
Eine einfaktorielle ANOVA wird verwendet, um zu bestimmen, ob es einen statistisch signifikanten Unterschied zwischen den Mittelwerten von drei oder mehr unabhängigen Gruppen gibt oder nicht.
Das folgende Beispiel bietet …
Eine zweifaktorielle ANOVA („Varianzanalyse“) wird verwendet, um zu bestimmen, ob es einen statistisch signifikanten Unterschied zwischen den Mittelwerten von drei oder mehr unabhängigen Gruppen gibt, die auf zwei Faktoren aufgeteilt wurden.
In diesem Tutorial wird erklärt, wie eine zweifaktorielle ANOVA in R durchgeführt wird.
Angenommen, wir möchten feststellen, ob die Trainingsintensität und das Geschlecht den Gewichtsverlust beeinflussen. In diesem Fall sind die beiden Faktoren, die wir untersuchen, Bewegung und Geschlecht, und die Antwortvariable ist Gewichtsverlust, gemessen in Pfund.
Wir können eine zweifaktorielle ANOVA durchführen, um festzustellen, ob Bewegung und Geschlecht den Gewichtsverlust beeinflussen und ob es eine Wechselwirkung zwischen Bewegung und Geschlecht beim Gewichtsverlust gibt.
Wir rekrutieren 30 Männer und 30 Frauen, um an einem Experiment teilzunehmen, bei dem wir jeweils 10 zufällig zuweisen, um einen Monat lang einem Programm ohne Übung, leichte Übung oder intensive Übung zu folgen.
Der folgende Code erstellt das Dataframe, mit dem wir arbeiten werden:
#Machen Sie dieses Beispiel reproduzierbar
set.seed (10)
#Dataframe erstellen
data <- data.frame(gender = rep(c("Male", "Female"), each = 30),
exercise = rep(c("None", "Light", "Intense"), each = 10, times = 2),
weight_loss = c(runif(10, -3, 3), runif(10, 0, 5), runif(10, 5, 9),
runif(10, -4, 2), runif(10, 0, 3), runif(10, 3, 8)))
#Die ersten sechs Zeilen des Dataframes anzeigen
head(data)
# gender exercise weight_loss
#1 Male None 0.04486922
#2 Male None -1.15938896
#3 Male None -0.43855400
#4 Male None 1.15861249
#5 Male None -2.48918419
#6 Male None -1.64738030
# Sehen Sie, wie viele Teilnehmer in jeder Gruppe sind
table(data$gender, data$exercise)
# Intense Light None
# Female 10 10 10
# Male 10 10 10
Bevor wir überhaupt das zweifaktorielle ANOVA-Modell anpassen, können wir die Daten besser verstehen, indem wir den Mittelwert und die Standardabweichung des Gewichtsverlusts für jede der sechs Behandlungsgruppen mithilfe des dplyr Pakets ermitteln:
#dplyr laden
library(dplyr)
# Mittelwert und Standardabweichung des Gewichtsverlusts für jede Behandlungsgruppe ermitteln
data %>%
group_by(gender, exercise) %>%
summarise(mean = mean(weight_loss),
sd = sd(weight_loss))
# A tibble: 6 x 4
# Groups: gender [2]
# gender exercise mean sd
#
#1 Female Intense 5.31 1.02
#2 Female Light 0.920 0.835
#3 Female None -0.501 1.77
#4 Male Intense 7.37 0.928
#5 Male Light 2.13 1.22
#6 Male None -0.698 1.12
Wir können auch ein Boxplot für jede der sechs Behandlungsgruppen erstellen, um die Verteilung des Gewichtsverlusts für jede Gruppe zu visualisieren:
#Setzen Sie die Ränder so, dass die Achsenbeschriftungen im Boxplot nicht abgeschnitten werden
par(mar=c(8, 4.1, 4.1, 2.1))
# Boxplots erstellen
boxplot(weight_loss ~ gender:exercise,
data = data,
main = "Weight Loss Distribution by Group",
xlab = "Group",
ylab = "Weight Loss",
col = "steelblue",
border = "black",
las = 2 #X-Achsenbeschriftungen senkrecht drehen
)
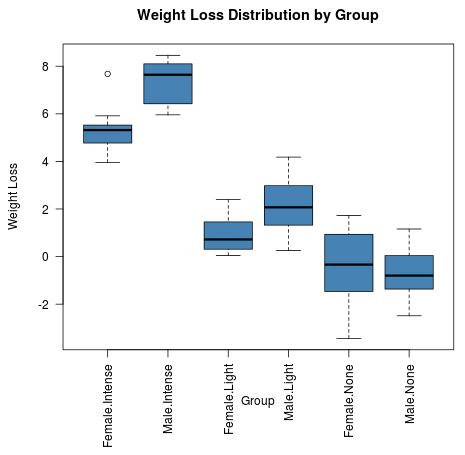
Auf Anhieb können wir sehen, dass die beiden Gruppen, die an intensiven Übungen teilgenommen haben, offenbar größere Gewichtsverlustwerte aufweisen. Wir können auch sehen, dass Männer im Vergleich zu Frauen tendenziell höhere Gewichtsverlustwerte für die intensiven und leichten Übungsgruppen haben.
Als Nächstes passen wir das zweifaktorielle ANOVA-Modell an unsere Daten an, um festzustellen, ob diese visuellen Unterschiede tatsächlich statistisch signifikant sind.
Die allgemeine Syntax für ein zweifaktorielles ANOVA-Modell in R lautet wie folgt:
aov(response variable ~ predictor_variable1 * predictor_variable2, data = dataset)
Beachten Sie, dass das * zwischen den beiden Prädiktorvariablen angibt, dass wir auch einen Interaktionseffekt zwischen den beiden Prädiktorvariablen testen möchten.
In unserem Beispiel können wir den folgenden Code verwenden, um das zweifaktorielle ANOVA-Modell anzupassen, wobei weight_loss als Antwortvariable und gender und exercise als unsere beiden Prädiktorvariablen verwendet werden. Wir können dann die Funktion summary() verwenden, um die Ausgabe unseres Modells anzuzeigen:
#Passen Sie das zweifaktorielle ANOVA-Modell an
model <- aov(weight_loss ~ gender * exercise, data = data)
# Sehen Sie sich die Modellausgabe an
summary(model)
# Df Sum Sq Mean Sq F value Pr(>F)
#gender 1 15.8 15.80 11.197 0.0015 **
#exercise 2 505.6 252.78 179.087 <2e-16 ***
#gender:exercise 2 13.0 6.51 4.615 0.0141 *
#Residuals 54 76.2 1.41
#---
#Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Aus der Modellausgabe können wir ersehen, dass gender, exercise und die Interaktion zwischen den beiden Variablen auf dem .05-Signifikanzniveau statistisch signifikant sind.
Bevor wir weiter gehen, sollten wir überprüfen, ob die Annahmen unseres Modells erfüllt sind, damit unsere Ergebnisse aus dem Modell zuverlässig sind. Insbesondere geht eine zweifaktorielle ANOVA davon aus:
1. Unabhängigkeit – Die Beobachtungen in jeder Gruppe müssen unabhängig voneinander sein. Da wir ein randomisiertes Design verwendet haben, sollte diese Annahme erfüllt sein, damit wir uns darüber keine Sorgen machen müssen.
2. Normalverteilung – Die abhängige Variable sollte für jede Kombination der Gruppen der beiden Faktoren ungefähr normal verteilt sein.
Eine Möglichkeit, diese Annahme zu überprüfen, besteht darin, ein Histogramm der Modellresiduen zu erstellen. Wenn die Residuen grob normalverteilt sind, sollte diese Annahme erfüllt sein.
#Modellresiduen definieren
resid <- model$residuals
# Histogramm der Residuen erstellen
hist(resid, main = "Histogram of Residuals", xlab = "Residuals", col = "steelblue")
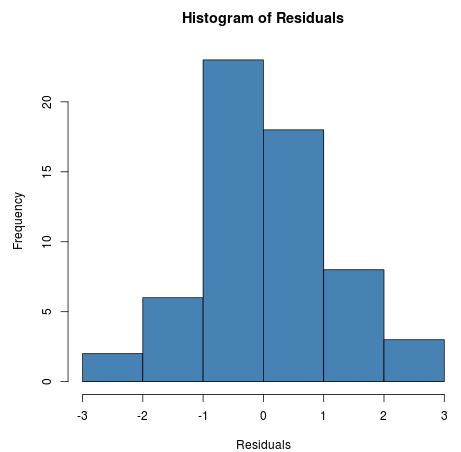
Die Residuen sind ungefähr normal verteilt, sodass wir davon ausgehen können, dass die Annahme einer Normalverteilung erfüllt ist.
3. Gleiche Varianz – Die Varianzen für jede Gruppe sind gleich oder ungefähr gleich.
Eine Möglichkeit, diese Annahme zu überprüfen, besteht darin, einen Levene-Test auf Varianzgleichheit mit dem car Package durchzuführen:
#car laden
library(car)
#Durchführen des Levene-Tests auf Gleichheit der Varianzen
leveneTest(weight_loss ~ gender * exercise, data = data)
#Levene's Test for Homogeneity of Variance (center = median)
# Df F value Pr(>F)
#group 5 1.8547 0.1177
# 54
Da der p-Wert des Tests größer als unser Signifikanzniveau von 0,05 ist, können wir davon ausgehen, dass unsere Annahme der Varianzgleichheit zwischen Gruppen erfüllt ist.
Sobald wir überprüft haben, dass die Modellannahmen erfüllt sind, können wir einen Post-hoc-Test durchführen, um genau zu bestimmen, welche Behandlungsgruppen sich voneinander unterscheiden.
Für unseren Post-Hoc-Test verwenden wir die Funktion TukeyHSD(), um den Tukey-Test für mehrere Vergleiche durchzuführen:
#Tukey's Test für mehrere Vergleiche durchführen
TukeyHSD(model, conf.level=.95)
# Tukey multiple comparisons of means
# 95% family-wise confidence level
#
#Fit: aov(formula = weight_loss ~ gender * exercise, data = data)
#
#$gender
# diff lwr upr p adj
#Male-Female 1.026456 0.4114451 1.641467 0.0014967
#
#$exercise
# diff lwr upr p adj
#Light-Intense -4.813064 -5.718493 -3.907635 0.0e+00
#None-Intense -6.938966 -7.844395 -6.033537 0.0e+00
#None-Light -2.125902 -3.031331 -1.220473 1.8e-06
#
#
Eine zweifaktorielle ANOVA („Varianzanalyse“) wird verwendet, um zu bestimmen, ob es einen statistisch signifikanten Unterschied zwischen den Mittelwerten von drei oder mehr unabhängigen Gruppen gibt, die auf zwei Faktoren aufgeteilt wurden.
In diesem Tutorial wird erklärt, wie eine zweifaktorielle ANOVA in R durchgeführt wird.
Angenommen, wir möchten feststellen, ob die Trainingsintensität und das Geschlecht den Gewichtsverlust beeinflussen. In diesem Fall sind die beiden Faktoren, die wir untersuchen, Bewegung und Geschlecht, und die Antwortvariable ist Gewichtsverlust, gemessen in Pfund.
Wir können eine zweifaktorielle ANOVA durchführen, um festzustellen, ob Bewegung und Geschlecht den Gewichtsverlust beeinflussen und ob es eine Wechselwirkung zwischen Bewegung und Geschlecht beim Gewichtsverlust gibt.
Wir rekrutieren 30 Männer und 30 Frauen, um an einem Experiment teilzunehmen, bei dem wir jeweils 10 zufällig zuweisen, um einen Monat lang einem Programm ohne Übung, leichte Übung oder intensive Übung zu folgen.
Der folgende Code erstellt das Dataframe, mit dem wir arbeiten werden:
#Machen Sie dieses Beispiel reproduzierbar
set.seed (10)
#Dataframe erstellen
data <- data.frame(gender = rep(c("Male", "Female"), each = 30),
exercise = rep(c("None", "Light", "Intense"), each = 10, times = 2),
weight_loss = c(runif(10, -3, 3), runif(10, 0, 5), runif(10, 5, 9),
runif(10, -4, 2), runif(10, 0, 3), runif(10, 3, 8)))
#Die ersten sechs Zeilen des Dataframes anzeigen
head(data)
# gender exercise weight_loss
#1 Male None 0.04486922
#2 Male None -1.15938896
#3 Male None -0.43855400
#4 Male None 1.15861249
#5 Male None -2.48918419
#6 Male None -1.64738030
# Sehen Sie, wie viele Teilnehmer in jeder Gruppe sind
table(data$gender, data$exercise)
# Intense Light None
# Female 10 10 10
# Male 10 10 10
Bevor wir überhaupt das zweifaktorielle ANOVA-Modell anpassen, können wir die Daten besser verstehen, indem wir den Mittelwert und die Standardabweichung des Gewichtsverlusts für jede der sechs Behandlungsgruppen mithilfe des dplyr Pakets ermitteln:
#dplyr laden
library(dplyr)
# Mittelwert und Standardabweichung des Gewichtsverlusts für jede Behandlungsgruppe ermitteln
data %>%
group_by(gender, exercise) %>%
summarise(mean = mean(weight_loss),
sd = sd(weight_loss))
# A tibble: 6 x 4
# Groups: gender [2]
# gender exercise mean sd
#
#1 Female Intense 5.31 1.02
#2 Female Light 0.920 0.835
#3 Female None -0.501 1.77
#4 Male Intense 7.37 0.928
#5 Male Light 2.13 1.22
#6 Male None -0.698 1.12
Wir können auch ein Boxplot für jede der sechs Behandlungsgruppen erstellen, um die Verteilung des Gewichtsverlusts für jede Gruppe zu visualisieren:
#Setzen Sie die Ränder so, dass die Achsenbeschriftungen im Boxplot nicht abgeschnitten werden
par(mar=c(8, 4.1, 4.1, 2.1))
# Boxplots erstellen
boxplot(weight_loss ~ gender:exercise,
data = data,
main = "Weight Loss Distribution by Group",
xlab = "Group",
ylab = "Weight Loss",
col = "steelblue",
border = "black",
las = 2 #make x-axis labels perpendicular
)
Auf Anhieb können wir sehen, dass die beiden Gruppen, die an intensiven Übungen teilgenommen haben, offenbar größere Gewichtsverlustwerte aufweisen. Wir können auch sehen, dass Männer im Vergleich zu Frauen tendenziell höhere Gewichtsverlustwerte für die intensiven und leichten Übungsgruppen haben.
Als Nächstes passen wir das zweifaktorielle ANOVA-Modell an unsere Daten an, um festzustellen, ob diese visuellen Unterschiede tatsächlich statistisch signifikant sind.
Die allgemeine Syntax für ein zweifaktorielles ANOVA-Modell in R lautet wie folgt:
aov(response variable ~ predictor_variable1 * predictor_variable2, data = dataset)
Beachten Sie, dass das * zwischen den beiden Prädiktorvariablen angibt, dass wir auch einen Interaktionseffekt zwischen den beiden Prädiktorvariablen testen möchten.
In unserem Beispiel können wir den folgenden Code verwenden, um das zweifaktorielle ANOVA-Modell anzupassen, wobei weight_loss als Antwortvariable und gender und exercise als unsere beiden Prädiktorvariablen verwendet werden. Wir können dann die Funktion summary() verwenden, um die Ausgabe unseres Modells anzuzeigen:
#Passen Sie das zweifaktorielle ANOVA-Modell an
model <- aov(weight_loss ~ gender * exercise, data = data)
# Sehen Sie sich die Modellausgabe an
summary(model)
# Df Sum Sq Mean Sq F value Pr(>F)
#gender 1 15.8 15.80 11.197 0.0015 **
#exercise 2 505.6 252.78 179.087 <2e-16 ***
#gender:exercise 2 13.0 6.51 4.615 0.0141 *
#Residuals 54 76.2 1.41
#---
#Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Aus der Modellausgabe können wir ersehen, dass gender, exercise und die Interaktion zwischen den beiden Variablen auf dem .05-Signifikanzniveau statistisch signifikant sind.
Bevor wir weiter gehen, sollten wir überprüfen, ob die Annahmen unseres Modells erfüllt sind, damit unsere Ergebnisse aus dem Modell zuverlässig sind. Insbesondere geht eine zweifaktorielle ANOVA davon aus:
1. Unabhängigkeit – Die Beobachtungen in jeder Gruppe müssen unabhängig voneinander sein. Da wir ein randomisiertes Design verwendet haben, sollte diese Annahme erfüllt sein, damit wir uns darüber keine Sorgen machen müssen.
2. Normalverteilung – Die abhängige Variable sollte für jede Kombination der Gruppen der beiden Faktoren ungefähr normal verteilt sein.
Eine Möglichkeit, diese Annahme zu überprüfen, besteht darin, ein Histogramm der Modellresiduen zu erstellen. Wenn die Residuen grob normalverteilt sind, sollte diese Annahme erfüllt sein.
#Modellresiduen definieren
resid <- model$residuals
# Histogramm der Residuen erstellen
hist(resid, main = "Histogram of Residuals", xlab = "Residuals", col = "steelblue")
Die Residuen sind ungefähr normal verteilt, sodass wir davon ausgehen können, dass die Annahme einer Normalverteilung erfüllt ist.
3. Gleiche Varianz – Die Varianzen für jede Gruppe sind gleich oder ungefähr gleich.
Eine Möglichkeit, diese Annahme zu überprüfen, besteht darin, einen Levene-Test auf Varianzgleichheit mit dem car Package durchzuführen:
#car laden
library(car)
#Durchführen des Levene-Tests auf Gleichheit der Varianzen
leveneTest(weight_loss ~ gender * exercise, data = data)
#Levene's Test for Homogeneity of Variance (center = median)
# Df F value Pr(>F)
#group 5 1.8547 0.1177
# 54
Da der p-Wert des Tests größer als unser Signifikanzniveau von 0,05 ist, können wir davon ausgehen, dass unsere Annahme der Varianzgleichheit zwischen Gruppen erfüllt ist.
Sobald wir überprüft haben, dass die Modellannahmen erfüllt sind, können wir einen Post-hoc-Test durchführen, um genau zu bestimmen, welche Behandlungsgruppen sich voneinander unterscheiden.
Für unseren Post-Hoc-Test verwenden wir die Funktion TukeyHSD(), um den Tukey-Test für mehrere Vergleiche durchzuführen:
#Tukey's Test für mehrere Vergleiche durchführen
TukeyHSD(model, conf.level=.95)
# diff lwr upr p adj
#Male:Intense-Female:Intense 2.0628297 0.4930588 3.63260067 0.0036746
#Female:Light-Female:Intense -4.3883563 -5.9581272 -2.81858535 0.0000000
#Male:Light-Female:Intense -3.1749419 -4.7447128 -1.60517092 0.0000027
#Female:None-Female:Intense -5.8091131 -7.3788841 -4.23934219 0.0000000
#Male:None-Female:Intense -6.0059891 -7.5757600 -4.43621813 0.0000000
#Female:Light-Male:Intense -6.4511860 -8.0209570 -4.88141508 0.0000000
#Male:Light-Male:Intense -5.2377716 -6.8075425 -3.66800066 0.0000000
#Female:None-Male:Intense -7.8719429 -9.4417138 -6.30217192 0.0000000
#Male:None-Male:Intense -8.0688188 -9.6385897 -6.49904786 0.0000000
#Male:Light-Female:Light 1.2134144 -0.3563565 2.78318536 0.2185439
#Female:None-Female:Light -1.4207568 -2.9905278 0.14901410 0.0974193
#Male:None-Female:Light -1.6176328 -3.1874037 -0.04786184 0.0398106
#Female:None-Male:Light -2.6341713 -4.2039422 -1.06440032 0.0001050
#Male:None-Male:Light -2.8310472 -4.4008181 -1.26127627 0.0000284
#Male:None-Female:None -0.1968759 -1.7666469 1.37289500 0.9990364
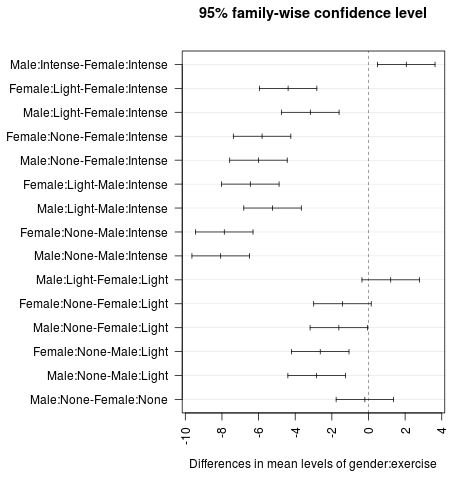
Der p-Wert gibt an, ob zwischen jeder Gruppe ein statistisch signifikanter Unterschied besteht oder nicht. Zum Beispiel sehen wir in der letzten Zeile oben, dass die männliche Gruppe ohne Training keinen statistisch signifikanten Unterschied im Gewichtsverlust im Vergleich zur weiblichen Gruppe ohne Training aufwies (p-Wert: 0,990364).
Wir können auch die 95%-Konfidenzintervalle visualisieren, die sich aus dem Tukey-Test ergeben, indem wir die Funktion plot() in R verwenden:
#Setzen Sie die Achsenränder so, dass Beschriftungen nicht abgeschnitten werden
par(mar=c(4.1, 13, 4.1, 2.1))
#Konfidenzintervall für jeden Vergleich erstellen
plot(TukeyHSD(model, conf.level=.95), las = 2)
Zuletzt können wir die Ergebnisse der zweifaktorielle ANOVA so berichten, dass die Ergebnisse zusammengefasst werden:
Eine zweifaktorielle ANOVA wurde durchgeführt, um die Auswirkungen des Geschlechts ( männlich, weiblich) und des Trainingsplans (keine, leicht, intensiv) auf den Gewichtsverlust (Maß in Pfund) zu untersuchen. Es gab eine statistisch signifikante Wechselwirkung zwischen den Auswirkungen von Geschlecht und Bewegung auf den Gewichtsverlust (F (2, 54) = 4,615, p = 0,0141). Tukeys HSD-Post-Hoc-Tests wurden durchgeführt.
Bei Männern führte ein intensives Trainingsprogramm zu einem signifikant höheren Gewichtsverlust im Vergleich zu einem leichten Trainingsprogramm (p <0,0001) und keinem Trainingsprogramm (p <0,0001). Zusätzlich führte ein leichtes Regime bei Männern zu einem signifikant höheren Gewichtsverlust im Vergleich zu keinem Trainingsprogramm (p <0,0001).
Bei Frauen führte ein intensives Trainingsprogramm zu einem signifikant höheren Gewichtsverlust im Vergleich zu einem leichten Trainingsprogramm (p <0,0001) und keinem Trainingsprogramm (p <0,0001).
Prüfungen auf Normalverteilung und Levene-Tests wurden durchgeführt, um zu überprüfen, ob die ANOVA-Annahmen erfüllt waren.
Eine einfaktorielle ANOVA wird verwendet, um zu bestimmen, ob es einen statistisch signifikanten Unterschied zwischen den Mittelwerten von drei oder mehr unabhängigen Gruppen gibt oder nicht.
Das folgende Beispiel bietet …
Eine geschachtelte ANOVA ist eine Art ANOVA („Varianzanalyse“), bei der mindestens ein Faktor in einem anderen Faktor verschachtelt ist.
Nehmen wir zum Beispiel an, ein Forscher möchte wissen, ob drei …