgende Code zeigt, wie eine Quadratwurzeltransformation für eine Antwortvariable durchgeführt wird:
#Dataframe erstellen
df <- data.frame(y=c(1, 1, 1, 2, 2, 2, 2, 2, 2, 3, 3, 3, 6, 7, 8),
x1=c(7, 7, 8, 3, 2, 4, 4, 6, 6, 7, 5, 3, 3, 5, 8),
x2=c(3, 3, 6, 6, 8, 9, 9, 8, 8, 7, 4, 3, 3, 2, 7))
#Quadratwurzeltransformation durchführen
sqrt_y <- sqrt(df$y)
Der folgende Code zeigt, wie Histogramme erstellt werden, um die Verteilung von y vor und nach einer Quadratwurzeltransformation anzuzeigen:
#Histogramm für die ursprüngliche Verteilung erstellen
hist(df$y, col='steelblue', main='Original')
#Histogramm für Quadratwurzel-transformierte Verteilung erstellen
hist(sqrt_y, col='coral2', main='Square Root Transformed')
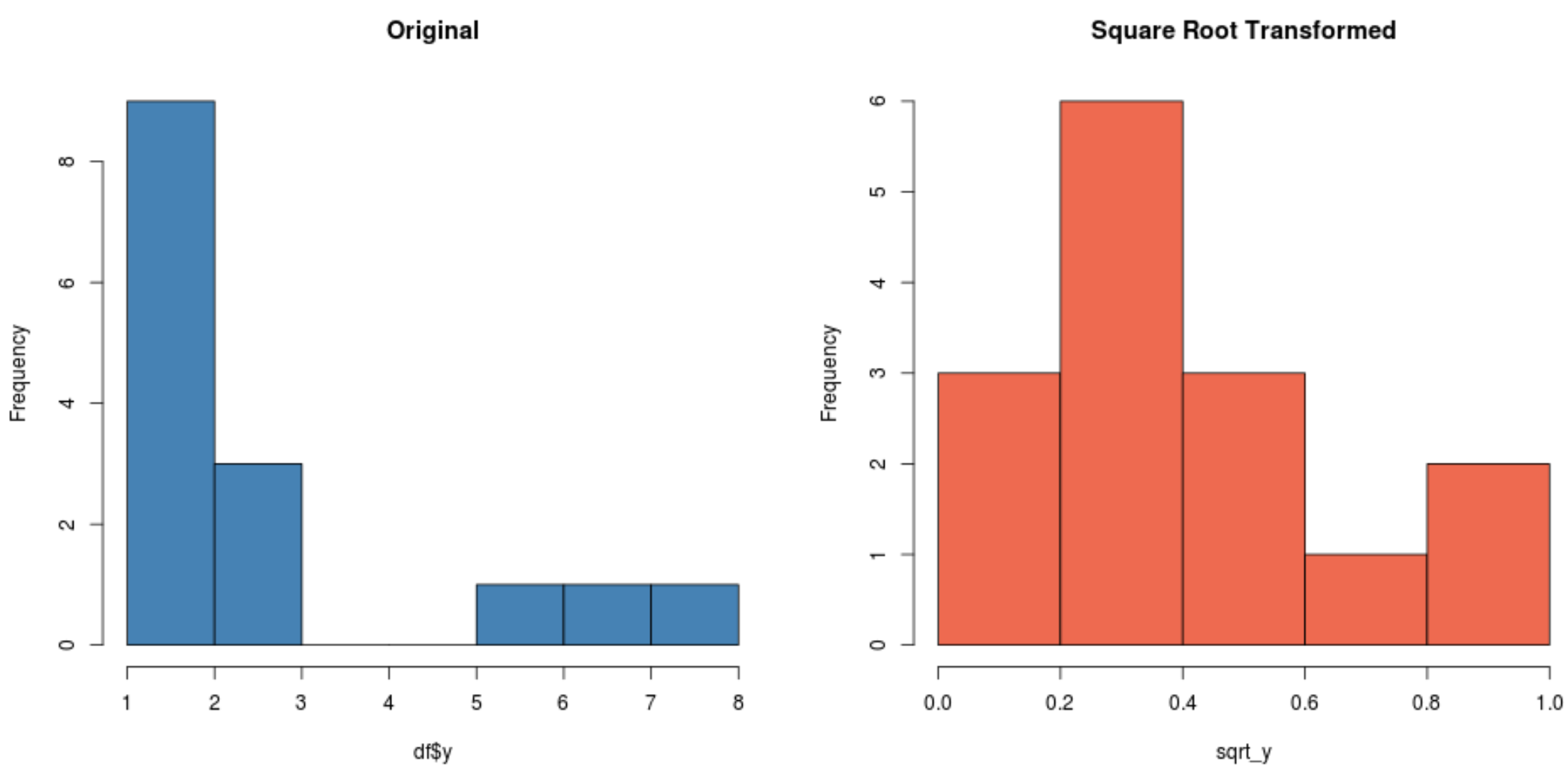
Beachten Sie, dass die durch Quadratwurzel transformierte Verteilung im Vergleich zur ursprünglichen Verteilung viel normaler verteilt ist.
Der folgende Code zeigt, wie eine Kubikwurzelumwandlung für eine Antwortvariable durchgeführt wird:
#Dataframe erstellen
df <- data.frame(y=c(1, 1, 1, 2, 2, 2, 2, 2, 2, 3, 3, 3, 6, 7, 8),
x1=c(7, 7, 8, 3, 2, 4, 4, 6, 6, 7, 5, 3, 3, 5, 8),
x2=c(3, 3, 6, 6, 8, 9, 9, 8, 8, 7, 4, 3, 3, 2, 7))
#Quadratwurzeltransformation durchführen
cube_y <- df$y^(1/3)
Der folgende Code zeigt, wie Histogramme erstellt werden, um die Verteilung von y vor und nach einer Quadratwurzeltransformation anzuzeigen:
#Histogramm für die ursprüngliche Verteilung erstellen
hist(df$y, col='steelblue', main='Original')
#Histogramm für Quadratwurzel-transformierte Verteilung erstellen
hist(cube_y, col='coral2', main='Cube Root Transformed')
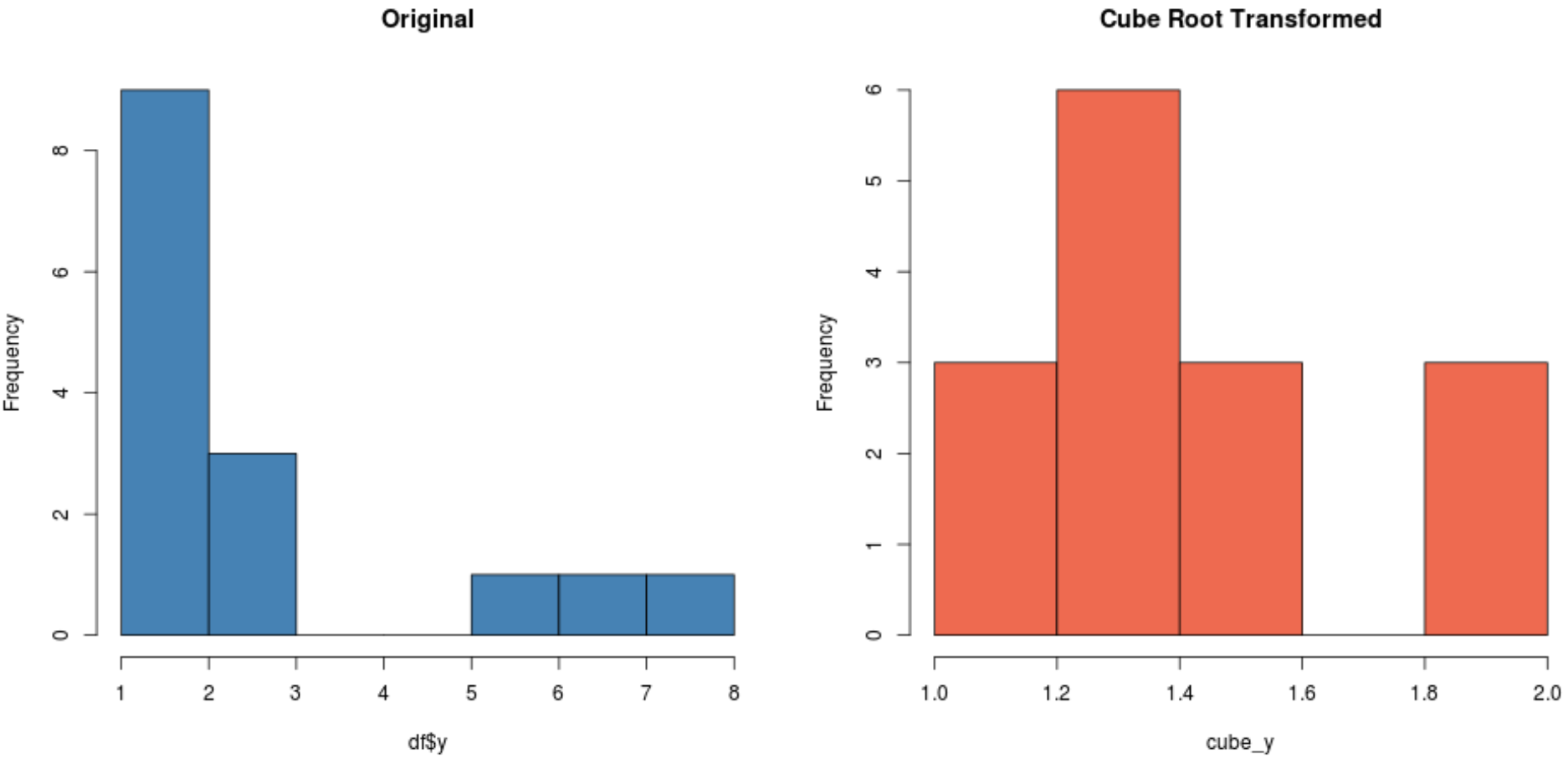
Abhängig von Ihrem Dataset kann eine dieser Transformationen zu einem neuen Dataset führen, das normaler verteilt ist als die anderen.
Der einfachste Weg, Arrays in Python zu verketten, ist die Verwendung der Funktion numpy.concatenate, die die folgende Syntax verwendet:
numpy.concatenate((a1, a2, ….), axis = 0)
wo:
Häufig möchten Sie möglicherweise nur die Anzahl der Zeilen in einem pandas-DataFrame zählen, die bestimmte Kriterien erfüllen.
Glücklicherweise ist dies mit der folgenden grundlegenden Syntax einfach zu bewerkstelligen:
sum(df …