
Ein Log-Log-Diagramm ist ein Diagramm, das sowohl auf der x-Achse als auch auf der y-Achse logarithmische Skalen verwendet.
Diese Art von Diagramm ist nützlich, um zwei Variablen zu visualisieren, wenn …
Die Hauptkomponentenanalyse (PCA) ist eine unbeaufsichtigte Technik des maschinellen Lernens, die Hauptkomponenten (lineare Kombinationen der Prädiktorvariablen) findet, die einen großen Teil der Variation in einem Datensatz erklären.
Wenn wir PCA durchführen, sind wir daran interessiert zu verstehen, welcher Prozentsatz der Gesamtvariation im Datensatz durch jede Hauptkomponente erklärt werden kann.
Eine der einfachsten Möglichkeiten zur Visualisierung des Variationsprozentsatzes, der durch jede Hauptkomponente erklärt wird, ist die Erstellung eines Screeplots.
Dieses Tutorial enthält ein Schritt-für-Schritt-Beispiel zum Erstellen eines Scree-Plots in Python.
Für dieses Beispiel verwenden wir einen Datensatz namens USArrests, der Daten über die Anzahl der Verhaftungen pro 100.000 Einwohner in jedem US-Bundesstaat im Jahr 1973 für verschiedene Verbrechen enthält.
Der folgende Code zeigt, wie dieses Dataset importiert und für die Hauptkomponentenanalyse vorbereitet wird:
import pandas as pd
from sklearn.preprocessing import StandardScaler
#URL, wo sich der Datensatz befindet definieren
url = "https://raw.githubusercontent.com/JWarmenhoven/ISLR-python/master/Notebooks/Data/USArrests.csv"
#Daten einlesen
data = pd.read_csv(url)
#Spalten zur Verwendung für PCA definieren
df = data.iloc[:, 1:5]
#Scaler definieren
scaler = StandardScaler()
#Kopie des DataFrames erstellen
scaled_df=df.copy()
#skalierte Version des DataFrames
scaled_df=pd.DataFrame(scaler.fit_transform(scaled_df), columns=scaled_df.columns)
Als Nächstes verwenden wir die PCA()-Funktion aus dem sklearn-Paket, um eine Hauptkomponentenanalyse durchzuführen.
from sklearn.decomposition import PCA
#zu verwendendes PCA-Modell definieren
pca = PCA(n_components=4)
# PCA-Modell an Daten anpassen
pca_fit = pca.fit(scaled_df)
Zuletzt berechnen wir den Prozentsatz der Gesamtvarianz, der durch jede Hauptkomponente erklärt wird, und verwenden matplotlib, um ein Screeplot zu erstellen:
import matplotlib.pyplot as plt
import numpy as np
PC_values = np.arange(pca.n_components_) + 1
plt.plot(PC_values, pca.explained_variance_ratio_, 'o-', linewidth=2, color='blue')
plt.title('Scree Plot')
plt.xlabel('Principal Component')
plt.ylabel('Variance Explained')
plt.show()
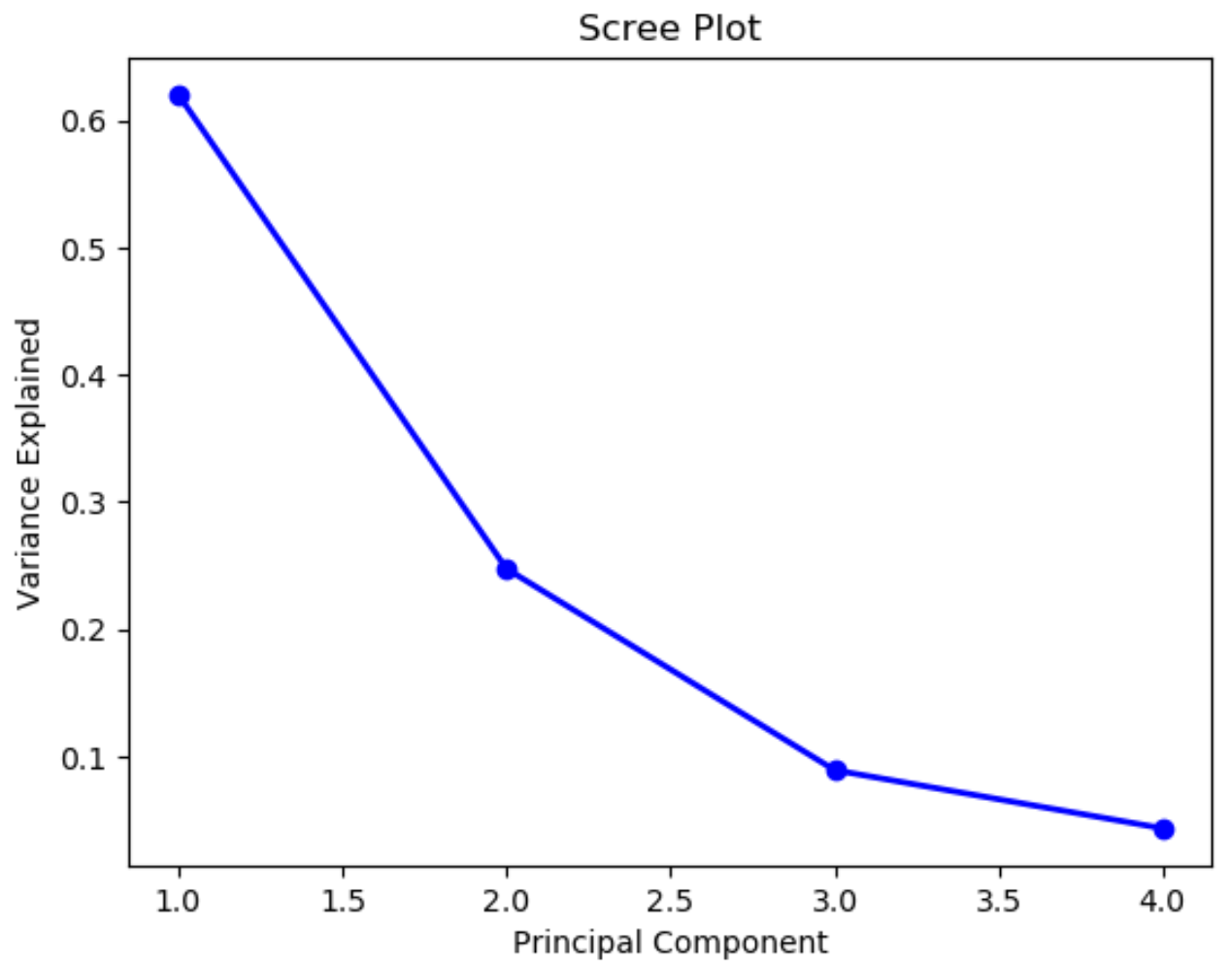
Die x-Achse zeigt die Hauptkomponente und die y-Achse den Prozentsatz der Gesamtvarianz, der durch jede einzelne Hauptkomponente erklärt wird.
Wir können auch den folgenden Code verwenden, um den genauen Prozentsatz der Gesamtvarianz anzuzeigen, der durch jede Hauptkomponente erklärt wird:
print(pca.explained_variance_ratio_)
[0.62006039 0.24744129 0.0891408 0.04335752]
Wir sehen:
Beachten Sie, dass die Summe der Prozentsätze 100% ergibt.
Weitere Tutorials zum maschinellen Lernen finden Sie auf dieser Seite.
Ein Log-Log-Diagramm ist ein Diagramm, das sowohl auf der x-Achse als auch auf der y-Achse logarithmische Skalen verwendet.
Diese Art von Diagramm ist nützlich, um zwei Variablen zu visualisieren, wenn …
Bei der Verwendung von Klassifizierungsmodellen beim maschinellen Lernen verwenden wir häufig zwei Metriken, um die Qualität des Modells zu bewerten, nämlich Präzision und Erinnerung.
Precision: Korrigieren Sie positive Vorhersagen im …