
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
In der Statistik enthalten die Datensätze, mit denen wir arbeiten, häufig kategoriale Variablen.
Dies sind Variablen, die Namen oder Bezeichnungen annehmen. Beispiele beinhalten:
Beim Anpassen von Algorithmen für maschinelles Lernen (wie lineare Regression, logistische Regression, Random Forests usw.) konvertieren wir häufig kategoriale Variablen in Dummy-Variablen, bei denen es sich um numerische Variablen handelt, die zur Darstellung kategorialer Daten verwendet werden.
Angenommen, wir haben einen Datensatz, der die kategoriale Variable Geschlecht enthält. Um diese Variable als Prädiktor in einem Regressionsmodell zu verwenden, müssten wir sie zunächst in eine Dummy-Variable umwandeln.
Um diese Dummy-Variable zu erstellen, können wir einen der Werte („Männlich“) auswählen, um 0 darzustellen, und den anderen Wert („Weiblich“), um 1 darzustellen:
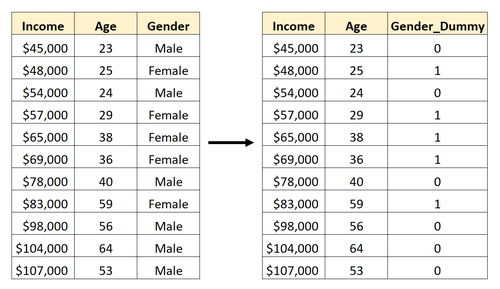
Um Dummy-Variablen für eine Variable in einem Pandas DataFrame zu erstellen, können wir die Funktion pandas.get_dummies() verwenden, die die folgende grundlegende Syntax verwendet:
pandas.get_dummies(Daten, Präfix=Keine, Spalten=Keine, drop_first=False)
wo:
Die folgenden Beispiele zeigen, wie Sie diese Funktion in der Praxis verwenden können.
Angenommen, wir haben den folgenden Pandas DataFrame:
import pandas as pd
#Dataframe erstellen
df = pd.DataFrame({'income': [45, 48, 54, 57, 65, 69, 78],
'age': [23, 25, 24, 29, 38, 36, 40],
'gender': ['M', 'F', 'M', 'F', 'F', 'F', 'M']})
#Dataframe anzeigen
df
income age gender
0 45 23 M
1 48 25 F
2 54 24 M
3 57 29 F
4 65 38 F
5 69 36 F
6 78 40 M
Wir können die Funktion pd.get_dummies() verwenden, um das Geschlecht in eine Dummy-Variable umzuwandeln:
#Konvertiere das Geschlecht in eine Dummy-Variable
pd.get_dummies(df, columns=['gender'], drop_first=True)
income age gender_M
0 45 23 1
1 48 25 0
2 54 24 1
3 57 29 0
4 65 38 0
5 69 36 0
6 78 40 1
Die Geschlechtsspalte ist jetzt eine Dummy-Variable, wobei:
Angenommen, wir haben den folgenden Pandas DataFrame:
pandas als pd importieren
#Dataframe erstellen
df = pd. DataFrame ({' Einkommen ': [45, 48, 54, 57, 65, 69, 78],
' Alter ': [23, 25, 24, 29, 38, 36, 40],
' Geschlecht ': ['M', 'F', 'M', 'F', 'F', 'F', 'M'],
' Hochschule ': ['Y', 'N', 'N', 'N', 'Y', 'Y', 'Y']})
#Dataframe anzeigen
df
income age gender college
0 45 23 M Y
1 48 25 F N
2 54 24 M N
3 57 29 F N
4 65 38 F Y
5 69 36 F Y
6 78 40 M Y
Wir können die Funktion pd.get_dummies() verwenden, um Geschlecht und Hochschule in Dummy-Variablen umzuwandeln:
#Konvertiere das Geschlecht in eine Dummy-Variable
pd.get_dummies(df, columns=['gender', 'college'], drop_first=True)
income age gender_M college_Y
0 45 23 1 1
1 48 25 0 0
2 54 24 1 0
3 57 29 0 0
4 65 38 0 1
5 69 36 0 1
6 78 40 1 1
Die Geschlechtsspalte ist jetzt eine Dummy-Variable, wobei:
Und die College-Spalte ist jetzt eine Dummy-Variable, in der:
So verwenden Sie Dummy-Variablen in der Regressionsanalyse
Was ist die Dummy-Variablenfalle?
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …