
Das Resampling von Zeitreihendaten bedeutet, die Daten für einen neuen Zeitraum zusammenzufassen oder zu aggregieren.
Wir können die folgende grundlegende Syntax verwenden, um Zeitreihendaten in Python neu abzutasten:
#Finde die …Der gleitende Durchschnitt ist einfach der Mittelwert einer bestimmten Anzahl vorheriger Perioden in einer Zeitreihe.
Um den rollierenden Mittelwert für eine oder mehrere Spalten in einem Pandas DataFrame zu berechnen, können wir die folgende Syntax verwenden:
df['column_name'].rolling(rolling_window).mean()
Dieses Tutorial enthält einige Beispiele für die praktische Verwendung dieser Funktion.
Angenommen, wir haben die folgenden Pandas DataFrame:
import numpy as np
import pandas as pd
#Machen Sie dieses Beispiel reproduzierbar
np.random.seed(0)
# Datensatz erstellen
period = np.arange(1, 101, 1)
leads = np.random.uniform(1, 20, 100)
sales = 60 + 2*period + np.random.normal(loc=0, scale=.5*period, size=100)
df = pd.DataFrame({'period': period, 'leads': leads, 'sales': sales})
# die ersten 10 Zeilen anzeigen
df.head(10)
period leads sales
0 1 11.427457 61.417425
1 2 14.588598 64.900826
2 3 12.452504 66.698494
3 4 11.352780 64.927513
4 5 9.049441 73.720630
5 6 13.271988 77.687668
6 7 9.314157 78.125728
7 8 17.943687 75.280301
8 9 19.309592 73.181613
9 10 8.285389 85.272259
Wir können die folgende Syntax verwenden, um eine neue Spalte zu erstellen, die den fortlaufenden Mittelwert von 'Umsatz' für die letzten 5 Perioden enthält:
#Finden Sie den gleitenden Mittelwert der letzten 5 Verkaufsperioden
df['rolling_sales_5'] = df['sales'].rolling(5).mean()
# die ersten 10 Zeilen anzeigen
df.head(10)
period leads sales rolling_sales_5
0 1 11.427457 61.417425 NaN
1 2 14.588598 64.900826 NaN
2 3 12.452504 66.698494 NaN
3 4 11.352780 64.927513 NaN
4 5 9.049441 73.720630 66.332978
5 6 13.271988 77.687668 69.587026
6 7 9.314157 78.125728 72.232007
7 8 17.943687 75.280301 73.948368
8 9 19.309592 73.181613 75.599188
9 10 8.285389 85.272259 77.909514
Wir können manuell überprüfen, ob der für Periode 5 angezeigte rollierende Durchschnittsumsatz der Mittelwert der vorherigen 5 Perioden ist:
Rollmittelwert in Periode 5: (61,417 + 64,900 + 66,698 + 64,927 + 73,720) / 5 = 66,33
Wir können eine ähnliche Syntax verwenden, um den rollierenden Mittelwert mehrerer Spalten zu berechnen:
#Finden Sie den rollierenden Mittelwert der vorherigen 5 Ableitungsperioden
df['rolling_leads_5'] = df['leads'].rolling(5).mean()
#Finden Sie den rollierenden Mittelwert der vorherigen 5 Ableitungsperioden
df['rolling_sales_5'] = df['sales'].rolling(5).mean()
# die ersten 10 Zeilen anzeigen
df.head(10)
period leads sales rolling_sales_5 rolling_leads_5
0 1 11.427457 61.417425 NaN NaN
1 2 14.588598 64.900826 NaN NaN
2 3 12.452504 66.698494 NaN NaN
3 4 11.352780 64.927513 NaN NaN
4 5 9.049441 73.720630 66.332978 11.774156
5 6 13.271988 77.687668 69.587026 12.143062
6 7 9.314157 78.125728 72.232007 11.088174
7 8 17.943687 75.280301 73.948368 12.186411
8 9 19.309592 73.181613 75.599188 13.777773
9 10 8.285389 85.272259 77.909514 13.624963
Mit Matplotlib können wir auch ein schnelles Liniendiagramm erstellen, um die Rohverkäufe im Vergleich zum rollierenden Mittelwert der Verkäufe zu visualisieren:
import matplotlib.pyplot as plt
plt.plot(df['rolling_sales_5'], label='Rolling Mean')
plt.plot(df['sales'], label='Raw Data')
plt.legend()
plt.ylabel('Sales')
plt.xlabel('Period')
plt.show()
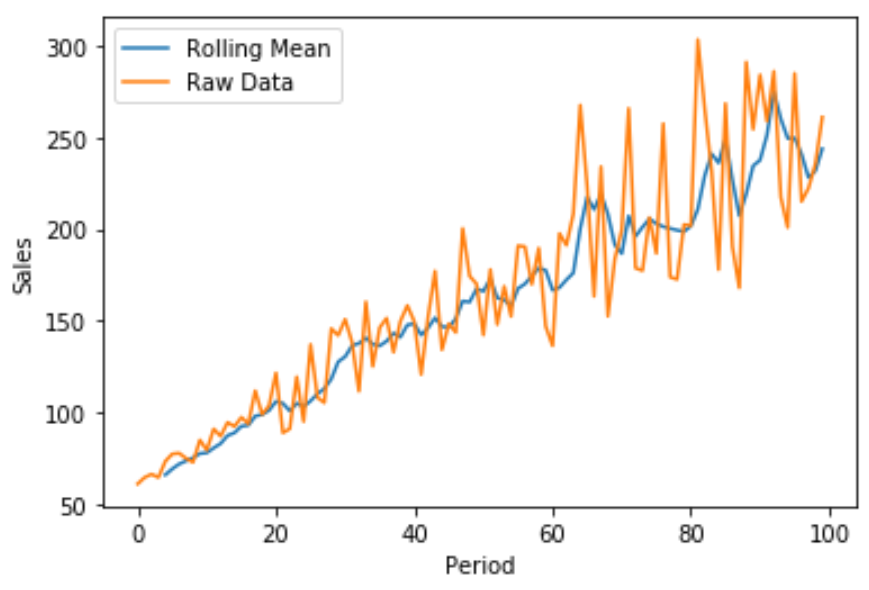
Die blaue Linie zeigt den 5-Perioden-Mittelwert des Umsatzes und die orange Linie zeigt die Rohverkaufsdaten.
Berechnen der Rollkorrelation in Pandas
So berechnen Sie den Mittelwert von Spalten in Pandas
Das Resampling von Zeitreihendaten bedeutet, die Daten für einen neuen Zeitraum zusammenzufassen oder zu aggregieren.
Wir können die folgende grundlegende Syntax verwenden, um Zeitreihendaten in Python neu abzutasten:
#Finde die …Ein rollierender Median ist der Median einer bestimmten Anzahl früherer Perioden in einer Zeitreihe.
Um den gleitenden Median für eine Spalte in einem Pandas DataFrame zu berechnen, können wir die …