
Eine einfaktorielle ANOVA wird verwendet, um zu bestimmen, ob es einen statistisch signifikanten Unterschied zwischen den Mittelwerten von drei oder mehr unabhängigen Gruppen gibt oder nicht.
Das folgende Beispiel bietet …
Eine ANOVA ist ein statistischer Test, mit dem festgestellt wird, ob zwischen den Mitteln von drei oder mehr unabhängigen Gruppen ein statistisch signifikanter Unterschied besteht oder nicht.
Die in einer ANOVA verwendeten Hypothesen lauten wie folgt:
Die Nullhypothese (H 0 ): µ 1 = µ 2 = µ 3 =… = µ k (die Mittelwerte sind für jede Gruppe gleich)
Die alternative Hypothese: (Ha): Mindestens einer der Mittelwerte unterscheidet sich von den anderen
Wenn der p-Wert aus der ANOVA kleiner als das Signifikanzniveau ist, können wir die Nullhypothese ablehnen und daraus schließen, dass wir genügend Beweise haben, um zu sagen, dass sich mindestens einer der Mittelwerte der Gruppen von den anderen unterscheidet.
Dies sagt uns jedoch nicht, welche Gruppen sich voneinander unterscheiden. Es sagt uns einfach, dass nicht alle Gruppenmittelwerte gleich sind.
Um genau herauszufinden, welche Gruppen sich voneinander unterscheiden, müssen wir einen Post-Hoc-Test durchführen, mit dem wir den Unterschied zwischen mehreren Gruppenmitteln untersuchen und gleichzeitig die Familie kontrollieren können. weise Fehlerrate.
Technischer Hinweis: Es ist wichtig zu beachten, dass wir nur dann einen Post-Hoc-Test durchführen müssen, wenn der p-Wert für die ANOVA statistisch signifikant ist. Wenn der p-Wert statistisch nicht signifikant ist, zeigt dies an, dass sich die Mittelwerte für alle Gruppen nicht voneinander unterscheiden, sodass kein Post-hoc-Test durchgeführt werden muss, um herauszufinden, welche Gruppen sich voneinander unterscheiden.
Wie bereits erwähnt, können wir mit Post-hoc-Tests den Unterschied zwischen mehreren Gruppenmitteln testen und gleichzeitig die familienbezogene Fehlerrate kontrollieren.
In einem Hypothesentest gibt es immer eine Fehlerrate vom Typ I, die durch unser Signifikanzniveau (Alpha) definiert wird und die Wahrscheinlichkeit angibt, eine tatsächlich zutreffende Nullhypothese abzulehnen. Mit anderen Worten, es ist die Wahrscheinlichkeit, ein „falsches Positiv“ zu erhalten,d.h.wenn wir behaupten, dass es einen statistisch signifikanten Unterschied zwischen den Gruppen gibt, aber tatsächlich keinen.
Wenn wir einen Hypothesentest durchführen, entspricht die Fehlerrate vom Typ I dem Signifikanzniveau, das üblicherweise mit 0,01, 0,05 oder 0,10 gewählt wird. Wenn wir jedoch mehrere Hypothesentests gleichzeitig durchführen, steigt die Wahrscheinlichkeit, ein falsches Positiv zu erhalten.
Stellen Sie sich zum Beispiel vor, wir würfeln mit 20 Seiten. Die Wahrscheinlichkeit, dass die Würfel auf einer „1“ landen, beträgt nur 5%. Wenn wir jedoch zwei Würfel gleichzeitig würfeln, steigt die Wahrscheinlichkeit, dass einer der Würfel auf einer „1“ landet, auf 9,75%. Wenn wir fünf Würfel gleichzeitig würfeln, steigt die Wahrscheinlichkeit auf 22,6%.
Je mehr Würfel wir werfen, desto höher ist die Wahrscheinlichkeit, dass einer der Würfel auf einer „1“ landet. Wenn wir mehrere Hypothesentests gleichzeitig mit einem Signifikanzniveau von 0,05 durchführen, steigt die Wahrscheinlichkeit, dass wir ein falsches Positiv erhalten, auf über 0,05.
Wenn wir eine ANOVA durchführen, gibt es oft drei oder mehr Gruppen, die wir miteinander vergleichen. Wenn wir also einen Post-hoc-Test durchführen, um den Unterschied zwischen den Gruppenmitteln zu untersuchen, gibt es mehrere paarweise Vergleiche, die wir untersuchen möchten. Angenommen, wir haben vier Gruppen: A, B, C und D. Dies bedeutet, dass es insgesamt sechs paarweise Vergleiche gibt, die wir mit einem Post-hoc-Test betrachten möchten:
A – B (die Differenz zwischen dem Mittelwert der Gruppe A und dem Mittelwert der Gruppe B)
A – C
A – D
B – C
B – D
C – D
Wenn wir mehr als vier Gruppen haben, wird die Anzahl der paarweisen Vergleiche, die wir betrachten möchten, nur noch weiter zunehmen. Die folgende Tabelle zeigt, wie viele paarweise Vergleiche mit jeder Anzahl von Gruppen zusammen mit der familienbezogenen Fehlerrate verknüpft sind:

Beachten Sie, dass die familienbezogene Fehlerrate mit zunehmender Anzahl von Gruppen (und folglich von Anzahl paarweiser Vergleiche) schnell zunimmt. Sobald wir sechs Gruppen erreicht haben, liegt die Wahrscheinlichkeit, dass wir ein falsches Positiv erhalten, tatsächlich über 50%!
Dies bedeutet, dass wir ernsthafte Zweifel an unseren Ergebnissen haben würden, wenn wir so viele paarweise Vergleiche anstellen würden, da wir wissen, dass unsere familienbezogene Fehlerrate so hoch war.
Glücklicherweise bieten uns Post-hoc-Tests die Möglichkeit, mehrere Vergleiche zwischen Gruppen durchzuführen und gleichzeitig die familienbezogene Fehlerrate zu kontrollieren.
Das folgende Beispiel zeigt, wie eine einfaktorielle ANOVA mit Post-Hoc-Tests durchgeführt wird.
Hinweis: In diesem Beispiel wird die Programmiersprache R verwendet, Sie müssen jedoch R nicht kennen, um die Testergebnisse oder die großen Erkenntnisse zu verstehen.
Zuerst erstellen wir einen Datensatz, der vier Gruppen (A, B, C, D) mit 20 Beobachtungen pro Gruppe enthält:
#Machen Sie dieses Beispiel reproduzierbar
set.seed(1)
# Tidyr- Bibliothek laden, um Daten vom Breit- in das Langformat zu konvertieren
library(tidyr)
# breites Dataset erstellen
data <- data.frame(A = runif(20, 2, 5),
B = runif(20, 3, 5),
C = runif(20, 3, 6),
D = runif(20, 4, 6))
#konvertieren in langen Datensatz für ANOVA
data_long <- gather(data, key = "group", value = "amount", A, B, C, D)
# Die ersten sechs Zeilen des Datensatzes anzeigen
head(data_long)
# group amount
#1 A 2.796526
#2 A 3.116372
#3 A 3.718560
#4 A 4.724623
#5 A 2.605046
#6 A 4.695169
Als Nächstes passen wir eine einfaktorielle ANOVA an den Datensatz an:
#Anova Modell anpassen
anova_model <- aov(amount ~ group, data = data_long)
#Zusammenfassung des Anova-Modells anzeigen
summary(anova_model)
# Df Sum Sq Mean Sq F value Pr(>F)
#group 3 25.37 8.458 17.66 8.53e-09 ***
#Residuals 76 36.39 0.479
Aus der Ausgabe der ANOVA-Tabelle geht hervor, dass die F-Statistik 17,66 beträgt und der entsprechende p-Wert extrem klein ist.
Dies bedeutet, dass wir genügend Beweise haben, um die Nullhypothese abzulehnen, dass alle Gruppenmittelwerte gleich sind. Als nächstes können wir einen Post-Hoc-Test verwenden, um herauszufinden, welche Gruppenmittelwerte sich voneinander unterscheiden.
Wir werden Beispiele für die folgenden Post-hoc-Tests durchgehen:
Tukey’s Test – nützlich, wenn Sie jeden möglichen paarweisen Vergleich durchführen möchten
Holm’s Methode – ein etwas konservativerer Test als der Tukey-Test
Dunnett’s Test – nützlich, wenn Sie jeden Gruppenmittelwert mit einem Kontrollmittelwert vergleichen möchten und nicht daran interessiert sind, die Behandlungsmittelwerte miteinander zu vergleichen.
Wir können den Tukey-Test für mehrere Vergleiche durchführen, indem wir die integrierte R-Funktion TukeyHSD() wie folgt verwenden:
#Tukey's Test für mehrere Vergleiche durchführen
TukeyHSD(anova_model, conf.level=.95)
# Tukey multiple comparisons of means
# 95% family-wise confidence level
#
#Fit: aov(formula = amount ~ group, data = data_long)
#
#$group
# diff lwr upr p adj
#B-A 0.2822630 -0.292540425 0.8570664 0.5721402
#C-A 0.8561388 0.281335427 1.4309423 0.0011117
#D-A 1.4676027 0.892799258 2.0424061 0.0000000
#C-B 0.5738759 -0.000927561 1.1486793 0.0505270
#D-B 1.1853397 0.610536271 1.7601431 0.0000041
#D-C 0.6114638 0.036660419 1.1862672 0.0326371
Beachten Sie, dass wir unser Konfidenzniveau auf 95% festgelegt haben, was bedeutet, dass unsere familienbezogene Fehlerrate 0,05 betragen soll. R gibt uns zwei Metriken, um jede paarweise Differenz zu vergleichen:
Sowohl das Konfidenzintervall als auch der p-Wert führen zu derselben Schlussfolgerung.
Beispielsweise beträgt das 95%-Konfidenzintervall für die mittlere Differenz zwischen Gruppe C und Gruppe A (0,2813, 1,4309), und da dieses Intervall keine Null enthält, wissen wir, dass die Differenz zwischen diesen beiden Gruppenmitteln statistisch signifikant ist. Insbesondere wissen wir, dass die Differenz positiv ist, da die Untergrenze des Konfidenzintervalls größer als Null ist.
Ebenso beträgt der p-Wert für die mittlere Differenz zwischen Gruppe C und Gruppe A 0,0011, was weniger als unser Signifikanzniveau von 0,05 ist, was auch darauf hinweist, dass die Differenz zwischen diesen beiden Gruppenmitteln statistisch signifikant ist.
Wir können auch die 95%-Konfidenzintervalle visualisieren, die sich aus dem Tukey-Test ergeben, indem wir die Funktion plot() in R verwenden:
plot(TukeyHSD(anova_model, conf.level=.95))
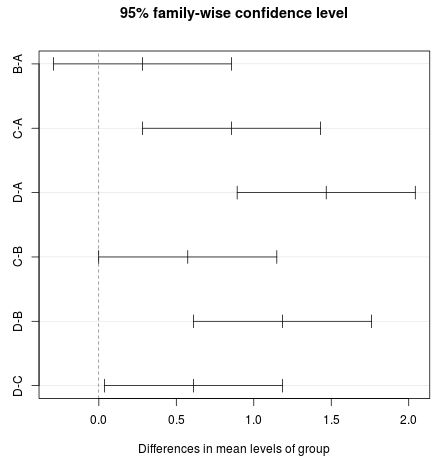
Wenn das Intervall Null enthält, wissen wir, dass der Unterschied im Gruppenmittelwerte statistisch nicht signifikant ist. Im obigen Beispiel sind die Unterschiede für B-A und C-B statistisch nicht signifikant, aber die Unterschiede für die anderen vier paarweisen Vergleiche sind statistisch signifikant.
Ein weiterer Post-Hoc-Test, den wir durchführen können, ist die Holm-Methode. Dies wird im Allgemeinen als konservativerer Test im Vergleich zum Tukey-Test angesehen.
Wir können den folgenden Code in R verwenden, um die Holm-Methode für mehrere paarweise Vergleiche durchzuführen:
#Führen Sie die Methode von Holm für mehrere Vergleiche durch
pairwise.t.test(data_long$amount, data_long$group, p.adjust="holm")
# Pairwise comparisons using t tests with pooled SD
#
#data: data_long$amount and data_long$group
#
# A B C
#B 0.20099 - -
#C 0.00079 0.02108 -
#D 1.9e-08 3.4e-06 0.01974
#
#P value adjustment method: holm
Dieser Test liefert ein Raster von p-Werten für jeden paarweisen Vergleich. Beispielsweise beträgt der p-Wert für die Differenz zwischen dem Mittelwert der Gruppe A und der Gruppe B 0,20099.
Wenn Sie die p-Werte dieses Tests mit den p-Werten aus Tukey’s Test vergleichen, werden Sie feststellen, dass jeder der paarweisen Vergleiche zu derselben Schlussfolgerung führt, mit Ausnahme des Unterschieds zwischen Gruppe C und D. Der p-Wert für Dieser Unterschied betrug im Tukey-Test 0,0505 im Vergleich zu 0,02108 in der Holm-Methode.
So Tukey-Test schlossen wir, dass der Unterschied zwischen Gruppe C und Gruppe D am .05 Signifikanzniveau war statistisch nicht signifikant, jedoch unter Verwendung von Holm Methode schlossen wir, dass der Unterschied zwischen Gruppe C und Gruppe D statistisch signifikant war.
Im Allgemeinen sind die nach der Holm-Methode erzeugten p-Werte tendenziell niedriger als die nach dem Tukey-Test erzeugten.
Eine weitere Methode, die wir für mehrere Vergleiche verwenden können, ist Dunett’s Test. Wir würden diesen Ansatz verwenden, wenn wir jeden Gruppenmittelwert mit einem Kontrollmittelwert vergleichen möchten, und wir sind nicht daran interessiert, die Behandlungsmittelwerte miteinander zu vergleichen.
Mit dem folgenden Code vergleichen wir beispielsweise die Gruppenmittelwerte von B, C und D mit denen der Gruppe A. Wir verwenden also Gruppe A als Kontrollgruppe und sind nicht an den Unterschieden zwischen den Gruppen B, C interessiert und D.
#Laden Sie die Multcomp-Bibliothek, die für die Verwendung von Dunnett's Test erforderlich ist
library(multcomp)
# Gruppenvariable in Faktor umwandeln
data_long$group <- as.factor(data_long$group)
#Anova Modell anpassen
anova_model <- aov(amount ~ group, data = data_long)
#Vergleiche durchführen
dunnet_comparison <- glht(anova_model, linfct = mcp(group = "Dunnett"))
#Zusammenfassung der Vergleiche anzeigen
summary(dunnet_comparison)
#Multiple Comparisons of Means: Dunnett Contrasts
#
#Fit: aov(formula = amount ~ group, data = data_long)
#
#Linear Hypotheses:
# Estimate Std. Error t value Pr(>|t|)
#B - A == 0 0.2823 0.2188 1.290 0.432445
#C - A == 0 0.8561 0.2188 3.912 0.000545 ***
#D - A == 0 1.4676 0.2188 6.707 < 1e-04 ***
Aus den p-Werten in der Ausgabe können wir Folgendes erkennen:
Wie bereits erwähnt, behandelt dieser Ansatz Gruppe A als „Kontrollgruppe“ und vergleicht einfach jeden anderen Gruppenmittelwert mit dem der Gruppe A. Beachten Sie, dass keine Tests für die Unterschiede zwischen den Gruppen B, C und D durchgeführt werden, da wir keine sind Ich bin nicht an den Unterschieden zwischen diesen Gruppen interessiert.
Post-hoc-Tests steuern die familienbezogene Fehlerrate hervorragend, haben jedoch den Nachteil, dass sie die statistische Aussagekraft der Vergleiche verringern. Dies liegt daran, dass die einzige Möglichkeit, die familienbezogene Fehlerrate zu senken, darin besteht, für alle Einzelvergleiche ein niedrigeres Signifikanzniveau zu verwenden.
Wenn wir beispielsweise den Tukey-Test für sechs paarweise Vergleiche verwenden und eine familienbezogene Fehlerrate von 0,05 beibehalten möchten, müssen wir für jedes einzelne Signifikanzniveau ein Signifikanzniveau von ungefähr 0,011 verwenden. Je mehr paarweise Vergleiche wir haben, desto niedriger ist das Signifikanzniveau, das wir für jedes einzelne Signifikanzniveau verwenden müssen.
Das Problem dabei ist, dass niedrigere Signifikanzniveaus einer geringeren statistischen Leistung entsprechen. Dies bedeutet, dass eine Studie mit geringerer Leistung dies weniger wahrscheinlich erkennt, wenn tatsächlich ein Unterschied zwischen Gruppenmitteln in der Bevölkerung besteht.
Eine Möglichkeit, die Auswirkungen dieses Kompromisses zu verringern, besteht darin, einfach die Anzahl der paarweisen Vergleiche zu verringern, die wir durchführen. In den vorherigen Beispielen haben wir beispielsweise sechs paarweise Vergleiche für die vier verschiedenen Gruppen durchgeführt. Abhängig von den Anforderungen Ihres Studiums sind Sie jedoch möglicherweise nur an wenigen Vergleichen interessiert.
Wenn Sie weniger Vergleiche anstellen, müssen Sie die statistische Leistung nicht so stark verringern.
Es ist wichtig zu beachten, dass Sie vor der Durchführung der ANOVA genau bestimmen sollten, zwischen welchen Gruppen Sie Vergleiche durchführen möchten und welchen Post-Hoc-Test Sie für diese Vergleiche verwenden werden. Wenn Sie lediglich sehen, welcher Post-Hoc-Test statistisch signifikante Ergebnisse liefert, verringert dies die Integrität der Studie.
In diesem Beitrag haben wir Folgendes gelernt:
Eine einfaktorielle ANOVA wird verwendet, um zu bestimmen, ob es einen statistisch signifikanten Unterschied zwischen den Mittelwerten von drei oder mehr unabhängigen Gruppen gibt oder nicht.
Das folgende Beispiel bietet …
Eine geschachtelte ANOVA ist eine Art ANOVA („Varianzanalyse“), bei der mindestens ein Faktor in einem anderen Faktor verschachtelt ist.
Nehmen wir zum Beispiel an, ein Forscher möchte wissen, ob drei …