
Der einfachste Weg, Arrays in Python zu verketten, ist die Verwendung der Funktion numpy.concatenate, die die folgende Syntax verwendet:
numpy.concatenate((a1, a2, ….), axis = 0)
wo:
- a1, a2 …: Die …
Die gewichtete Standardabweichung ist eine nützliche Methode, um die Streuung von Werten in einem Datensatz zu messen, wenn einige Werte im Datensatz höhere Gewichtungen als andere haben.
Die Formel zur Berechnung einer gewichteten Standardabweichung lautet:
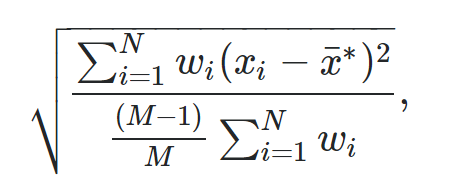
wo:
Der einfachste Weg, eine gewichtete Standardabweichung in Python zu berechnen, ist die Verwendung der Funktion DescrStatsW() aus dem Paket statsmodels:
DescrStatsW(values, weights=weights, ddof=1).std
Das folgende Beispiel zeigt, wie Sie diese Funktion in der Praxis verwenden.
Angenommen, wir haben das folgende Array von Datenwerten und entsprechenden Gewichtungen:
#Datenwerte definieren
values = [14, 19, 22, 25, 29, 31, 31, 38, 40, 41]
#gewichte definieren
weights = [1, 1, 1.5, 2, 2, 1.5, 1, 2, 3, 2]
Der folgende Code zeigt, wie die gewichtete Standardabweichung für dieses Array von Datenwerten berechnet wird:
from statsmodels.stats.weightstats import DescrStatsW
#Gewichtete Standardabweichung berechnen
DescrStatsW(values, weights=weights, ddof=1).std
8.570050878426773
Die gewichtete Standardabweichung ergibt sich zu 8,57.
Beachten Sie, dass wir auch var verwenden können, um die gewichtete Varianz schnell zu berechnen:
from statsmodels.stats.weightstats import DescrStatsW
#Gewichtete Varianz berechnen
DescrStatsW(values, weights=weights, ddof=1).var
73.44577205882352
Die gewichtete Varianz ergibt sich zu 73,446.
Die folgenden Tutorials erläutern, wie die gewichtete Standardabweichung in anderer Statistiksoftware berechnet wird:
Der einfachste Weg, Arrays in Python zu verketten, ist die Verwendung der Funktion numpy.concatenate, die die folgende Syntax verwendet:
numpy.concatenate((a1, a2, ….), axis = 0)
wo:
Häufig möchten Sie möglicherweise nur die Anzahl der Zeilen in einem pandas-DataFrame zählen, die bestimmte Kriterien erfüllen.
Glücklicherweise ist dies mit der folgenden grundlegenden Syntax einfach zu bewerkstelligen:
sum(df …