
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Beim globalen F-Tests (auch Overall-F-Test oder F-Test auf Gesamtsignifikanz eines Modells) wird geprüft, ob mindestens eine erklärende Variable einen Erklärungsgehalt für das Modell liefert und das Modell somit als Gesamtes signifikant ist (siehe auch Wikipedia).
In diesem Tutorial wird erläutert, wie Sie die F-Statistik in der Ausgabe einer Regressionstabelle identifizieren und wie Sie diese Statistik und ihren entsprechenden p-Wert interpretieren.
Der F-Test von Gesamtsignifikanz bei der Regression ist ein Test, ob Ihr lineares Regressionsmodell besser zu einem Datensatz passt als ein Modell ohne Prädiktorvariablen.
Der F-Test auf Gesamtsignifikanz hat die folgenden zwei Hypothesen:
Nullhypothese (H 0 ): Das Modell ohne Prädiktorvariablen (auch als Nur-Intercept-Modell bezeichnet ) passt sowohl zu den Daten als auch zu Ihrem Regressionsmodell.
Alternative Hypothese (H A ): Ihr Regressionsmodell passt besser zu den Daten als das Nur-Intercept-Modell.
Wenn Sie ein Regressionsmodell an einen Datensatz anpassen, erhalten Sie als Ausgabe eine Regressionstabelle, in der die F-Statistik zusammen mit dem entsprechenden p-Wert für diese F-Statistik angezeigt wird.
Wenn der p-Wert unter dem von Ihnen gewählten Signifikanzniveau liegt (allgemeine Auswahlmöglichkeiten sind .01, .05 und .10), haben Sie genügend Beweise, um zu dem Schluss zu kommen, dass Ihr Regressionsmodell besser zu den Daten passt als nur zum Intercept Modell.
Angenommen, wir haben den folgenden Datensatz, der die Gesamtzahl der untersuchten Stunden, die Gesamtzahl der absolvierten Vorbereitungsprüfungen und die Punktzahl der Abschlussprüfung für 12 verschiedene Schüler zeigt:
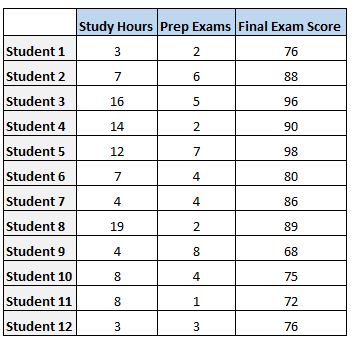
Um die Beziehung zwischen den untersuchten Stunden und den vorbereiteten Prüfungen mit dem endgültigen Prüfungsergebnis eines Schülers zu analysieren, führen wir eine multiple lineare Regression durch, wobei die untersuchten hours und prep exams als Prädiktorvariablen und das final exam score als Antwortvariable verwendet werden.
Wir erhalten folgende Ausgabe:
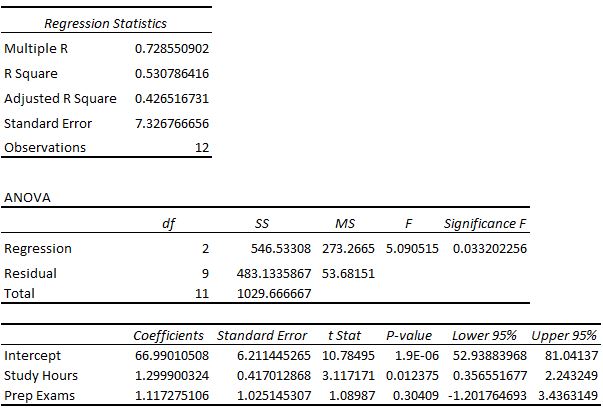
Aus diesen Ergebnissen konzentrieren wir uns auf die in der ANOVA-Tabelle angegebene F-Statistik sowie auf den p-Wert dieser F-Statistik, die in der Tabelle als Significance F bezeichnet ist. Wir werden 0,05 als unser Signifikanzniveau wählen.
F-Statistik: 5.090515
P-Wert: 0,0332
Technischer Hinweis: Die F-Statistik wird als MS-Regression geteilt durch MS-Residuum berechnet. In diesem Fall MS-Regression / MS-Residuum = 273,2665 / 53,68151 = 5,090515.
Da der p-Wert kleiner als das Signifikanzniveau ist, können wir schließen, dass unser Regressionsmodell besser zu den Daten passt als das Intercept-Only-Modell.
Im Zusammenhang mit diesem speziellen Problem bedeutet dies, dass wir mithilfe unserer Prädiktorvariablen hours studied und prep exams im Modell die Daten besser anpassen können, als wenn wir sie weggelassen und einfach das Intercept-Only-Modell verwendet hätten.
Wenn keine Ihrer Prädiktorvariablen statistisch signifikant ist, ist der F-Test auf Gesamtsignifikanz auch nicht statistisch signifikant. Es ist jedoch gelegentlich möglich, dass dies nicht zutrifft, da der F-Test auf Gesamtsignifikanz prüft, ob alle Prädiktorvariablen gemeinsam signifikant sind, während der T-Test der Signifikanz für jede einzelne Prädiktorvariable lediglich testet, ob jede Prädiktorvariable ist individuell bedeutsam.
Somit bestimmt der F-Test, ob alle Prädiktorvariablen gemeinsam signifikant sind oder nicht. Es ist möglich, dass jede Prädiktorvariable nicht signifikant ist, und dennoch besagt der F-Test, dass alle kombinierten Prädiktorvariablen gemeinsam signifikant sind.
Technischer Hinweis: Je mehr Prädiktorvariablen Sie im Modell haben, desto höher ist im Allgemeinen die Wahrscheinlichkeit, dass die F-Statistik und der entsprechende p-Wert statistisch signifikant sind.
Eine andere Metrik, die Sie wahrscheinlich in der Ausgabe einer Regression sehen werden, ist das R-Quadrat, das die Stärke der linearen Beziehung zwischen den Prädiktorvariablen und der Antwortvariablen misst. Obwohl R-Quadrat Ihnen eine Vorstellung davon geben kann, wie stark die Prädiktorvariablen mit der Antwortvariablen verknüpft sind, bietet es keinen formalen statistischen Test für diese Beziehung.
Aus diesem Grund ist der F-Test nützlich, da es sich um einen formalen statistischen Test handelt. Wenn der gesamte F-Test signifikant ist, können Sie außerdem schließen, dass das R-Quadrat nicht gleich Null ist und dass die Korrelation zwischen der / den Prädiktorvariablen und der Antwortvariablen statistisch signifikant ist.
Weiterführende Literatur Lesen und Interpretieren einer Regressionstabelle
Grundlegendes zum Standardfehler der Regression
Was ist ein guter R-Quadrat-Wert?
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …