
Ein Mann-Kendall-Trendtest wird verwendet, um festzustellen, ob in Zeitreihendaten ein Trend vorhanden ist oder nicht. Es ist ein nichtparametrischer Test, was bedeutet, dass keine zugrunde liegende Annahme über die Normalität …
Ein t-Test mit gepaarten Stichproben wird verwendet, um die Mittelwerte von zwei Stichproben zu vergleichen, wenn jede Beobachtung in einer Probe mit einer Beobachtung in der anderen Probe gepaart werden kann.
In diesem Tutorial wird erklärt, wie ein t-Test mit gepaarten Stichproben in Stata durchgeführt wird.
Beispiel: t-Test mit gepaarten Stichproben in Stata
Forscher wollen wissen, ob eine neue Kraftstoffbehandlung zu einer Änderung des durchschnittlichen mpg eines bestimmten Autos führt. Um dies zu testen, führen sie ein Experiment durch, bei dem sie den mpg von 12 Autos mit und ohne Kraftstoffbehandlung messen.
Da jedes Auto die Behandlung erhält, können wir einen gepaarten t-Test durchführen, bei dem jedes Auto mit sich selbst gepaart wird, um festzustellen, ob es einen Unterschied in der durchschnittlichen mpg mit und ohne Kraftstoffbehandlung gibt.
Führen Sie die folgenden Schritte aus, um einen gepaarten t-Test in Stata durchzuführen.
Schritt 1: Laden Sie die Daten.
Laden Sie zunächst die Daten, indem Sie use http://www.stata-press.com/data/r13/fuel in das Befehlsfeld eingeben und auf die Eingabetaste klicken.
Schritt 2: Zeigen Sie die Rohdaten an.
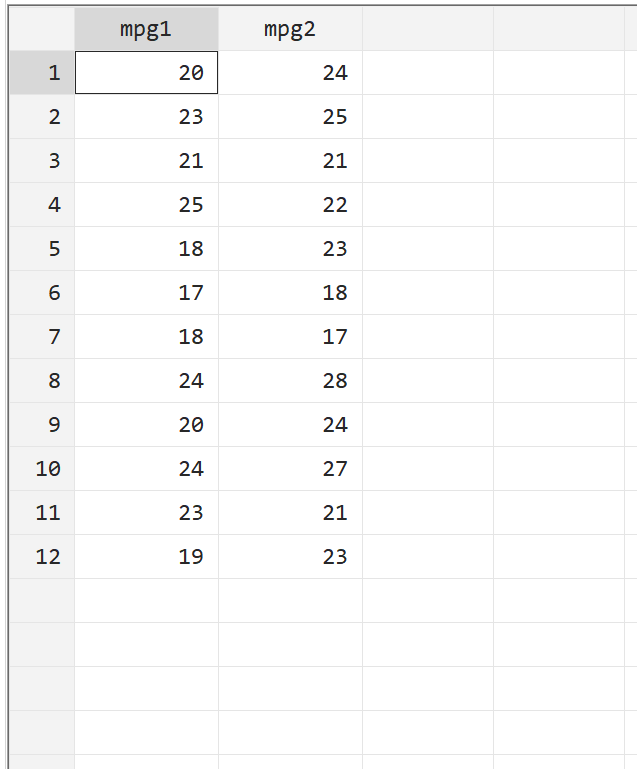
Bevor wir einen gepaarten t-Test durchführen, sehen wir uns zunächst die Rohdaten an. Gehen Sie in der oberen Menüleiste zu Daten> Dateneditor> Dateneditor (Durchsuchen). Die erste Spalte mpg1 zeigt die mpg für das erste Auto ohne Kraftstoffbehandlung, während die zweite Spalte mpg2 die mpg für das erste Auto mit der Kraftstoffbehandlung zeigt.
Schritt 3: Führen Sie einen gepaarten t-Test durch.
Gehen Sie in der oberen Menüleiste zu Statistik> Zusammenfassungen, Tabellen und Tests> Klassische Hypothesentests> t-Test (Mittelwertvergleichstest).
Wählen Sie Paired. Wählen Sie als erste Variable mpg1. Wählen Sie als zweite Variable mpg2. Wählen Sie als Vertrauensstufe eine beliebige Stufe aus. Ein Wert von 95 entspricht einem Signifikanzniveau von 0,05. Wir werden dies bei 95 belassen. Klicken Sie abschließend auf OK.
Die Ergebnisse des gepaarten t-Tests werden angezeigt:
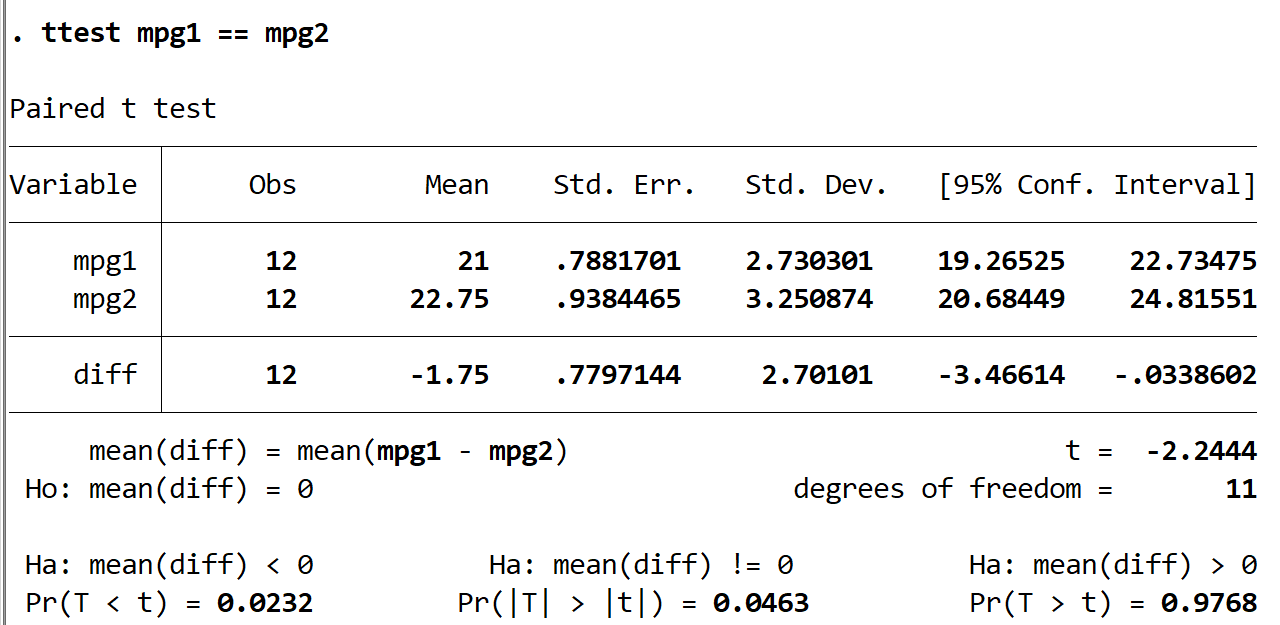
Für jede Gruppe erhalten wir folgende Informationen:
Obs: Die Anzahl der Beobachtungen. In jeder Gruppe gibt es 12 Beobachtungen.
Mean: Der Mittelwert mpg. In Gruppe 0 beträgt der Mittelwert 21. In Gruppe 1 beträgt der Mittelwert 22,75.
Std. Err: Der Standardfehler, berechnet als σ / √ n
Std. Dev: Die Standardabweichung von mpg.
95% Conf. Intervall: Das 95%-Konfidenzintervall für den wahren Populationsmittelwert von mpg.
t: Die Teststatistik des gepaarten t-Tests.
degrees of freedom: Die für den Test zu verwendenden Freiheitsgrade, berechnet als # Paare-1 = 12-1 = 11.
Die p-Werte für drei verschiedene zwei Stichproben-t-Tests werden am Ende der Ergebnisse angezeigt. Da wir verstehen möchten, ob der durchschnittliche mpg zwischen den beiden Gruppen einfach unterschiedlich ist, werden wir uns die Ergebnisse des mittleren Tests (bei dem die alternative Hypothese Ha: diff! = 0 ist) ansehen, der einen p-Wert von 0,0463 hat.
Da dieser Wert kleiner als unser Signifikanzniveau von 0,05 ist, lehnen wir die Nullhypothese ab. Wir haben genügend Beweise, um zu sagen, dass der wahre mittlere mpg zwischen den beiden Gruppen unterschiedlich ist.
Schritt 5: Ergebnisse.
Zuletzt werden wir die Ergebnisse unseres gepaarten t-Tests berichten. Hier ist ein Beispiel dafür:
Ein gepaarter t-Test wurde an 12 Autos durchgeführt, um festzustellen, ob eine neue Kraftstoffbehandlung zu einem Unterschied in den mittleren Meilen pro Gallone führte.
Die Ergebnisse zeigten, dass der mittlere mpg statistisch signifikant war unterschiedlich zwischen den beiden Gruppen (t = -2,2444 w / df = 11, p = 0,0463) bei einem Signifikanzniveau von 0,05.
Ein 95%-Konfidenzintervall für den wahren Unterschied im Populationsmittelwerte ergab das Intervall von (-3,466, -.034).
Basierend auf diesen Ergebnissen führt die neue Kraftstoffbehandlung zu einem statistisch signifikant höheren mpg für Autos.
Das könnte Sie auch interessieren:
So führen Sie einen Mann-Kendall-Trendtest in Python durch
So führen Sie einen Chow-Test in Python durch
Ein Chow-Test wird verwendet, um zu testen, ob die Koeffizienten in zwei verschiedenen Regressionsmodellen auf verschiedenen Datensätzen gleich sind.
Dieser Test wird typischerweise im Bereich der Ökonometrie mit Zeitreihendaten verwendet …