
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Die One-Hot-Kodierung wird verwendet, um kategoriale Variablen in ein Format zu konvertieren, das von maschinellen Lernalgorithmen problemlos verwendet werden kann.
Die Grundidee der One-Hot-Kodierung besteht darin, neue Variablen zu erstellen, die die Werte 0 und 1 annehmen, um die ursprünglichen kategorialen Werte darzustellen.
Das folgende Bild zeigt beispielsweise, wie wir eine One-Hot-Kodierung durchführen würden, um eine kategoriale Variable, die Teamnamen enthält, in neue Variablen zu konvertieren, die nur die Werte 0 und 1 enthalten:
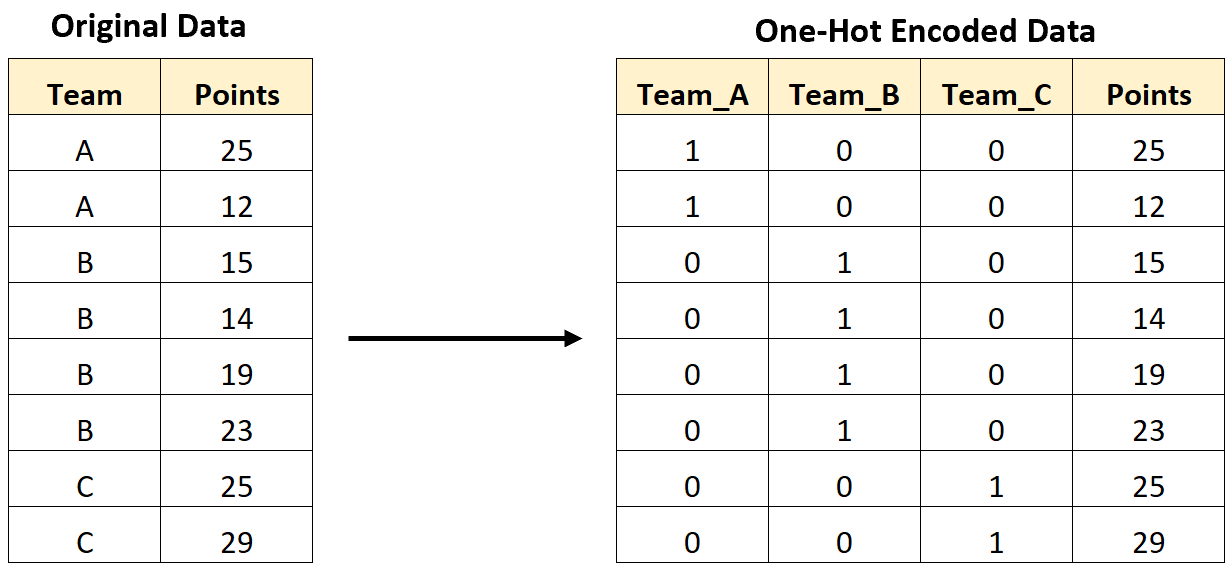
Das folgende Schritt-für-Schritt-Beispiel zeigt, wie Sie eine One-Hot-Kodierung für genau dieses Dataset in Python durchführen.
Lassen Sie uns zunächst den folgenden pandas DataFrame erstellen:
import pandas as pd
#Dataframe erstellen
df = pd.DataFrame({'team': ['A', 'A', 'B', 'B', 'B', 'B', 'C', 'C'],
'points': [25, 12, 15, 14, 19, 23, 25, 29]})
#Dataframe anzeigen
print(df)
team points
0 A 25
1 A 12
2 B 15
3 B 14
4 B 19
5 B 23
6 C 25
7 C 29
Als Nächstes importieren wir die Funktion OneHotEncoder() aus der sklearn -Bibliothek und verwenden sie, um eine One-Hot-Kodierung für die Variable „team“ im Pandas-DataFrame durchzuführen:
from sklearn.preprocessing import OneHotEncoder
#Instanz von One-Hot-Encoder erstellen
encoder = OneHotEncoder(handle_unknown='ignore')
# Führen Sie One-Hot-Kodierung in der Spalte „Team“ durch
encoder_df = pd.DataFrame(encoder.fit_transform(df[['team']]).toarray())
# One-Hot-codierte Spalten wieder mit dem ursprünglichen DataFrame zusammenführen
final_df = df.join(encoder_df)
#Dataframe anzeigen
print(final_df)
team points 0 1 2
0 A 25 1.0 0.0 0.0
1 A 12 1.0 0.0 0.0
2 B 15 0.0 1.0 0.0
3 B 14 0.0 1.0 0.0
4 B 19 0.0 1.0 0.0
5 B 23 0.0 1.0 0.0
6 C 25 0.0 0.0 1.0
7 C 29 0.0 0.0 1.0
Beachten Sie, dass dem DataFrame drei neue Spalten hinzugefügt wurden, da die ursprüngliche Spalte „Team“ drei eindeutige Werte enthielt.
Hinweis: Die vollständige Dokumentation für die OneHotEncoder()-Funktion finden Sie hier.
Schließlich können wir die ursprüngliche „Team“-Variable aus dem DataFrame löschen, da wir sie nicht mehr benötigen:
#Spalte „Team“ löschen
final_df.drop('team', axis=1, inplace=True)
#Dataframe anzeigen
print(final_df)
points 0 1 2
0 25 1.0 0.0 0.0
1 12 1.0 0.0 0.0
2 15 0.0 1.0 0.0
3 14 0.0 1.0 0.0
4 19 0.0 1.0 0.0
5 23 0.0 1.0 0.0
6 25 0.0 0.0 1.0
7 29 0.0 0.0 1.0
Verwandt: So löschen Sie die Indexspalte in Pandas (mit Beispielen)
Wir könnten auch die Spalten des endgültigen DataFrame umbenennen, um sie leichter lesbar zu machen:
#Spalten umbenennen
final_df.columns = ['points', 'teamA', 'teamB', 'teamC']
#Dataframe anzeigen
print(final_df)
points teamA teamB teamC
0 25 1.0 0.0 0.0
1 12 1.0 0.0 0.0
2 15 0.0 1.0 0.0
3 14 0.0 1.0 0.0
4 19 0.0 1.0 0.0
5 23 0.0 1.0 0.0
6 25 0.0 0.0 1.0
7 29 0.0 0.0 1.0
Die One-Hot-Kodierung ist abgeschlossen und wir können diesen Pandas DataFrame jetzt in jeden beliebigen maschinellen Lernalgorithmus einspeisen.
So führen Sie eine lineare Regression in Python durch
So führen Sie eine logistische Regression in Python durch
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …