
Ein Mann-Kendall-Trendtest wird verwendet, um festzustellen, ob in Zeitreihendaten ein Trend vorhanden ist oder nicht. Es ist ein nichtparametrischer Test, was bedeutet, dass keine zugrunde liegende Annahme über die Normalität …
Der häufigste Weg, um die Mittelwerte zwischen zwei unabhängigen Gruppen zu vergleichen, ist die Verwendung eines Zweistichproben-t-Tests. Bei diesem Test wird jedoch davon ausgegangen, dass die Varianzen zwischen den beiden Gruppen gleich sind.
Wenn Sie den Verdacht haben, dass die Varianz zwischen den beiden Gruppen nicht gleich ist, können Sie stattdessen den Welch-Test verwenden, der das nicht parametrische Äquivalent des Zwei-Stichproben-t-Tests darstellt.
In diesem Tutorial wird erklärt, wie der Welch-Test in Stata durchgeführt wird.
Beispiel: Welch-Test in Stata
Für dieses Beispiel verwenden wir den Kraftstoff3- Datensatz, der die mpg von 12 Autos enthält, die eine bestimmte Kraftstoffbehandlung erhalten haben, und 12 Autos, die dies nicht getan haben.
Führen Sie die folgenden Schritte aus, um einen Welch-Test durchzuführen, um festzustellen, ob zwischen den beiden Gruppen ein Unterschied im mittleren mpg besteht.
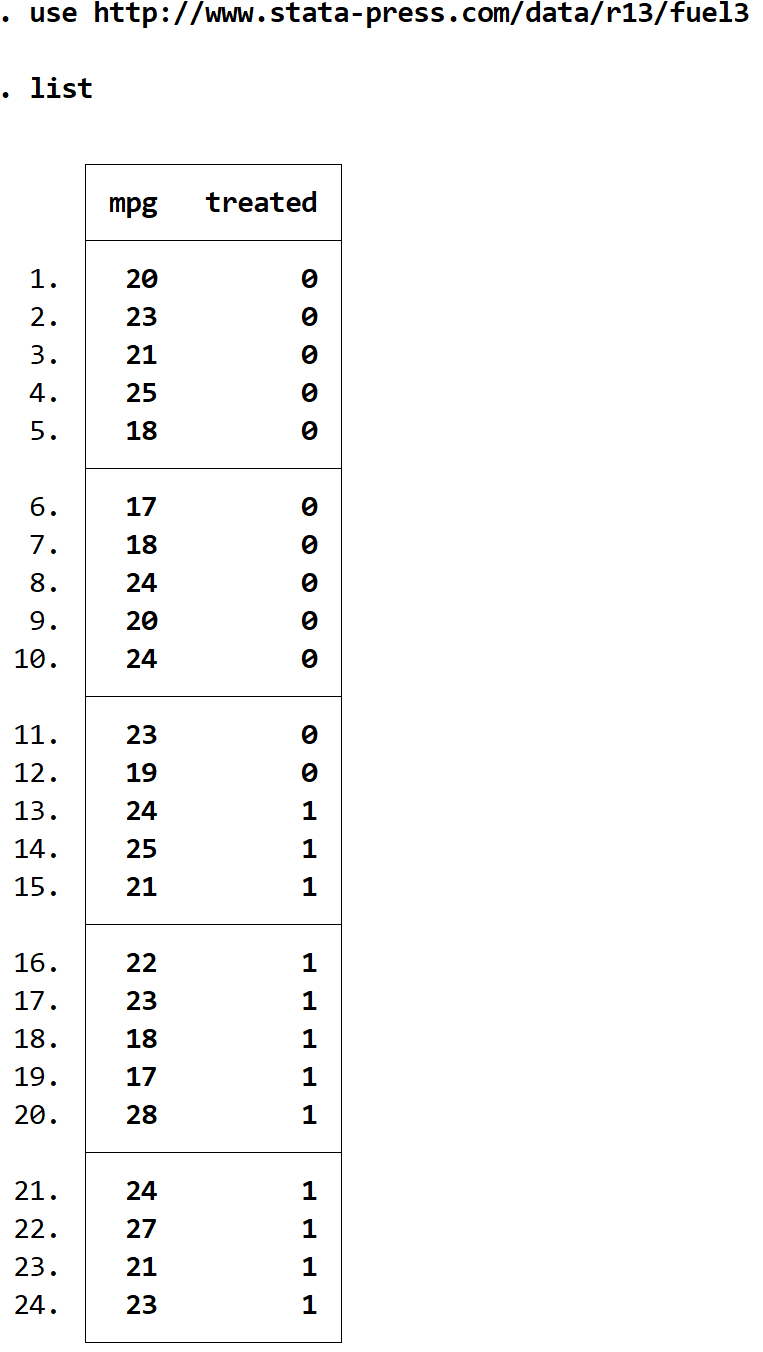
Schritt 1: Laden und Anzeigen der Daten.
Laden Sie zunächst den Datensatz, indem Sie den folgenden Befehl in das Befehlsfeld eingeben:
use Sie http://www.stata-press.com/data/r13/fuel3
Zeigen Sie die Rohdaten mit dem folgenden Befehl an:
list
Schritt 2: Visualisieren Sie die Daten.
Bevor wir den Welch-Test durchführen, erstellen wir zunächst zwei Box-Plots, um die Verteilung von mpg für jede Gruppe zu visualisieren:
graph box mpg, over(treated)
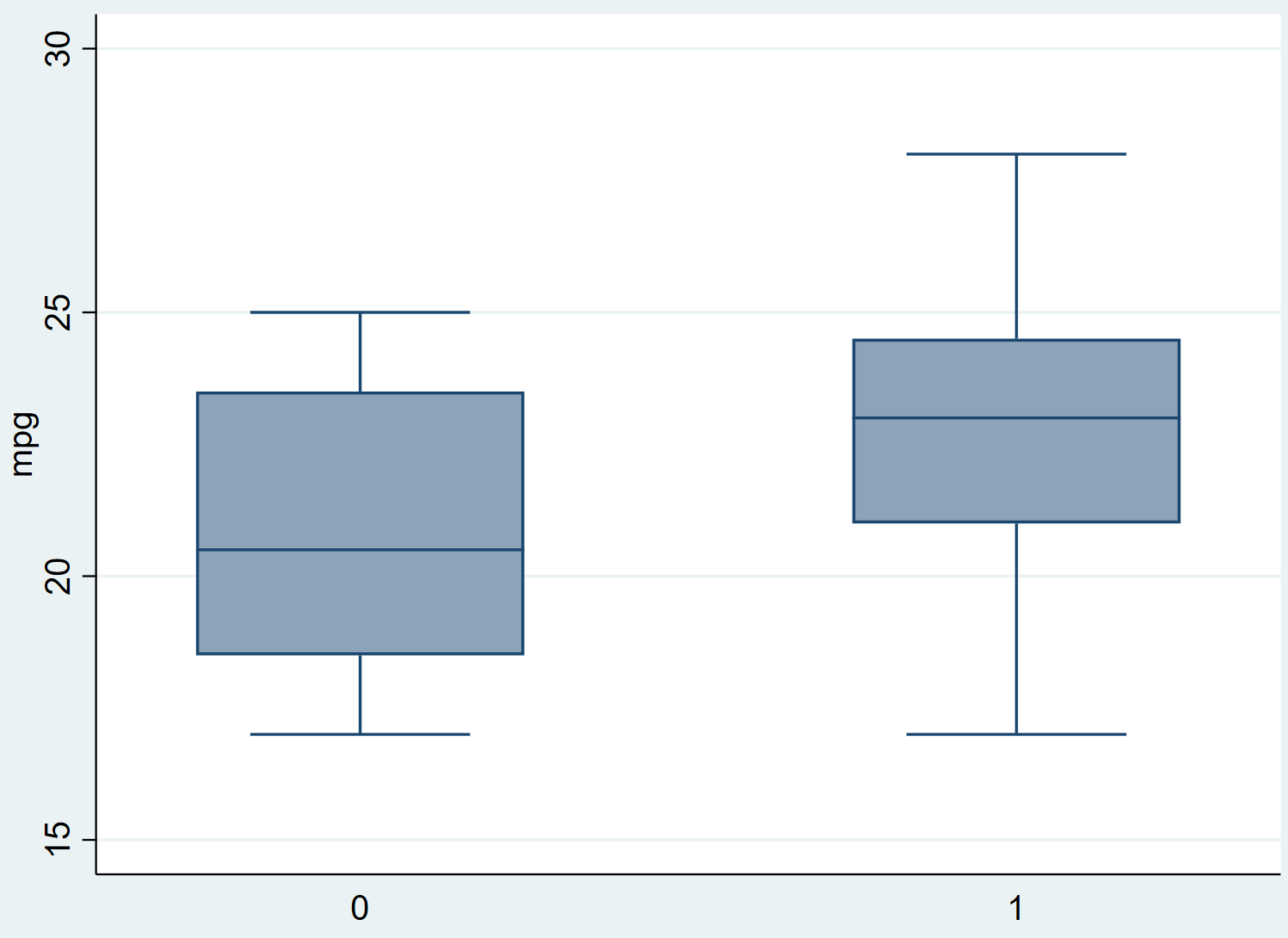
Wir können sehen, dass die mpg für Gruppe 1 (die Gruppe, die die Kraftstoffbehandlung erhalten hat) tendenziell höher ist als die von Gruppe 0. Wir können auch sehen, dass die Varianz für Gruppe 1 ziemlich viel kleiner aussieht als die von Gruppe 0 (die Breite der Box ist kleiner).
Schritt 3: Führen Sie den Welch-Test durch
Verwenden Sie die folgende Syntax, um den Welch-Test durchzuführen:
ttest variable_to_measure, by(grouping_variable) welch
Hier ist die Syntax für unser spezielles Beispiel:
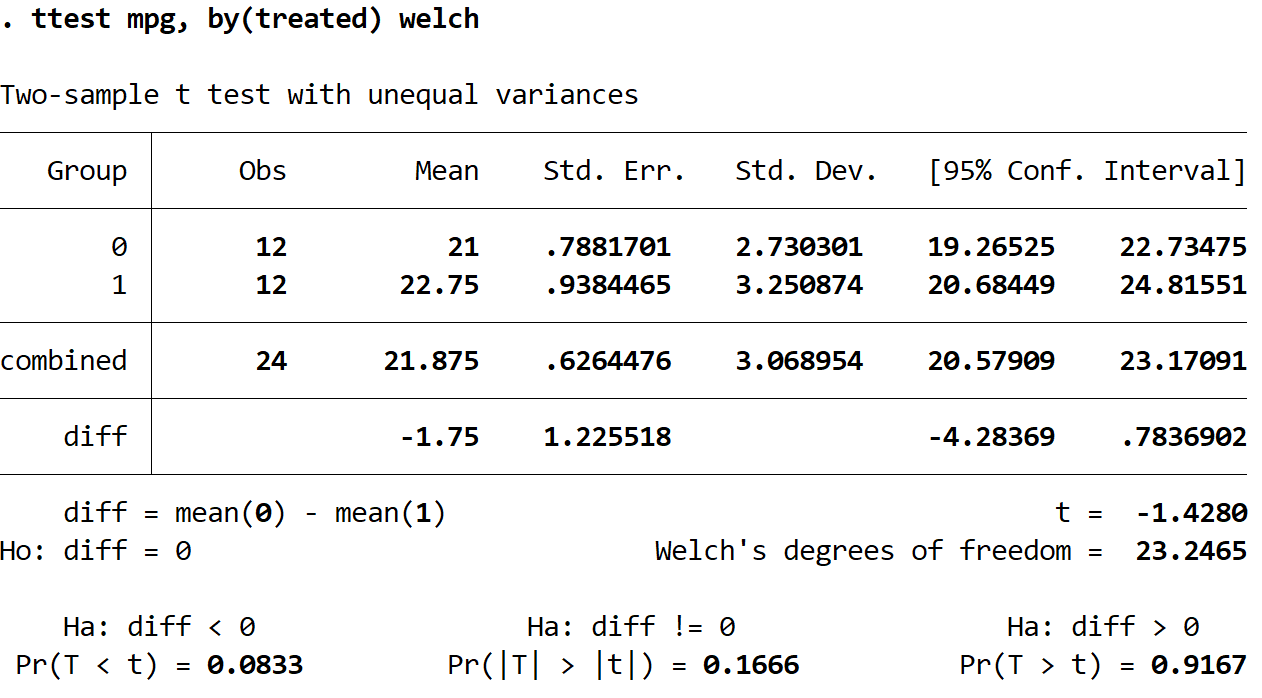
ttest mpg, by(treated) welch
So interpretieren Sie die Ausgabe:
- Der mittlere mpg für Gruppe 0 betrug 21. Das 95%-Konfidenzintervall für den wahren Bevölkerungsdurchschnitt betrug (19,26525, 22,73745).
- Der mittlere mpg für Gruppe 1 betrug 22,75. Das 95%-Konfidenzintervall für den wahren Populationsmittelwert betrug (20,68449, 24,81551).
- Der mittlere Unterschied in mpg für Gruppe 0 – Gruppe 1 betrug -1,75. Das 95%-Konfidenzintervall für den tatsächlichen Unterschied im Populationsmittelwert betrug (-4,28369, 0,7836902).
- Die Teststatistik t für den Welch-Test betrug -1,4280.
- Da wir an der alternativen Hypothese interessiert sind, dass der mittlere mpg zwischen den beiden Gruppen einfach unterschiedlich war, werden wir uns den mit Ha: diff! = 0 verbundenen p-Wert ansehen, der sich als 0,1666 herausstellt. Da dieser Wert nicht weniger als 0,05 beträgt, gibt es keine ausreichenden Beweise dafür, dass der mittlere mpg zwischen den beiden Gruppen unterschiedlich ist.
Schritt 4: Ergebnisse.
Zuletzt möchten wir die Ergebnisse unseres Welch-Tests melden. Hier ist ein Beispiel dafür:
Ein Welch-Test wurde durchgeführt, um festzustellen, ob es einen statistisch signifikanten Unterschied in der MPG zwischen einer Gruppe von Autos, die eine Kraftstoffbehandlung erhielten, und einer Gruppe, die dies nicht tat, gab. Die Stichprobengröße für beide Gruppen betrug 12 Autos.
Ein Welch-Test ergab, dass es keinen statistisch signifikanten Mittelwertunterschied (t = -1,4280, p = 0,1666) zwischen den beiden Gruppen gab.
Das 95%-Konfidenzintervall für den wahren mittleren Unterschied in Gruppe 0 (Nichtbehandlungsgruppe) und Gruppe 1 (Behandlungsgruppe) betrug (-4,28369, 0,7836902).
Das könnte Sie auch interessieren:
So führen Sie einen Mann-Kendall-Trendtest in Python durch
So führen Sie einen Chow-Test in Python durch
Ein Chow-Test wird verwendet, um zu testen, ob die Koeffizienten in zwei verschiedenen Regressionsmodellen auf verschiedenen Datensätzen gleich sind.
Dieser Test wird typischerweise im Bereich der Ökonometrie mit Zeitreihendaten verwendet …