
Eine einfaktorielle ANOVA wird verwendet, um zu bestimmen, ob es einen statistisch signifikanten Unterschied zwischen den Mittelwerten von drei oder mehr unabhängigen Gruppen gibt oder nicht.
Das folgende Beispiel bietet …
Ein Kruskal-Wallis-Test wird verwendet, um festzustellen, ob es einen statistisch signifikanten Unterschied zwischen den Medianwerten von drei oder mehr unabhängigen Gruppen gibt oder nicht. Dieser Test ist das nichtparametrische Äquivalent der einfaktorielle ANOVA und wird normalerweise verwendet, wenn die Annahme der Normalverteilung verletzt wird.
Der Kruskal-Wallis-Test geht nicht von einer Normalverteilung der Daten aus und ist gegenüber Ausreißern viel weniger empfindlich als die einfaktorielle ANOVA.
Das folgende Beispiel zeigt, wie ein Kruskal-Wallis-Test in R durchgeführt wird.
Ein Forscher möchte wissen, ob drei Medikamente unterschiedliche Auswirkungen auf Rückenschmerzen haben oder nicht. Er rekrutiert 30 Personen, die alle ähnliche Rückenschmerzen haben, und teilt sie nach dem Zufallsprinzip in drei Gruppen auf, um entweder Medikament A, Medikament B oder Medikament C zu erhalten Einen Monat nach Einnahme des Arzneimittels bittet der Forscher jede Person, ihre Rückenschmerzen auf einer Skala von 1 bis 100 zu bewerten, wobei 100 die stärksten Schmerzen anzeigt.
Der Forscher führt einen Kruskal-Wallis-Test mit einem Signifikanzniveau von 0,05 durch, um festzustellen, ob zwischen diesen drei Gruppen ein statistisch signifikanter Unterschied zwischen den mittleren Bewertungen für Rückenschmerzen besteht.
Der folgende Code erstellt das Dataframe, mit dem wir arbeiten werden:
#Machen Sie dieses Beispiel reproduzierbar
set.seed(0)
#Dataframe erstellen
data <- data.frame(drug = rep(c("A", "B", "C"), each = 10),
pain = c(runif(10, 40, 60),
runif(10, 45, 65),
runif(10, 55, 70)))
#Die ersten sechs Zeilen des Dataframes anzeigen
head(data)
# drug pain
#1 A 57.93394
#2 A 45.31017
#3 A 47.44248
#4 A 51.45707
#5 A 58.16416
#6 A 44.03364
Die erste Spalte im Dataframe zeigt das Medikament, das die Person einen Monat lang eingenommen hat, und die zweite Spalte zeigt die gemeldeten Rückenschmerzen nach einem Monat auf einer Skala von 0 bis 100.
Bevor wir den Kruskal-Wallis-Test durchführen, können wir die Daten besser verstehen, indem wir den Mittelwert und die Standardabweichung der Rückenschmerzen für jedes Medikament mithilfe des dplyr-Pakets ermitteln:
#dplyr laden
library(dplyr)
# Mittelwert und Standardabweichung der gemeldeten Rückenschmerzen für jede Arzneimittelgruppe ermitteln
data %>%
group_by(drug) %>%
summarise(mean = mean(pain),
sd = sd(pain))
# A tibble: 3 x 3
# drug mean sd
#
#1 A 52.7 5.60
#2 B 54.7 5.99
#3 C 61.9 4.88
Wir können auch ein Boxplot für jedes der drei Medikamente erstellen, um die Verteilung der Rückenschmerzen für jede Gruppe zu visualisieren:
#Boxplots erstellen
boxplot(pain ~ drug,
data = data,
main = "Reported Pain by Drug",
xlab = "Drug",
ylab = "Reported Pain",
col = "steelblue",
border = "black")
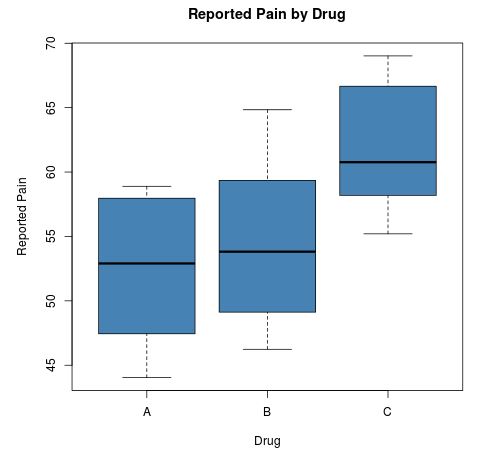
Nur anhand dieser Boxplots können wir sehen, dass der mittlere gemeldete Schmerz für die Teilnehmer, die Medikament C verwendet haben, am höchsten ist. Wir können auch sehen, dass die Standardabweichung (die „Länge“ des Boxplots) für den gemeldeten Schmerz unter den Teilnehmern, die Schmerz gemeldet haben, etwas höher ist verwendetes Medikament A oder Medikament B im Vergleich zu denen, die Medikament C verwendet haben.
Als nächstes führen wir den Kruskal-Wallis-Test durch, um festzustellen, ob diese visuellen Unterschiede tatsächlich statistisch signifikant sind.
Die allgemeine Syntax zur Durchführung eines Kruskal-Wallis-Tests in R lautet wie folgt:
kruskal.test(response variable ~ predictor variable, data = dataset)
In unserem Beispiel können wir den folgenden Code verwenden, um den Kruskal-Wallist-Test durchzuführen, wobei Schmerz als Antwortvariable und Medikament als Prädiktorvariable verwendet werden:
kruskal.test(pain ~ drug, data = data)
# Kruskal-Wallis rank sum test
#
#data: pain by drug
#Kruskal-Wallis chi-squared = 11.105, df = 2, p-value = 0.003879
Aus der Ausgabe können wir ersehen, dass die Chi-Quadrat-Teststatistik 11,105 und der entsprechende p-Wert 0,003879 beträgt. Da dieser p-Wert unter dem Signifikanzniveau von 0,05 liegt, gibt es einen statistisch signifikanten Unterschied zwischen den angegebenen Schmerzniveaus zwischen den drei Arzneimitteln.
Sobald wir festgestellt haben, dass es einen statistisch signifikanten Unterschied zwischen den gemeldeten Schmerzniveaus für die drei Medikamente gibt, können wir einen Post-hoc-Test durchführen, um genau zu bestimmen, welche Behandlungsgruppen sich voneinander unterscheiden.
Für unseren Post-hoc-Test verwenden wir die Funktion pairwise.wilcox.test(), um paarweise Vergleiche zwischen den Gruppen mit der folgenden Syntax zu berechnen:
pairwise.wilcox.test(response variable ~ predictor variable, p.adjust.method)
Der folgende Code veranschaulicht, wie diese Funktion auf unsere Daten angewendet wird:
pairwise.wilcox.test(data$pain, data$drug, p.adjust.method = "BH")
# Pairwise comparisons using Wilcoxon rank sum test
#
#data: data$pain and data$drug
#
# A B
#B 0.3527 -
#C 0.0032 0.0220
#
#P value adjustment method: BH
Die paarweisen Vergleiche zeigen, dass der Unterschied zwischen den angegebenen Schmerzniveaus für Arzneimittel A und Arzneimittel C statistisch signifikant ist (p-Wert = 0,0032 ) und der Unterschied zwischen den angegebenen Schmerzniveaus für Arzneimittel B und Arzneimittel C statistisch signifikant ist (p-Wert) = 0,0220 ).
Diese Ergebnisse stimmen mit den Ergebnissen der Boxplots überein. Wir haben gesehen, dass die gemeldeten Schmerzniveaus für Teilnehmer an Medikament C im Vergleich zu Medikament A und Medikament B deutlich höher waren und dass es nur einen subtilen Unterschied zwischen Medikament A und Medikament B gab.
Den vollständigen Code für diese Analyse finden Sie hier:
#Machen Sie dieses Beispiel reproduzierbar
set.seed (0)
#Dataframe erstellen
data <- data.frame(drug = rep(c("A", "B", "C"), each = 10),
pain = c(runif(10, 40, 60),
runif(10, 45, 65),
runif(10, 55, 70)))
# Die ersten sechs Zeilen des Dataframes anzeigen
head(data)
#load dplyr library
library(dplyr)
# Mittelwert und Standardabweichung der gemeldeten Rückenschmerzen für jede Arzneimittelgruppe ermitteln
data %>%
group_by(drug) %>%
summarise(mean = mean(pain),
sd = sd(pain))
# Daten visualisieren
boxplot(pain ~ drug,
data = data,
main = "Reported Pain by Drug",
xlab = "Drug",
ylab = "Reported Pain",
col = "steelblue",
border = "black")
#Kruskal-Wallis-Test durchführen
kruskal.test(pain ~ drug, data = data)
# Post-hoc-Test für paarweise Vergleiche durchführen
pairwise.wilcox.test(data$pain, data$drug, p.adjust.method = "BH")
Weiterführende Literatur:
Eine Einführung in den Kruskal-Wallis-Test
Eine einfaktorielle ANOVA wird verwendet, um zu bestimmen, ob es einen statistisch signifikanten Unterschied zwischen den Mittelwerten von drei oder mehr unabhängigen Gruppen gibt oder nicht.
Das folgende Beispiel bietet …
Eine geschachtelte ANOVA ist eine Art ANOVA („Varianzanalyse“), bei der mindestens ein Faktor in einem anderen Faktor verschachtelt ist.
Nehmen wir zum Beispiel an, ein Forscher möchte wissen, ob drei …