
Das Resampling von Zeitreihendaten bedeutet, die Daten für einen neuen Zeitraum zusammenzufassen oder zu aggregieren.
Wir können die folgende grundlegende Syntax verwenden, um Zeitreihendaten in Python neu abzutasten:
#Finde die …In der Statistik ist die Regressionsanalyse eine Technik, mit der wir die Beziehung zwischen einer Prädiktorvariablen x und einer Antwortvariablen y verstehen.
Wenn wir eine Regressionsanalyse durchführen, erhalten wir ein Modell, das den vorhergesagten Wert für die Antwortvariable basierend auf dem Wert der Prädiktorvariablen angibt.
Eine Möglichkeit, um zu beurteilen, wie „gut“ unser Modell zu einem bestimmten Datensatz passt, besteht darin, den RMSE (Root Mean Squared Error) zu berechnen. Diese Metrik gibt an, wie weit unsere vorhergesagten Werte von unseren beobachteten Werten im Durchschnitt entfernt sind.
Die Formel zum Ermitteln des quadratischen mittleren Fehlers, üblicherweise als RMSE bezeichnet, lautet wie folgt:
RMSE = √ [Σ (P i – O i ) 2 / n]
wobei:
Nerd-Notizen:
- Der RMSE kann für jeden Modelltyp berechnet werden, der vorhergesagte Werte erzeugt, die dann mit den beobachteten Werten eines Datensatzes verglichen werden können.
- Der RMSE wird manchmal auch als quadratische mittlere Abweichung bezeichnet, die häufig als RMSD abgekürzt wird.
Schauen wir uns als nächstes ein Beispiel für die Berechnung des quadratischen Mittelwertfehlers in Excel an.
Es gibt keine integrierte Funktion zum Berechnen von RMSE in Excel, aber wir können es ziemlich einfach mit einer einzigen Formel berechnen. Wir zeigen, wie RMSE für zwei verschiedene Szenarien berechnet wird.
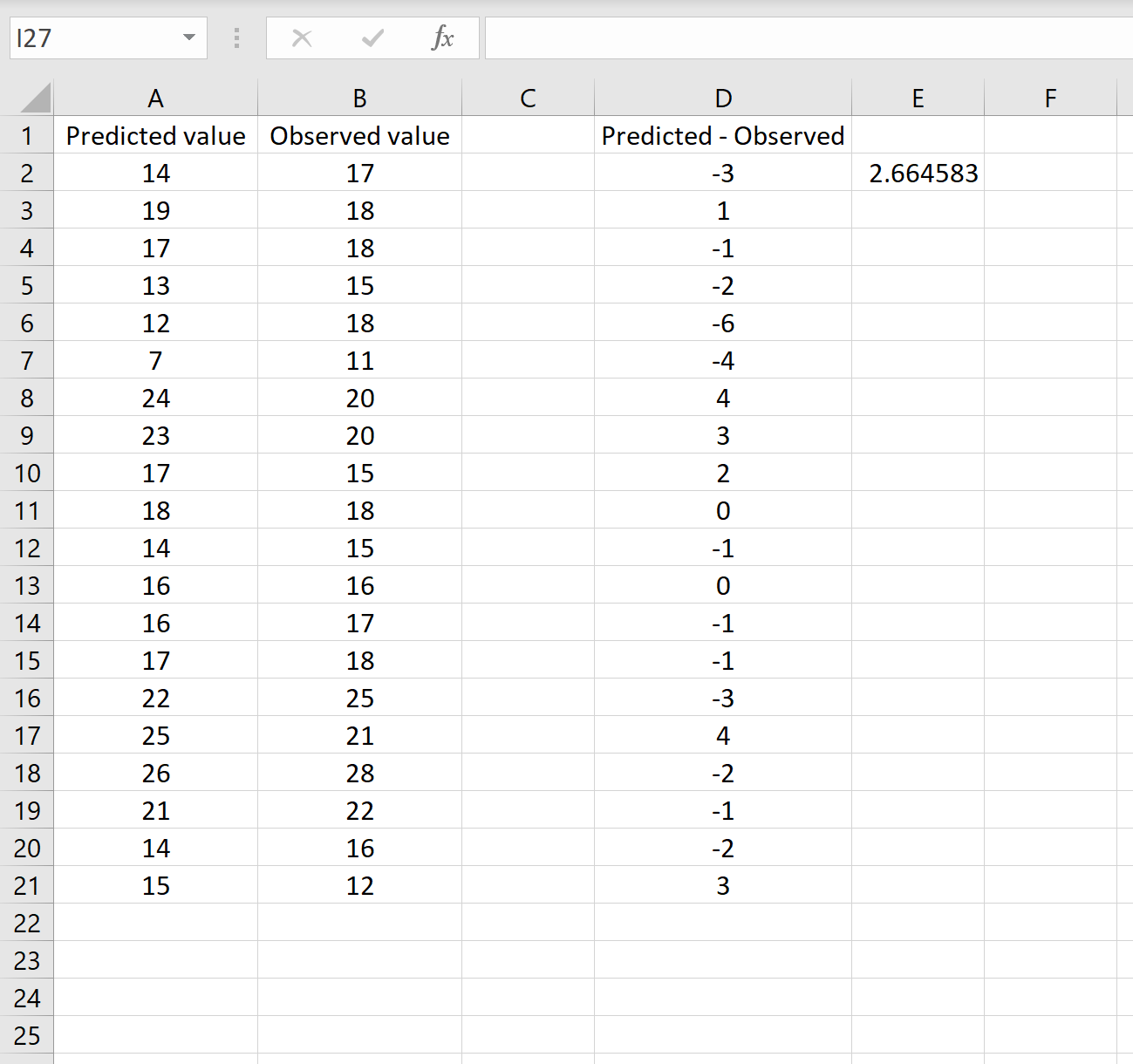
In einem Szenario haben Sie möglicherweise eine Spalte, die die vorhergesagten Werte Ihres Modells enthält, und eine andere Spalte, die die beobachteten Werte enthält. Das folgende Bild zeigt ein Beispiel für dieses Szenario:
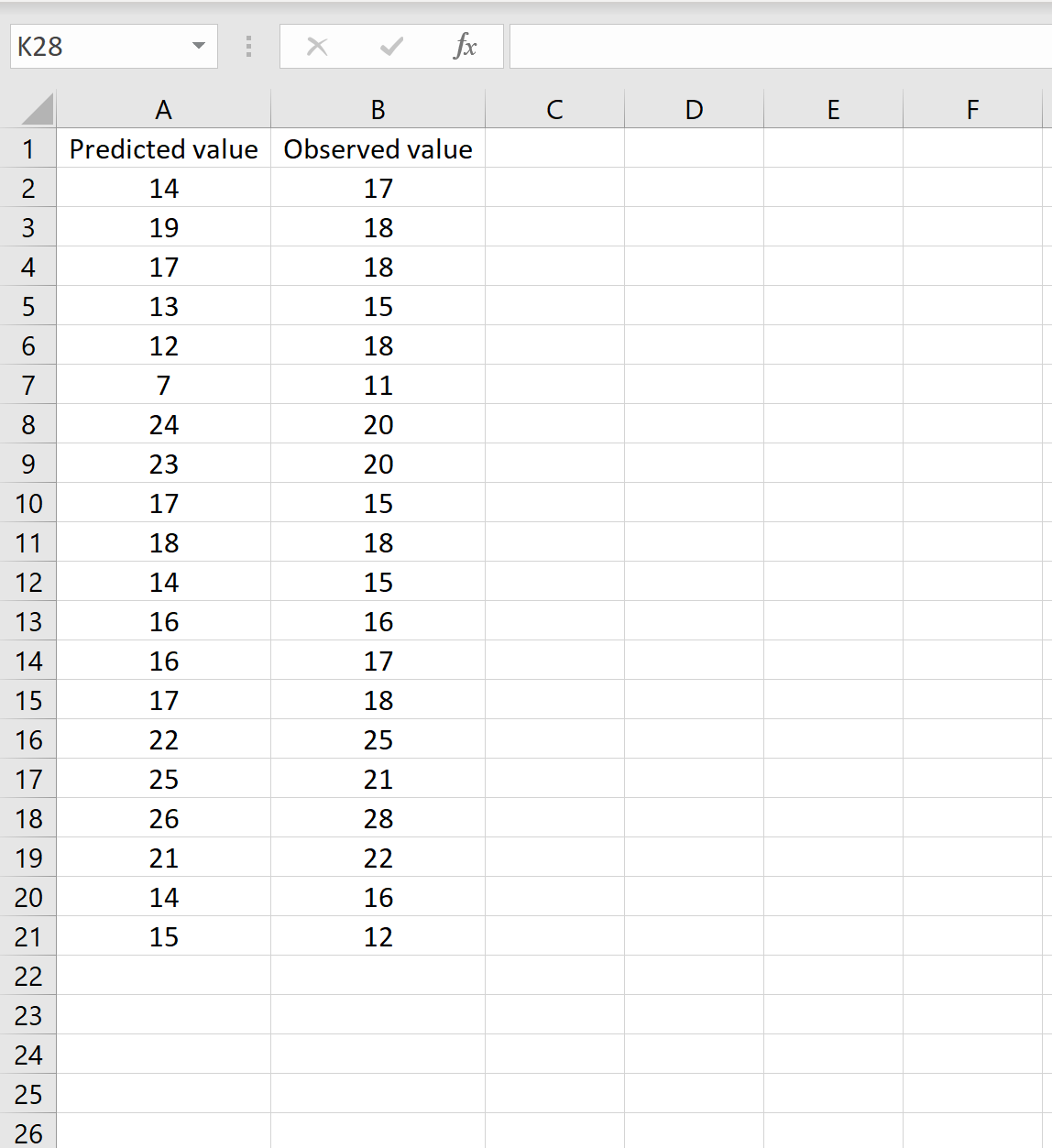
Wenn dies der Fall ist, können Sie den RMSE berechnen, indem Sie die folgende Formel in eine beliebige Zelle eingeben und dann auf STRG + UMSCHALT + EINGABETASTE klicken:
=WURZEL(QUADRATSUMME(A2:A21-B2:B21) / ANZAHL2(A2:A21))
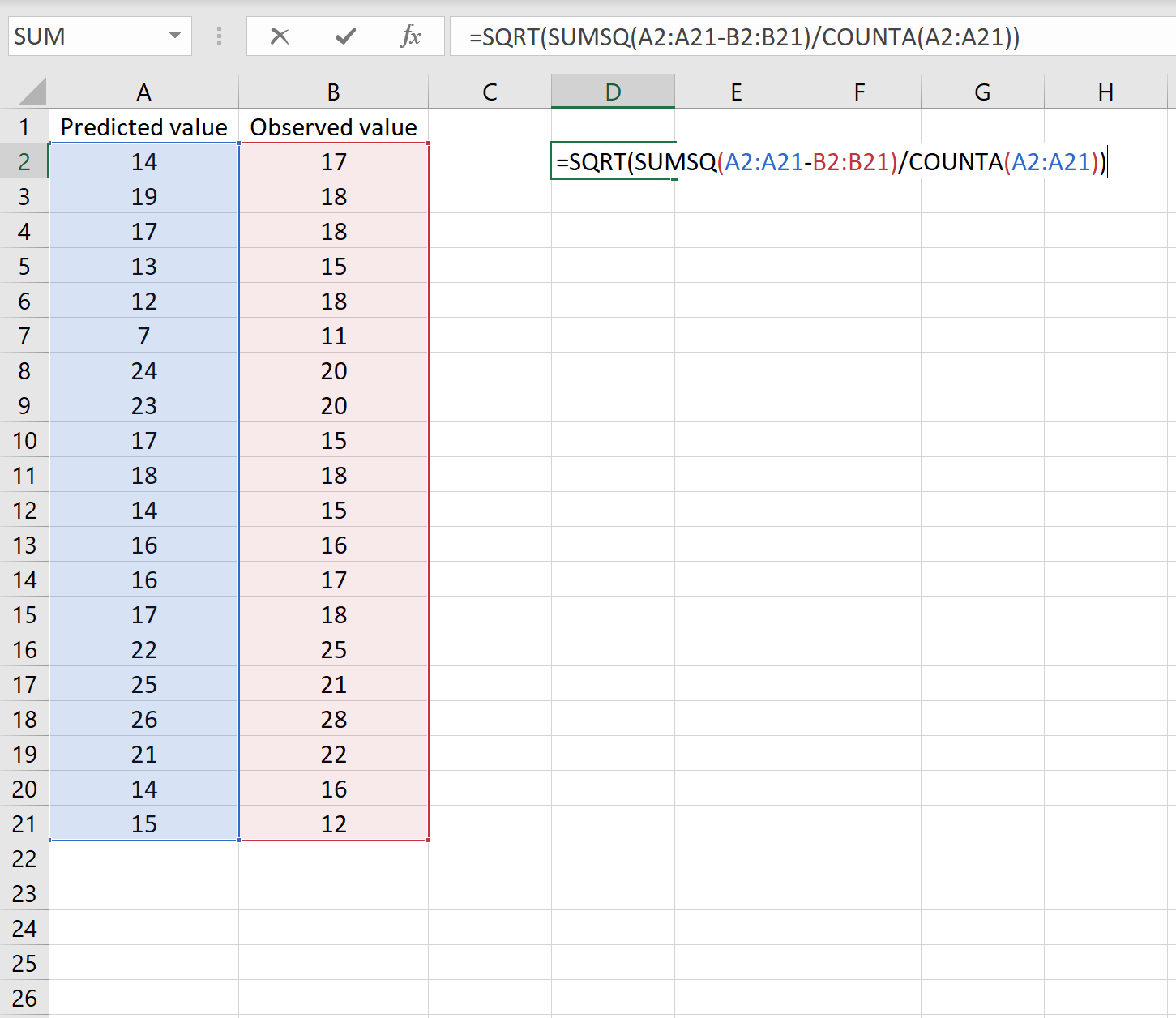
Dies sagt uns, dass der mittlere quadratische Fehler 2,6646 beträgt.

Die Formel mag etwas knifflig aussehen, macht aber Sinn, wenn Sie sie einmal aufgeschlüsselt haben:
= WURZEL(QUADRATSUMME(A2:A21-B2:B21)/ANZAHL2(A2:A21))
In einem anderen Szenario haben Sie möglicherweise bereits die Unterschiede zwischen den vorhergesagten und den beobachteten Werten berechnet. In diesem Fall haben Sie nur eine Spalte, in der die Unterschiede angezeigt werden.
Das Bild unten zeigt ein Beispiel für dieses Szenario. Die vorhergesagten Werte werden in Spalte A angezeigt, die beobachteten Werte in Spalte B und die Differenz zwischen den vorhergesagten und beobachteten Werten in Spalte D:
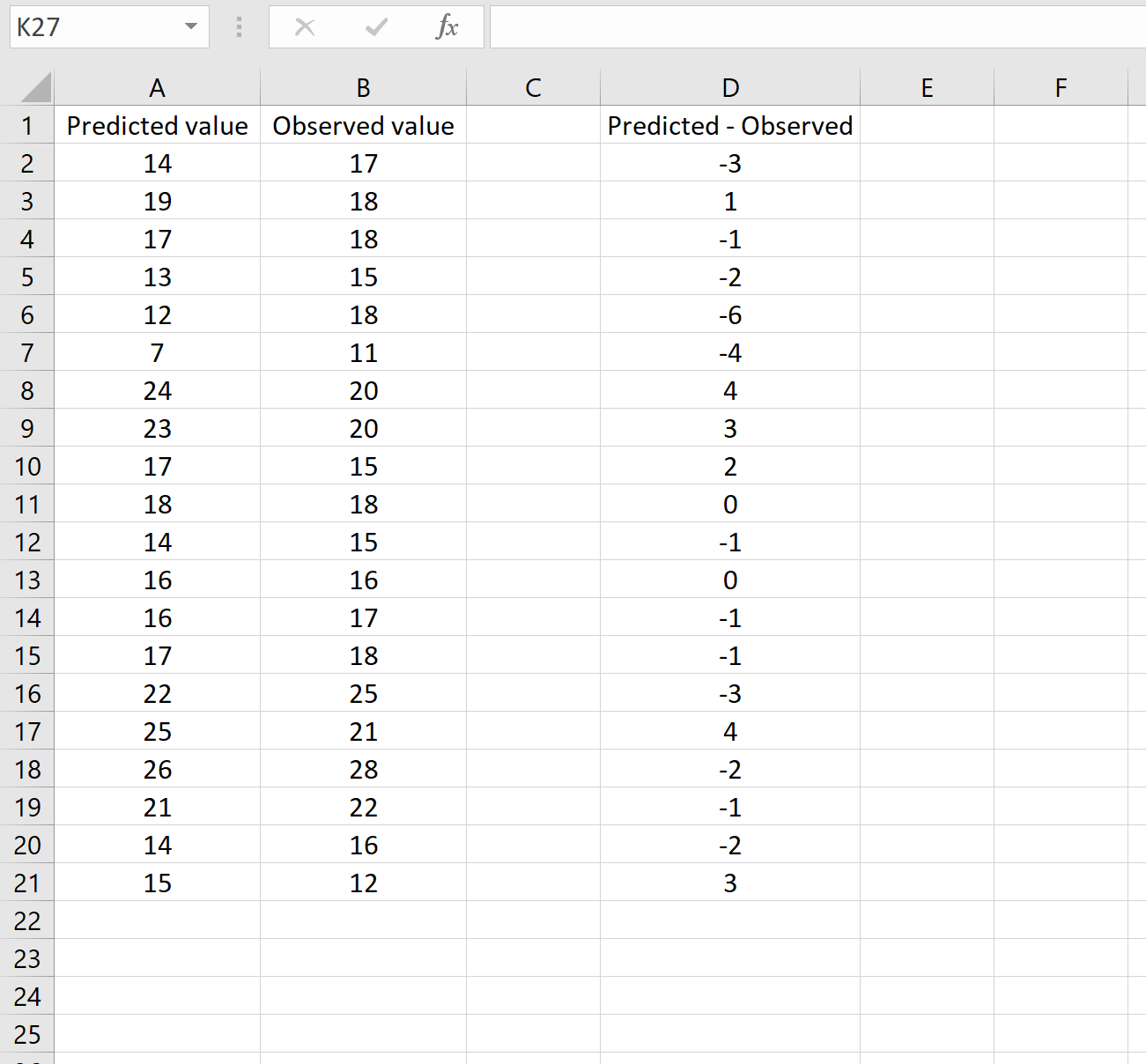
Wenn dies der Fall ist, können Sie den RMSE berechnen, indem Sie die folgende Formel in eine beliebige Zelle eingeben und dann auf STRG + UMSCHALT + EINGABETASTE klicken:
=WURZEL(QUADRATSUMME(D2:D21)/ANZAHL2(D2:D21))
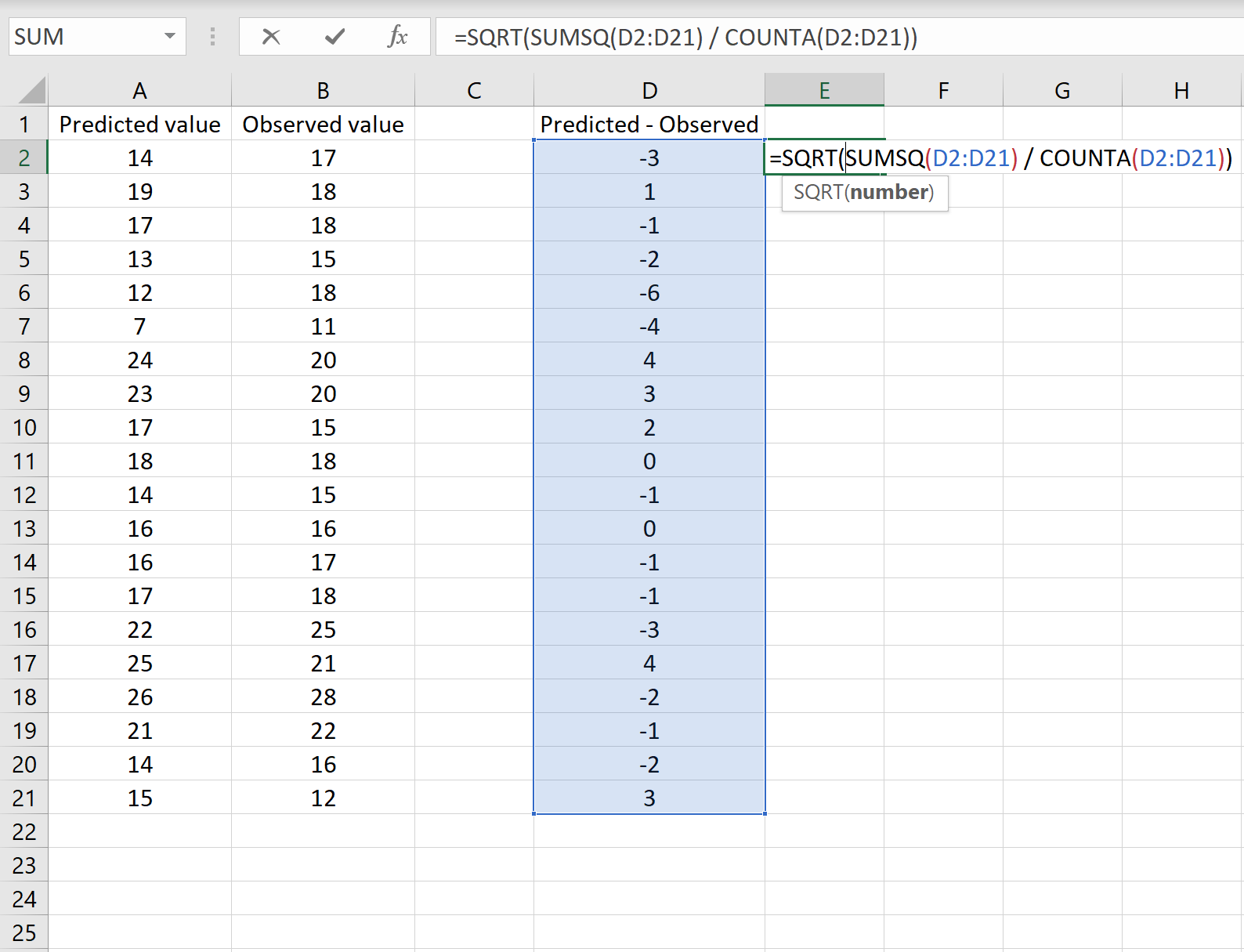
Dies sagt uns, dass der RMSE 2,6646 beträgt, was dem Ergebnis entspricht, das wir im ersten Szenario erhalten haben. Dies bestätigt, dass diese beiden Ansätze zur Berechnung des RMSE äquivalent sind.
Die in diesem Szenario verwendete Formel unterscheidet sich nur geringfügig von der im vorherigen Szenario verwendeten:
=WURZEL(QUADRATSUMME(D2: D21)/ANZAHL2(D2: D21))
Wie bereits erwähnt, ist RMSE eine nützliche Methode, um festzustellen, wie gut ein Regressionsmodell (oder ein Modell, das vorhergesagte Werte erzeugt) in der Lage ist, sich einen Datensatz „anzupassen“.
Je größer der RMSE ist, desto größer ist die Differenz zwischen den vorhergesagten und den beobachteten Werten, was bedeutet, dass das Regressionsmodell umso schlechter zu den Daten passt. Umgekehrt ist ein Modell umso besser in der Lage, die Daten anzupassen, je kleiner der RMSE ist.
Es kann besonders nützlich sein, den RMSE zweier verschiedener Modelle miteinander zu vergleichen, um festzustellen, welches Modell besser zu den Daten passt.
Weitere Tutorials in Excel finden Sie auf unserer Excel-Seite auf der alle unsere Excel-Tutorials aufgeführt sind.
Das Resampling von Zeitreihendaten bedeutet, die Daten für einen neuen Zeitraum zusammenzufassen oder zu aggregieren.
Wir können die folgende grundlegende Syntax verwenden, um Zeitreihendaten in Python neu abzutasten:
#Finde die …Ein rollierender Median ist der Median einer bestimmten Anzahl früherer Perioden in einer Zeitreihe.
Um den gleitenden Median für eine Spalte in einem Pandas DataFrame zu berechnen, können wir die …