
Sie können die folgende Formel verwenden, um eine Median-IF-Funktion in Google Tabellen auszuführen:
=MEDIAN(IF(GROUP_RANGE=VALUE, MEDIAN_RANGE))
Diese Formel findet den Mittelwert aller Zellen in einem bestimmten Bereich, die …
Der Iris-Datensatz ist ein in R integrierter Datensatz, der Messungen zu 4 verschiedenen Attributen (in Zentimetern) für 50 Blumen von 3 verschiedenen Arten enthält.
In diesem Tutorial wird erläutert, wie Sie ein Dataset in R untersuchen und zusammenfassen, wobei das Iris-Dataset als Beispiel dient.
Da es sich beim Iris-Dataset um ein integriertes Dataset in R handelt, können wir es mit dem folgenden Befehl laden:
data(iris)
Wir können uns die ersten sechs Zeilen des Datensatzes mit der Funktion head() ansehen:
#erste sechs Zeilen des Iris-Datasets anzeigen
head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
Wir können die Funktion summary() verwenden, um jede Variable im Datensatz schnell zusammenzufassen:
#Iris-Datensatz zusammenfassen
summary(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
Median :5.800 Median :3.000 Median :4.350 Median :1.300
Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
Species
setosa :50
versicolor:50
virginica :50
Für jede der numerischen Variablen können wir die folgenden Informationen sehen:
Für die einzige kategoriale Variable im Datensatz (Spezies) sehen wir eine Häufigkeitszählung für jeden Wert:
Wir können die Funktion dim() verwenden, um die Dimensionen des Datensatzes in Bezug auf die Anzahl der Zeilen und die Anzahl der Spalten zu erhalten:
#Zeilen und Spalten anzeigen
dim(iris)
[1] 150 5
Wir können sehen, dass der Datensatz 150 Zeilen und 5 Spalten hat.
Wir können auch die Funktion names() verwenden, um die Spaltennamen des Dataframes anzuzeigen:
#Spaltennamen anzeigen
names(iris)
[1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"
Wir können auch einige Diagramme erstellen, um die Werte im Datensatz zu visualisieren.
Zum Beispiel können wir die Funktion hist() verwenden, um ein Histogramm der Werte für eine bestimmte Variable zu erstellen:
#Erzeuge ein Histogramm von Werten für die Kelchblattlänge
hist(iris$Sepal.Length,
col='steelblue',
main='Histogram',
xlab='Length',
ylab='Frequency')
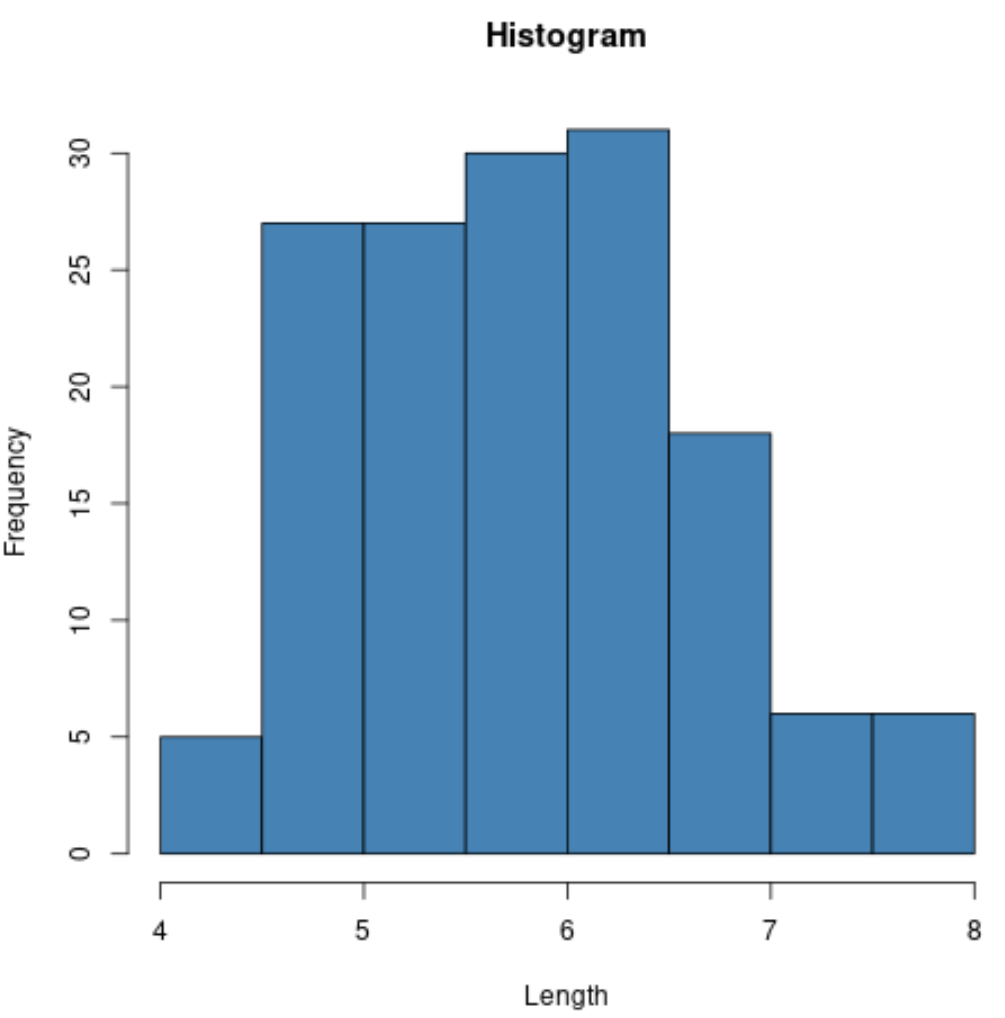
Wir können auch die Funktion plot() verwenden, um ein Streudiagramm einer beliebigen paarweisen Kombination von Variablen zu erstellen:
#Erzeuge Streudiagramm der Kelchblattbreite vs. Kelchblattlänge
plot(iris$Sepal.Width, iris$Sepal.Length,
col='steelblue',
main='Scatterplot',
xlab='Sepal Width',
ylab='Sepal Length',
pch=19)
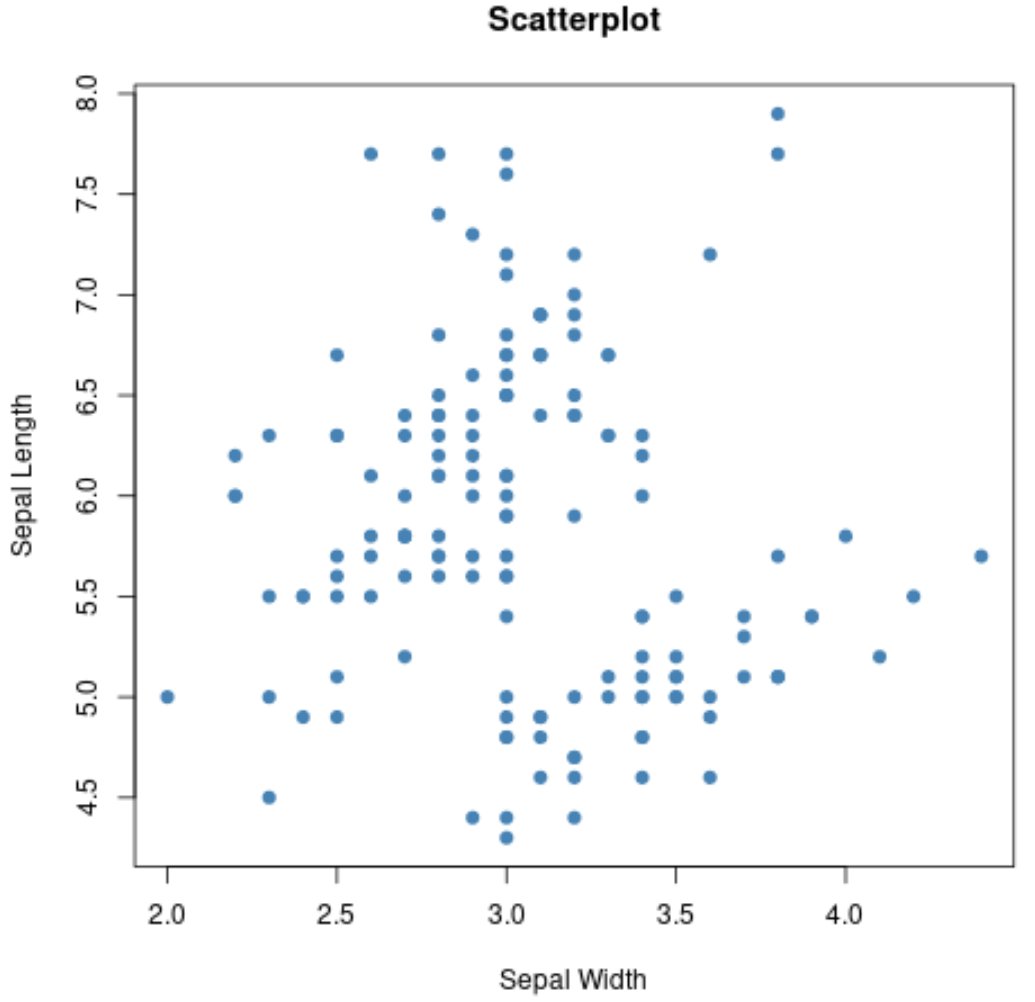
Wir können auch die Funktion boxplot() verwenden, um einen Boxplot nach Gruppe zu erstellen:
#Erzeuge Streudiagramm der Kelchblattbreite vs. Kelchblattlänge
boxplot(Sepal.Length~Species,
data=iris,
main='Sepal Length by Species',
xlab='Species',
ylab='Sepal Length',
col='steelblue',
border='black')
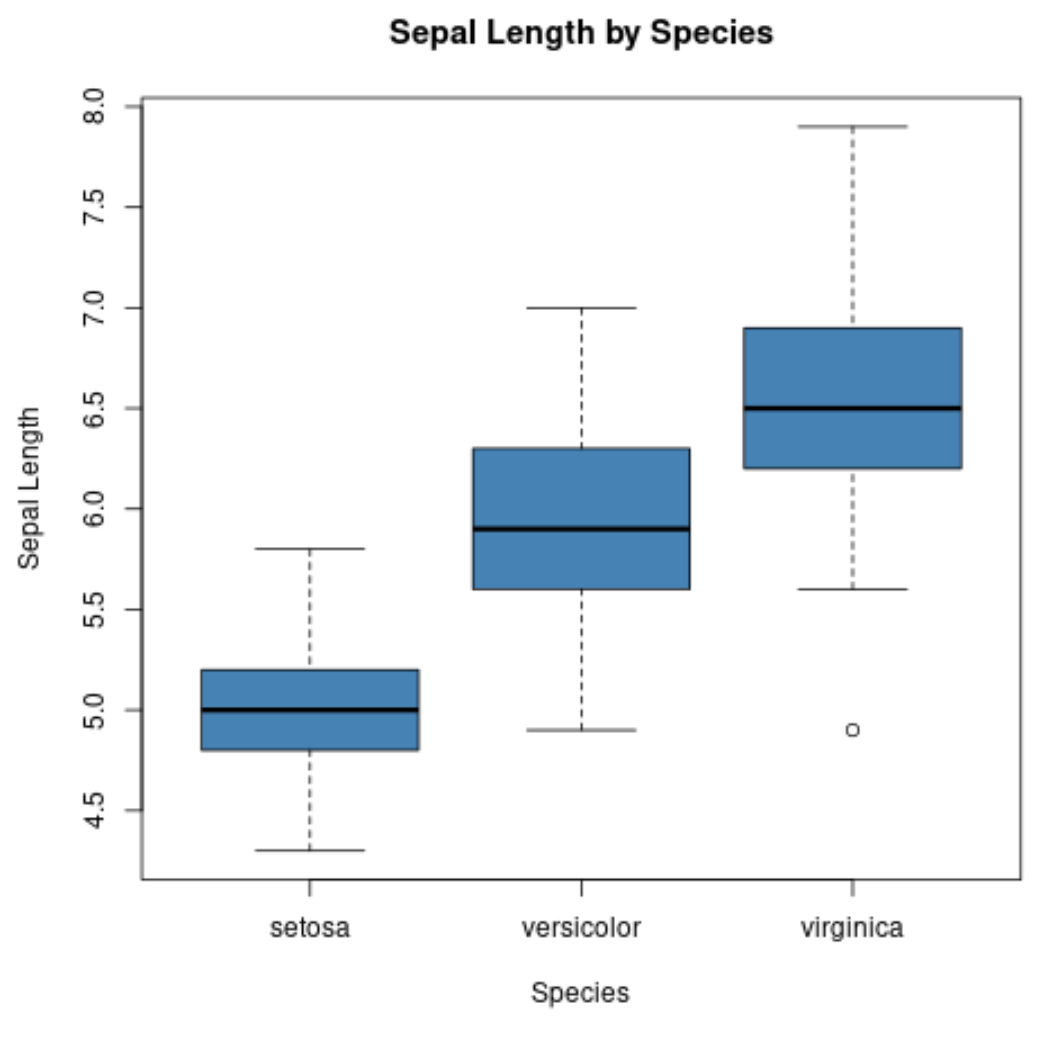
Die x-Achse zeigt die drei Arten und die y-Achse zeigt die Verteilung der Werte für die Kelchblattlänge für jede Art.
Diese Art der Darstellung lässt uns schnell erkennen, dass die Kelchblattlänge bei den Virginica-Arten am größten und bei den Setosa-Arten am kleinsten ist.
Sie können die folgende Formel verwenden, um eine Median-IF-Funktion in Google Tabellen auszuführen:
=MEDIAN(IF(GROUP_RANGE=VALUE, MEDIAN_RANGE))
Diese Formel findet den Mittelwert aller Zellen in einem bestimmten Bereich, die …
Die prozentuale Änderung der Werte zwischen einer Periode und einer anderen Periode wird wie folgt berechnet:
Prozentuale Änderung = (Wert 2 – Wert 1 ) / Wert 1 * 100
Angenommen, ein Unternehmen macht in …