
Sie können die folgende Formel verwenden, um eine Median-IF-Funktion in Google Tabellen auszuführen:
=MEDIAN(IF(GROUP_RANGE=VALUE, MEDIAN_RANGE))
Diese Formel findet den Mittelwert aller Zellen in einem bestimmten Bereich, die …
In Excel bieten Pivot-Tabellen eine einfache Möglichkeit, Daten zu gruppieren und zusammenzufassen.
Wenn wir beispielsweise den folgenden Datensatz in Excel haben, können wir eine Pivot-Tabelle verwenden, um den Gesamtumsatz schnell nach Region zusammenzufassen:
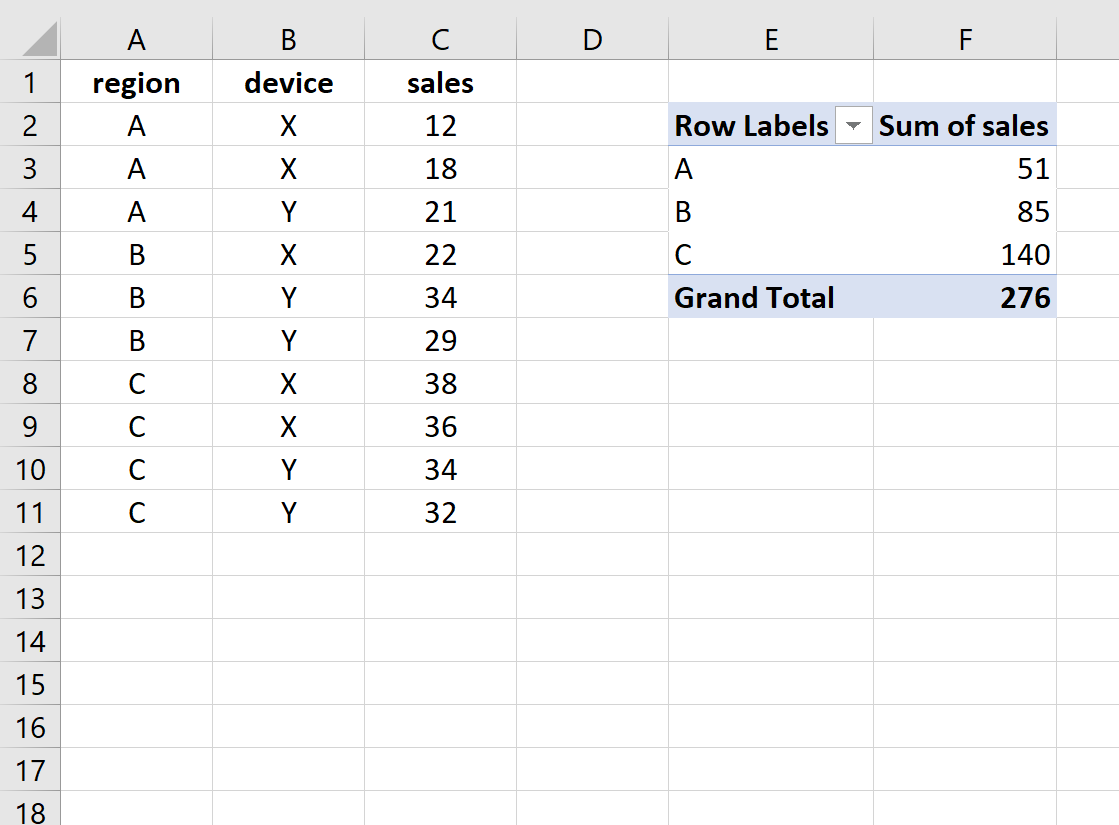
Dies sagt uns:
Oder wir könnten durch eine andere Metrik zusammenfassen, wie den durchschnittlichen Umsatz nach Region:

Es stellt sich heraus, dass wir schnell ähnliche Pivot-Tabellen in R unter Verwendung der group_by und summarize() mit dem dplyr-Paket erstellen können.
In diesem Tutorial finden Sie mehrere Beispiele dafür.
Lassen Sie uns zunächst denselben Datensatz in R erstellen, den wir in den vorherigen Beispielen aus Excel verwendet haben:
#Dataframe erstellen
df <- data.frame(region=c('A', 'A', 'A', 'B', 'B', 'B', 'C', 'C', 'C', 'C'),
device=c('X', 'X', 'Y', 'X', 'Y', 'Y', 'X', 'X', 'Y', 'Y'),
sales=c(12, 18, 21, 22, 34, 29, 38, 36, 34, 32))
#Dataframe anzeigen
df
region device sales
1 A X 12
2 A X 18
3 A Y 21
4 B X 22
5 B Y 34
6 B Y 29
7 C X 38
8 C X 36
9 C Y 34
10 C Y 32
Als nächstes laden wir die dplyr Paket und verwenden die group_by() und summarize() Funktionen, um nach Regionen zu gruppieren und die Summe der Umsätze nach Regionen zu finden:
library(dplyr)
#Umsatzsumme nach Region ermitteln
df %>%
group_by(region) %>%
summarize(sum_sales = sum(sales))
# A tibble: 3 x 2
region sum_sales
1 A 51
2 B 85
3 C 140
Wir können sehen, dass diese Zahlen mit den Zahlen im einführenden Excel-Beispiel übereinstimmen.
Wir können auch den durchschnittlichen Umsatz nach Regionen berechnen:
#Durchschnittsverkäufe nach Region ermitteln
df %>%
group_by(region) %>%
summarize(mean_sales = mean(sales))
# A tibble: 3 x 2
region mean_sales
1 A 17
2 B 28.3
3 C 35
Diese Zahlen stimmen wiederum mit den Zahlen aus dem Excel-Beispiel von vorhin überein.
Beachten Sie, dass wir auch nach mehreren Variablen gruppieren können. Zum Beispiel könnten wir die Summe der Verkäufe gruppiert nach Region und Gerätetyp ermitteln:
#Umsatzsumme nach Region und Gerätetyp ermitteln
df %>%
group_by(region, device) %>%
summarize(sum_sales = sum(sales))
# A tibble: 6 x 3
# Groups: region [3]
region device sum_sales
1 A X 30
2 A Y 21
3 B X 22
4 B Y 63
5 C X 74
6 C Y 66
So führen Sie einen SVERWEIS (ähnlich wie Excel) in R . durch
Die vollständige Anleitung: So gruppieren und fassen Sie Daten in R . zusammen
Sie können die folgende Formel verwenden, um eine Median-IF-Funktion in Google Tabellen auszuführen:
=MEDIAN(IF(GROUP_RANGE=VALUE, MEDIAN_RANGE))
Diese Formel findet den Mittelwert aller Zellen in einem bestimmten Bereich, die …
Die prozentuale Änderung der Werte zwischen einer Periode und einer anderen Periode wird wie folgt berechnet:
Prozentuale Änderung = (Wert 2 – Wert 1 ) / Wert 1 * 100
Angenommen, ein Unternehmen macht in …