
Ein Mann-Kendall-Trendtest wird verwendet, um festzustellen, ob in Zeitreihendaten ein Trend vorhanden ist oder nicht. Es ist ein nichtparametrischer Test, was bedeutet, dass keine zugrunde liegende Annahme über die Normalität …
Cook-Abstand, oft mit D i bezeichnet , wird in der Regressionsanalyse verwendet, um einflussreiche Datenpunkte zu identifizieren, die sich negativ auf Ihr Regressionsmodell auswirken können.
Die Formel für Cooks Entfernung lautet:
D i = (r i 2 / p * MSE) * (h ii / (1-h ii ) 2 )
wo:
- r i ist das i-te Residuum
- p ist die Anzahl der Koeffizienten im Regressionsmodell
- MSE ist der mittlere quadratische Fehler
- h ii ist der i-te Hebelwert
Obwohl die Formel etwas kompliziert aussieht, ist die gute Nachricht, dass die meisten statistischen Softwareprogramme dies leicht für Sie berechnen können.
Im Wesentlichen bewirkt der Cook-Abstand eines: Er misst, um wie viel sich alle angepassten Werte im Modell ändern, wenn der i-te Datenpunkt gelöscht wird.
Ein Datenpunkt mit einem großen Wert für den Cook-Abstand zeigt an, dass er die angepassten Werte stark beeinflusst. Eine allgemeine Faustregel lautet, dass jeder Punkt mit einem Cook-Asbtand von mehr als 4 / n ( wobei n die Gesamtzahl der Datenpunkte ist ) als Ausreißer betrachtet wird.
Es ist wichtig zu beachten, dass der Cook-Abstand häufig verwendet wird, um einflussreiche Datenpunkte zu identifizieren. Nur weil ein Datenpunkt Einfluss hat, heißt das nicht, dass er unbedingt gelöscht werden muss. Überprüfen Sie zunächst, ob der Datenpunkt einfach falsch aufgezeichnet wurde oder ob der Datenpunkt etwas Seltsames enthält, das auf einen interessanten Befund hinweisen kann.
So berechnen Sie den Cook-Abstand in R
Das folgende Beispiel zeigt, wie der Cook-Abstand in R berechnet wird.
Zuerst laden wir zwei Bibliotheken, die wir für dieses Beispiel benötigen:
library(ggplot2)
library(gridExtra)
Als nächstes definieren wir zwei Dataframes: einen mit zwei Ausreißern und einen ohne Ausreißer.
#Dataframe ohne Ausreißer erstellen
no_outliers <- data.frame(x = c(1, 2, 2, 3, 4, 5, 7, 3, 2, 12, 11, 15, 14, 17, 22),
y = c(22, 23, 24, 23, 19, 34, 35, 36, 36, 34, 32, 38, 41,
42, 44))
#Dataframe mit zwei Ausreißern erstellen
outliers <- data.frame(x = c(1, 2, 2, 3, 4, 5, 7, 3, 2, 12, 11, 15, 14, 17, 22),
y = c(190, 23, 24, 23, 19, 34, 35, 36, 36, 34, 32, 38, 41,
42, 180))
Als Nächstes erstellen wir ein Streudiagramm, um die beiden Dataframes nebeneinander anzuzeigen:
#Streudiagramm für Dataframe ohne Ausreißer erstellen
no_outliers_plot <- ggplot(data = no_outliers, aes(x = x, y = y)) +
geom_point() +
geom_smooth(method = lm) +
ylim(0, 200) +
ggtitle("No Outliers")
#Streudiagramm für Dataframe mit Ausreißern erstellen
outliers_plot <- ggplot(data = outliers, aes(x = x, y = y)) +
geom_point() +
geom_smooth(method = lm) +
ylim(0, 200) +
ggtitle("With Outliers")
#Zeichnen Sie die beiden Streudiagramme nebeneinander
gridExtra::grid.arrange(no_outliers_plot, outliers_plot, ncol=2)

Wir können sehen, wie Ausreißer die Anpassung der Regressionslinie im zweiten Diagramm negativ beeinflussen.
Um Einflusspunkte im zweiten Datensatz zu identifizieren, können wir die Cook-Entfernung für jede Beobachtung im Datensatz berechnen und diese Entfernungen dann grafisch darstellen, um festzustellen, welche Beobachtungen größer als der herkömmliche Schwellenwert von 4 / n sind:
#Passen Sie das lineare Regressionsmodell mit Ausreißern an den Datensatz an
model <- lm(y ~ x, data = outliers)
#Finden Sie Cook-Abstand für jede Beobachtung im Datensatz
cooksD <- cooks.distance(model)
# Zeichnen Sie die Entfernung des Kochs mit einer horizontalen Linie bei 4 / n, um zu sehen, welche Beobachtungen diese Grenze überschreiten
n <- nrow(outliers)
plot(cooksD, main = "Cooks Distance for Influential Obs")
abline(h = 4/n, lty = 2, col = "steelblue") #Trennlinie hinzufügen
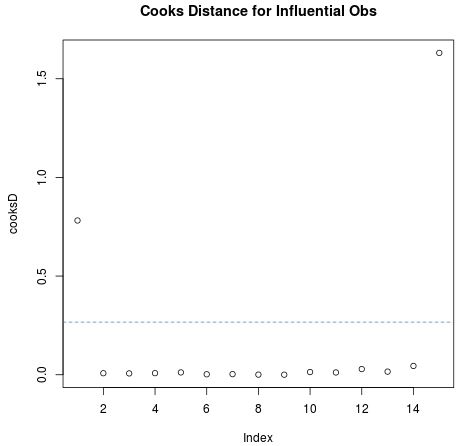
Wir können deutlich sehen, dass die erste und letzte Beobachtung im Datensatz den 4 / n-Schwellenwert überschreiten. Daher würden wir diese beiden Beobachtungen als einflussreiche Datenpunkte identifizieren, die sich negativ auf das Regressionsmodell auswirken.
Wenn wir Beobachtungen entfernen möchten, die den 4 / n-Schwellenwert überschreiten, können wir dies mit dem folgenden Code tun:
#Einflusspunkte identifizieren
influential_obs <- as.numeric(names(cooksD)[(cooksD > (4/n))])
#Definieren Sie ein neues Dataframe, bei dem Einflusspunkte entfernt wurden
outliers_removed <- outliers[-influential_obs, ]
Als nächstes können wir zwei Streudiagramme vergleichen: eines zeigt die Regressionslinie mit den vorhandenen Einflusspunkten und das andere zeigt die Regressionslinie mit den entfernten Einflusspunkten:
#Streudiagramm mit vorhandenen Ausreißern erstellen
outliers_present <- ggplot(data = outliers, aes(x = x, y = y)) +
geom_point() +
geom_smooth(method = lm) +
ylim(0, 200) +
ggtitle("Outliers Present")
#Streudiagramm mit entfernten Ausreißern erstellen
outliers_removed <- ggplot(data = outliers_removed, aes(x = x, y = y)) +
geom_point() +
geom_smooth(method = lm) +
ylim(0, 200) +
ggtitle("Outliers Removed")
#plotten Sie beide Streudiagramme nebeneinander
gridExtra::grid.arrange(outliers_present, outliers_removed, ncol = 2)
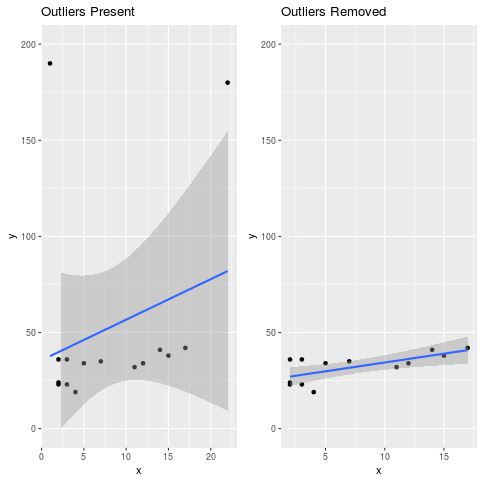
Wir können deutlich sehen, wie viel besser die Regressionslinie zu den Daten passt, wenn die beiden einflussreichen Datenpunkte entfernt wurden.
Technische Hinweise
- Die meisten statistischen Softwareprogramme können den Cook-Abstand für jede Beobachtung in einem Datensatz einfach berechnen.
- Denken Sie daran, dass der Cook-Abstand lediglich eine Möglichkeit ist, einflussreiche Punkte zu identifizieren.
- Es gibt viele Möglichkeiten, mit einflussreichen Punkten umzugehen, einschließlich: Entfernen dieser Punkte, Ersetzen dieser Punkte durch einen Wert wie Mittelwert oder Median oder einfaches Beibehalten der Punkte im Modell, wobei Sie dies bei der Berichterstattung über die Regressionsergebnisse sorgfältig notieren sollten.
Das könnte Sie auch interessieren:
So führen Sie einen Mann-Kendall-Trendtest in Python durch
So führen Sie einen Chow-Test in Python durch
Ein Chow-Test wird verwendet, um zu testen, ob die Koeffizienten in zwei verschiedenen Regressionsmodellen auf verschiedenen Datensätzen gleich sind.
Dieser Test wird typischerweise im Bereich der Ökonometrie mit Zeitreihendaten verwendet …