
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
In der Statistik ist die Regression eine Technik, mit der die Beziehung zwischen Prädiktorvariablen und einer Antwortvariablen analysiert werden kann.
Wenn Sie eine Regressionsanalyse mit Software (wie R, SAS, SPSS usw.) durchführen, erhalten Sie als Ausgabe eine Regressionstabelle, in der die Ergebnisse der Regression zusammengefasst sind. Es ist wichtig zu wissen, wie diese Tabelle zu lesen ist, damit Sie die Ergebnisse der Regressionsanalyse verstehen können.
Dieses Tutorial führt Sie durch ein Beispiel einer Regressionsanalyse und bietet eine ausführliche Erklärung zum Lesen und Interpretieren der Ausgabe einer Regressionstabelle.
Angenommen, wir haben den folgenden Datensatz, der die Gesamtzahl der untersuchten Stunden, die Gesamtzahl der absolvierten Vorbereitungsprüfungen und die Punktzahl der Abschlussprüfung für 12 verschiedene Schüler zeigt:
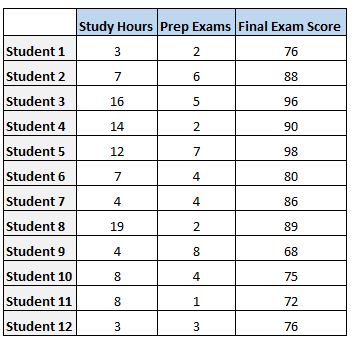
Um die Beziehung zwischen den untersuchten Stunden und den vorbereiteten Prüfungen mit dem endgültigen Prüfungsergebnis eines Schülers zu analysieren, führen wir eine multiple lineare Regression durch, wobei hours studied und prep exams taken als Prädiktorvariablen und das final exam score als Antwortvariable verwendet werden.
Wir erhalten folgende Ausgabe:
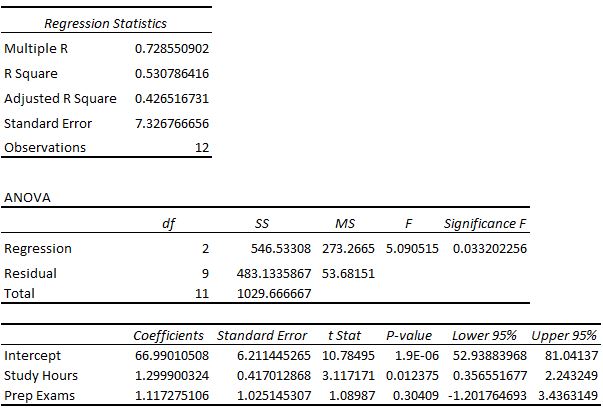
Der erste Abschnitt zeigt verschiedene Zahlen, die die Anpassung des Regressionsmodells messen.
So interpretieren Sie die einzelnen Zahlen in diesem Abschnitt:
Dies ist der Korrelationskoeffizient. Es misst die Stärke der linearen Beziehung zwischen den Prädiktorvariablen und der Antwortvariablen. Ein Vielfaches R von 1 zeigt eine perfekte lineare Beziehung an, während ein Vielfaches R von 0 überhaupt keine lineare Beziehung anzeigt. Das multiple R ist die Quadratwurzel des R-Quadrats (siehe unten).
In diesem Beispiel beträgt Multiple R 0,72855, was auf eine ziemlich starke lineare Beziehung zwischen den Prädiktoren hours studied und den prep exams und der Antwortvariablen final exam score hinweist.
Dies wird oft als r2 geschrieben und ist auch als Bestimmungskoeffizient bekannt. Es ist der Anteil der Varianz in der Antwortvariablen, der durch die Prädiktorvariable erklärt werden kann.
Der Wert für das R-Quadrat kann im Bereich von 0 bis 1 liegen. Ein Wert von 0 zeigt an, dass die Antwortvariable überhaupt nicht durch die Prädiktorvariable erklärt werden kann. Ein Wert von 1 gibt an, dass die Antwortvariable durch die Prädiktorvariable perfekt erklärt werden kann.
In diesem Beispiel beträgt das R-Quadrat 0,5307, was darauf hinweist, dass 53,07% der Varianz in den endgültigen Prüfungsergebnissen durch die Anzahl der untersuchten Stunden und die Anzahl der absolvierten Vorbereitungsprüfungen erklärt werden können.
Verwandt: Was ist ein guter R-Quadrat-Wert?
Dies ist eine modifizierte Version des R-Quadrats, die an die Anzahl der Prädiktoren im Modell angepasst wurde. Es ist immer niedriger als das R-Quadrat. Das adjustierte R-Quadrat kann nützlich sein, um die Anpassung verschiedener Regressionsmodelle miteinander zu vergleichen.
In diesem Beispiel beträgt das adjustierte R-Quadrat 0,4265.
Der Standardfehler der Regression ist der durchschnittliche Abstand, um den die beobachteten Werte von der Regressionslinie fallen. In diesem Beispiel fallen die beobachteten Werte durchschnittlich um 7,3267 Einheiten von der Regressionslinie ab.
Verwandt: Grundlegendes zum Standardfehler der Regression
Dies ist einfach die Anzahl der Beobachtungen in unserem Datensatz. In diesem Beispiel beträgt die Anzahl aller Beobachtungen 12.
Der nächste Abschnitt zeigt die Freiheitsgrade, die Summe der Quadrate, die mittleren Quadrate, die F-Statistik und die Gesamtbedeutung des Regressionsmodells.
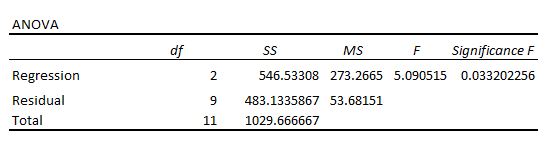
So interpretieren Sie die einzelnen Zahlen in diesem Abschnitt:
Diese Zahl ist gleich: die Anzahl der Regressionskoeffizienten – 1. In diesem Beispiel haben wir einen Intercept-Term und zwei Prädiktorvariablen, also haben wir insgesamt drei Regressionskoeffizienten, was bedeutet, dass die Regressionsfreiheitsgrade 3 – 1 = 2 sind.
Diese Anzahl ist gleich: die Anzahl der Beobachtungen – 1. In diesem Beispiel haben wir 12 Beobachtungen, sodass die Gesamtfreiheitsgrade 12 – 1 = 11 betragen.
Diese Zahl ist gleich: total df – Regression df. In diesem Beispiel betragen die verbleibenden Freiheitsgrade 11 – 2 = 9.
Die mittleren Regressionsquadrate werden durch Regression SS / Regression df berechnet. In diesem Beispiel ist die Regression MS = 546,53308 / 2 = 273,2665.
Die verbleibenden mittleren Quadrate werden durch die verbleibenden SS / verbleibenden df berechnet. In diesem Beispiel ist die verbleibende MS = 483,1335 / 9 = 53,68151.
Die f-Statistik wird als Regressions-MS / Reisdual-MS berechnet. Diese Statistik gibt an, ob das Regressionsmodell besser zu den Daten passt als ein Modell, das keine unabhängigen Variablen enthält.
Im Wesentlichen wird geprüft, ob das Regressionsmodell insgesamt nützlich ist. Wenn keine der Prädiktorvariablen im Modell statistisch signifikant ist, ist die F-Gesamtstatistik im Allgemeinen auch statistisch nicht signifikant.
In diesem Beispiel lautet die F-Statistik 273,2665 / 53,68151 = 5,09.
Der letzte Wert in der Tabelle ist der p-Wert, der der F-Statistik zugeordnet ist. Um festzustellen, ob das gesamte Regressionsmodell signifikant ist, können Sie den p-Wert mit einem Signifikanzniveau vergleichen. Übliche Optionen sind .01, .05 und .10.
Wenn der p-Wert unter dem Signifikanzniveau liegt, gibt es genügend Anhaltspunkte dafür, dass das Regressionsmodell besser zu den Daten passt als das Modell ohne Prädiktorvariablen. Dieser Befund ist gut, da dies bedeutet, dass die Prädiktorvariablen im Modell tatsächlich die Anpassung des Modells verbessern.
In diesem Beispiel beträgt der p-Wert 0,033, was weniger als das übliche Signifikanzniveau von 0,05 ist. Dies zeigt an, dass das Regressionsmodell insgesamt statistisch signifikant ist,d.h.das Modell passt besser zu den Daten als das Modell ohne Prädiktorvariablen.
Der letzte Abschnitt zeigt die Koeffizientenschätzungen, den Standardfehler der Schätzungen, die t-stat-, p-Werte und Konfidenzintervalle für jeden Term im Regressionsmodell.

So interpretieren Sie die einzelnen Zahlen in diesem Abschnitt:
Die Koeffizienten geben uns die Zahlen an, die zum Schreiben der geschätzten Regressionsgleichung erforderlich sind:
y hat = b 0 + b 1 x 1 + b 2 x 2.
In diesem Beispiel lautet die geschätzte Regressionsgleichung:
final exam score = 66.99 + 1.299(Study Hours) + 1.117(Prep Exams)
Jeder einzelne Koeffizient wird als durchschnittliche Zunahme der Antwortvariablen für jede Einheitszunahme einer gegebenen Prädiktorvariablen interpretiert, unter der Annahme, dass alle anderen Prädiktorvariablen konstant gehalten werden. Beispielsweise beträgt für jede weitere untersuchte Stunde die durchschnittliche erwartete Erhöhung der Punktzahl für die Abschlussprüfung 1,299 Punkte, vorausgesetzt, die Anzahl der vorbereiteten Prüfungen wird konstant gehalten.
Der Abschnitt wird als die erwartete durchschnittliche Punktzahl für die Abschlussprüfung eines Studenten interpretiert, der null Stunden studiert und keine Vorbereitungsprüfungen ablegt. In diesem Beispiel wird von einem Schüler erwartet, dass er 66,99 Punkte erzielt, wenn er null Stunden studiert und keine Vorbereitungsprüfungen ablegt. Seien Sie jedoch vorsichtig, wenn Sie den Achsenabschnitt einer Regressionsausgabe interpretieren, da dies nicht immer sinnvoll ist.
In einigen Fällen kann sich der Achsenabschnitt beispielsweise als negative Zahl herausstellen, die häufig keine offensichtliche Interpretation aufweist. Dies bedeutet nicht, dass das Modell falsch ist, sondern lediglich, dass der Abschnitt an sich nicht so interpretiert werden sollte, dass er etwas bedeutet.
Der Standardfehler ist ein Maß für die Unsicherheit um die Schätzung des Koeffizienten für jede Variable.
Der t-stat ist einfach der Koeffizient geteilt durch den Standardfehler. Beispielsweise beträgt der t-stat für die hours studied 1,299 / 0,417 = 3,117.
Die nächste Spalte zeigt den p-Wert, der dem t-stat zugeordnet ist. Diese Zahl gibt an, ob eine bestimmte Antwortvariable im Modell von Bedeutung ist. In diesem Beispiel sehen wir, dass der p-Wert für die Studienstunden 0,012 und der p-Wert für prep exams 0,304 beträgt. Dies weist darauf hin, dass die hours studied ein signifikanter Prädiktor für das Ergebnis der Abschlussprüfung sind, die prep exams jedoch nicht.
Die letzten beiden Spalten in der Tabelle enthalten die Unter- und Obergrenze für ein 95%-Konfidenzintervall für die Koeffizientenschätzungen.
Beispielsweise beträgt die Koeffizientenschätzung für die hours studied 1,299, es besteht jedoch eine gewisse Unsicherheit hinsichtlich dieser Schätzung. Wir können nie sicher wissen, ob dies der genaue Koeffizient ist. Ein 95%-Konfidenzintervall gibt uns also einen Bereich wahrscheinlicher Werte für den wahren Koeffizienten.
In diesem Fall beträgt das 95%-Konfidenzintervall für die hours studied (0,356, 2,24). Beachten Sie, dass dieses Konfidenzintervall nicht die Zahl „0“ enthält. Dies bedeutet, dass wir ziemlich sicher sind, dass der wahre Wert für den Koeffizienten der hours studied ungleich Null ist,d.h.eine positive Zahl.
Im Gegensatz dazu ist der 95% Konfidenzintervall für prep exams (-1,201, 3,436). Beachten Sie, dass dieser Konfidenzintervall enthält die Zahl „0“, was bedeutet, dass der wahre Wert für die Koeffizienten von prep exams Null sein könnte,d.h.nicht signifikant in Abschlussprüfung Partituren vorherzuzusagen.
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …