
Ein Log-Log-Diagramm ist ein Diagramm, das sowohl auf der x-Achse als auch auf der y-Achse logarithmische Skalen verwendet.
Diese Art von Diagramm ist nützlich, um zwei Variablen zu visualisieren, wenn …
Oft möchten Sie vielleicht eine Kurve an einen Datensatz in Python anpassen.
Das folgende Schritt-für-Schritt-Beispiel erklärt, wie man in Python Kurven mit der Funktion numpy.polyfit() an Daten anpasst und wie man bestimmt, welche Kurve am besten zu den Daten passt.
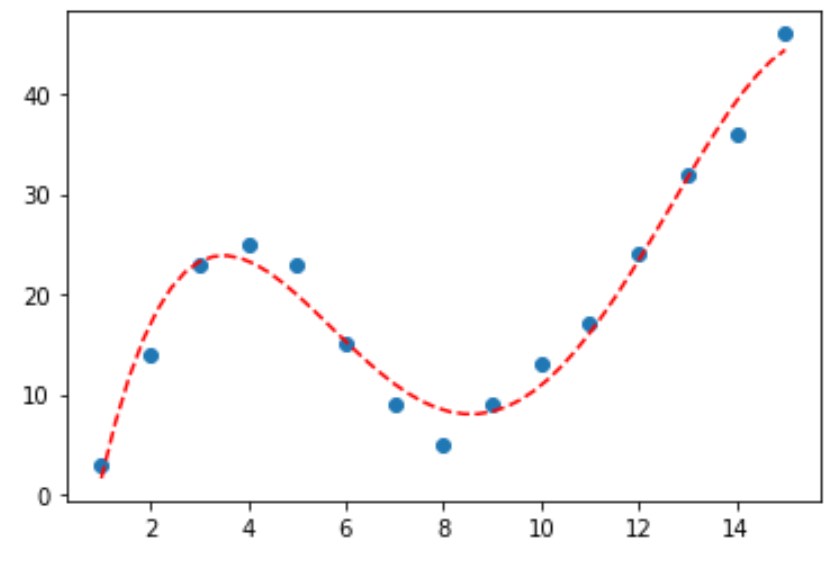
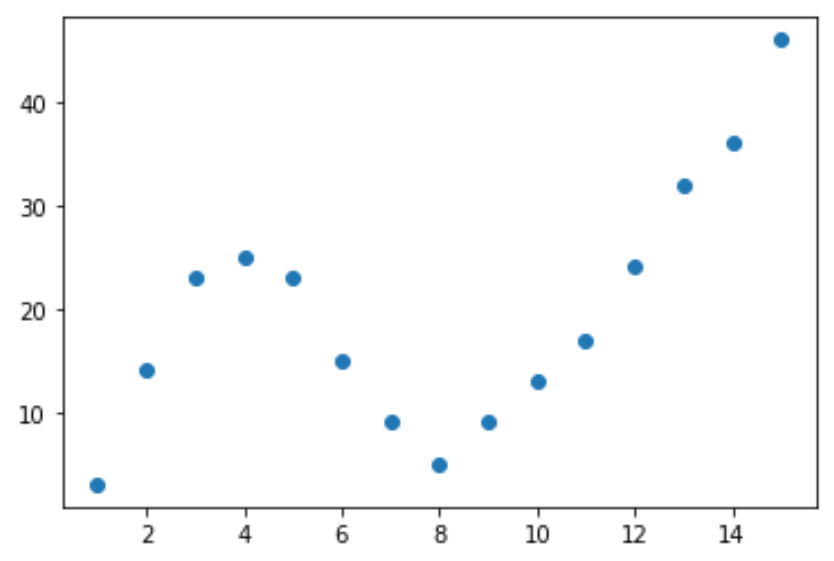
Lassen Sie uns zuerst einen gefälschten Datensatz erstellen und dann ein Streudiagramm erstellen, um die Daten zu visualisieren:
import pandas as pd
import matplotlib.pyplot as plt
#Dataframe erstellen
df = pd.DataFrame({'x': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15],
'y': [3, 14, 23, 25, 23, 15, 9, 5, 9, 13, 17, 24, 32, 36, 46]})
#Streudiagramm von x vs. y erstellen
plt.scatter(df.x, df.y)
Als Nächstes passen wir mehrere polynomiale Regressionsmodelle an die Daten an und visualisieren die Kurve jedes Modells im selben Diagramm:
import numpy as np
#Polynommodelle bis Grad 5 anpassen
model1 = np.poly1d(np.polyfit(df.x, df.y, 1))
model2 = np.poly1d(np.polyfit(df.x, df.y, 2))
model3 = np.poly1d(np.polyfit(df.x, df.y, 3))
model4 = np.poly1d(np.polyfit(df.x, df.y, 4))
model5 = np.poly1d(np.polyfit(df.x, df.y, 5))
#Streudiagramm erstellen
polyline = np.linspace(1, 15, 50)
plt.scatter(df.x, df.y)
#Hinzufügen angepasster Polynomlinien zum Streudiagramm
plt.plot(polyline, model1(polyline), color='green')
plt.plot(polyline, model2(polyline), color='red')
plt.plot(polyline, model3(polyline), color='purple')
plt.plot(polyline, model4(polyline), color='blue')
plt.plot(polyline, model5(polyline), color='orange')
plt.show()
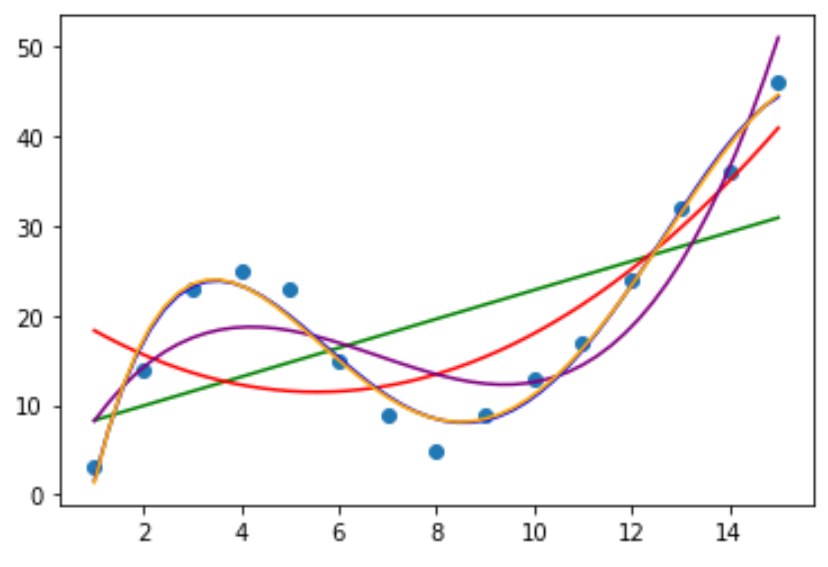
Um zu bestimmen, welche Kurve am besten zu den Daten passt, können wir uns das angepasste R-Quadrat jedes Modells ansehen.
Dieser Wert gibt uns den Prozentsatz der Variation in der Antwortvariablen an, der durch die Prädiktorvariablen im Modell erklärt werden kann, bereinigt um die Anzahl der Prädiktorvariablen.
#Funktion zur Berechnung des angepassten r-Quadrats definieren
def adjR(x, y, degree):
results = {}
coeffs = np.polyfit(x, y, degree)
p = np.poly1d(coeffs)
yhat = p(x)
ybar = np.sum(y)/len(y)
ssreg = np.sum((yhat-ybar)**2)
sstot = np.sum((y - ybar)**2)
results['r_squared'] = 1- (((1-(ssreg/sstot))*(len(y)-1))/(len(y)-degree-1))
return results
#berechnetes angepasstes R-Quadrat jedes Modells
adjR(df.x, df.y, 1)
adjR(df.x, df.y, 2)
adjR(df.x, df.y, 3)
adjR(df.x, df.y, 4)
adjR(df.x, df.y, 5)
{'r_squared': 0.3144819}
{'r_squared': 0.5186706}
{'r_squared': 0.7842864}
{'r_squared': 0.9590276}
{'r_squared': 0.9549709}
Aus der Ausgabe können wir ersehen, dass das Modell mit dem höchsten angepassten R-Quadrat das Polynom vierten Grades ist, das ein angepasstes R-Quadrat von 0,959 hat.
Schließlich können wir mit der Kurve des Polynommodells vierten Grades ein Streudiagramm erstellen:
#Polynom vierten Grades anpassen
model4 = np.poly1d(np.polyfit(df.x, df.y, 4))
#Streudiagramm definieren
polyline = np.linspace(1, 15, 50)
plt.scatter(df.x, df.y)
#Hinzufügen einer angepassten Polynomkurve zum Streudiagramm
plt.plot(polyline, model4(polyline), '--', color='red')
plt.show()
Wir können die Gleichung für diese Zeile auch mit der Funktion print() erhalten:
print(model4)
4 3 2
-0.01924 x + 0.7081 x - 8.365 x + 35.82 x - 26.52
Die Kurvengleichung lautet wie folgt:
y = -0,01924 x 4 + 0,7081 x 3 – 8,365 x 2 + 35,82 x – 26,52
Wir können diese Gleichung verwenden, um den Wert der Antwortvariablen basierend auf den Prädiktorvariablen im Modell vorherzusagen. Wenn zum Beispiel x = 4 ist, würden wir vorhersagen, dass y = 23,32:
y = -0,0192(4) 4 + 0,7081(4) 3 – 8,365(4) 2 + 35,82(4) – 26,52 = 23,32
Eine Einführung in die polynomiale Regression So führen Sie eine polynomiale Regression in Python durch
Ein Log-Log-Diagramm ist ein Diagramm, das sowohl auf der x-Achse als auch auf der y-Achse logarithmische Skalen verwendet.
Diese Art von Diagramm ist nützlich, um zwei Variablen zu visualisieren, wenn …
Bei der Verwendung von Klassifizierungsmodellen beim maschinellen Lernen verwenden wir häufig zwei Metriken, um die Qualität des Modells zu bewerten, nämlich Präzision und Erinnerung.
Precision: Korrigieren Sie positive Vorhersagen im …